第2回 Webの仕組みとWebサーバの構造
本格的なWebサイトを立ち上げるなら、インターネットの基幹技術およびWebサーバの動作や仕組みを理解しておく必要がある。そこで、名前解決やURLの処理方法からWebサーバの仮想ディレクトリ、MIMEまで、ここで基礎的な知識を再確認しておこう。
第1回でApacheの特徴について紹介したところ、思いのほか多くの方に見ていただいたと聞き、Apacheへの注目度の高さを再認識している。本来ならば、ここでインストール方法や設定方法、開発手法などを紹介するところなのだが、それは少しの間お待ちいただきたく思う。そうした話よりも先に、それらの知識の基礎となる部分を再確認しておきたいからだ。
上級者にとっては、既知の内容となるかもしれないが、今回はご容赦いただきたい。
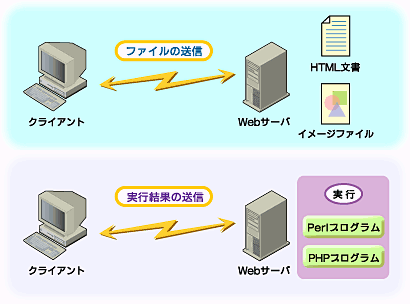
前回の内容の繰り返しとなるが、Webサーバの基本的な動作は、大きく分けて2種類しか存在しない。Webブラウザから要求されたファイルを返すか、要求されたプログラムを実行して、その結果を返すかのどちらかである(図1)。そう考えれば、すごく単純なソフトウェアなのだが、当然それだけで済まされない。
|
| 図1 標準的なWebサーバの動作 |
なぜ、“http://www.atmarkit.co.jp/”といったURLでサーバにアクセスできるのか。URLを受け取ったサーバは、URLをどのようにして解釈しているのか。Webブラウザは、サーバから受け取ったファイルを、どうやって表示しているのか。
Webサーバを構築し、管理しようとするならば、最低限この程度の知識が必要になる。もしも、もっと大規模で世界中からアクセスされるようなサーバであれば、これ以上の知識を要求されるのだ。高度な知識は必要に応じて徐々に学んでいけばよいとしても、最低限の知識は身に付けておきたい。
このセクションは、インターネットの大前提について述べる。TCP/IPとIPアドレスについて、すでに十分な知識のある方は、このセクションを読み飛ばしていただいて構わない。ここのテーマは、「インターネット上の無数に存在するサーバから、1つを特定してアクセスできるのはなぜか」である。
■サーバの特定(IPアドレス)
コンピュータ同士が通信する際には、“プロトコル”と呼ばれる通信手段を決定し、お互いに同じプロトコルを使わなくてはならない。これは、人間同士が会話するときに、同じ言語(日本語や英語など)を使うのと類似している。プロトコルには、さまざまな種類が存在するのだが、インターネット上では“TCP/IP”というプロトコルを利用する。
TCP/IPでは、ネットワーク上の各コンピュータに固有のIPアドレスと呼ばれる32bits(4bytes)の識別子を割り当てる。TCP/IPを使った通信は、相手のIPアドレスを指定することで、間違ったあて先に届かないようになっているのである。これは、郵便物に住所を記すことで、目的の相手に届けてもらえるのに類似している(図2)。
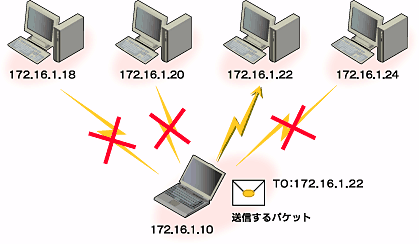 |
| 図2 あて先はIPアドレスで指定される |
もうお分かりいただけたと思うが、インターネット上に存在する無数のサーバから、1つを特定するためにはIPアドレスが用いられているのである。日ごろあまり意識したことのない方もいるかもしれないが、インターネットにアクセスできるということは、皆さんのコンピュータにも必ずIPアドレスが割り当てられている。自分で割り当てた覚えがなくとも、プロバイダにダイヤルアップしたときや、会社内のLANに接続したときに割り当てられているのである。
IPアドレスを自動的に割り当てる技術をDHCP(Dynamic Host Configuration Protocol)というが、このほかにもTCP/IPに関連する技術はたくさん存在する。それをここで解説しはじめるときりがないから、興味のある方は補足1で紹介した記事を参考にしていただきたい。ここでは、サーバの特定にIPアドレスが用いられ、それを使ってサーバにアクセスすることを知っておいてほしい。
| 補足 TCP/IPについては、Windows 2000 Insiderに掲載されている「詳説TCP/IPプロトコル」や、堀田 倫英氏のサイト「ネットワーク管理者(の卵)養成講座」(http://www.net-newbie.com/)などを参考にすると役立つであろう。 |
■URLがサーバに届くまで(DNS)
それでは、“http://www.atmarkit.co.jp/”というURLで、@ITのサーバにアクセスできるのはなぜかを考えてみよう。先ほど解説したとおり、インターネット上のサーバを特定するにはIPアドレスが用いられるはずである。しかし、“www.atmarkit.co.jp”のIPアドレス“211.2.252.66”は、URLのどこにも記述していない。
そもそも、IPアドレスを知らないのが普通なのだから、URLに記述されていないのは当然であろう。むしろ、IPアドレスをいちいち指定していたのでは都合が悪いからこそ、今日のようにホスト名とドメイン名(URL)でアクセスできるようになったのである。そして、この仕組みを支えているのが、DNS(Domain Name System)と呼ばれる技術なのだ。
DNSは、“www.atmarkit.co.jp”のようなホスト名とドメイン名を、IPアドレスに変換するための一覧表を管理している。いわば、インターネット上の電話帳のような役割を果たしているわけだ。だからといって、1つのDNSサーバが世界中のサーバのIPアドレスを管理しているわけではなく、多数のDNSサーバが木構造を成して分散管理している(図3)。
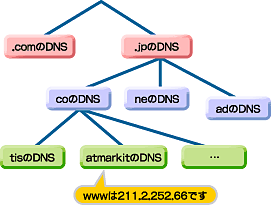 |
| 図3 DNSの木構造 |
DNSの仕組みを知ることは、インターネット技術の基礎を知るうえで重要な要素だし、それ自体が興味深い技術だ。しかし、ここで詳細に解説していると、Apacheの話題からは外れてしまうから割愛する。
本連載の内容を理解するうえで知っておいていただきたいのは、
以上の3点である。もしも、これらの意味が分からない場合は、Linux Squareに掲載されている「BINDで作るDNSサーバ」などを参考にしていただきたい。DNSの仕組みについてはこれ以外にもインターネット上に多数掲載されている。それらも併せて活用していただけば、数時間もかからずにDNSを理解できるはずだ。
■IPアドレスだけでは動かない(PORT)
何はともあれ、インターネット上のサーバは、IPアドレスを使って特定されることを理解していただけたと思う。しかし、それだけではまだクライアントとサーバの通信について、十分に知識を得たとはいえない。なぜならば、IPアドレスでサーバを特定しても、それだけではサーバ上のプログラムまで特定できないからである。
考えてみていただきたいのだが、皆さんがいま使っているコンピュータの中で、TCP/IPを使って通信するアプリケーションは幾つあるだろうか。著名なものだけ考えても、telnet、FTP、POP3(Mail)などが挙げられるし、Outlookやノーツのようなグループウェアも使われているかもしれない。ネットワーク対戦型のゲームや、インスタントメッセンジャーも使われているのではないだろうか。
普段意識することはないと思うが、こうしたアプリケーションがサーバと通信する場合、ネットワークを通じてやりとりしたデータを、正しいアプリケーションに導いてやらなければならないのである。例えば、電子メール(POP3)の通信パケットをFTPクライアントに渡してしまったらエラーになるだろうし、ゲームの通信パケットをWebブラウザに渡されてはゲームが継続できなくなるだろう。ここでは、クライアントとして使っているアプリケーションを例に挙げたが、これはサーバ側においてもまったく同じことがいえる。
こうしたミスが起こらないよう、TCP/IPを使って通信を受信するサーバは、アプリケーションごとに「ポート」と呼ばれる番号を割り当てる。通信を送信するクライアント側では、サーバのIPアドレスとともに、アプリケーションのポート番号も指定する。そうすることで、クライアントからの通信は、その内容に応じたアプリケーションに渡されるようになるのだ(図4)。
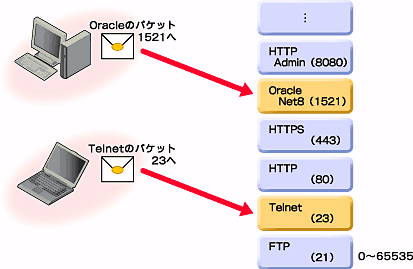 |
| 図4 サーバで使われている各種ポート |
例えるなら、IPアドレスはマンションの住所を示すもので、ポート番号はその部屋番号を示すものといえるのである。ちなみに、サーバ1つ当たりのポートの数(部屋の数)は、0番から65535番までの65536個存在する。複数のアプリケーションに同じ番号を割り当てさえしなければ、この範囲内で自由にポート番号を割り当てることができるから、通常は不足することなどあり得ない。
| ■コラム ウェルノウンポート(well-known port)とは |
|
TCP/IPで利用できるポート番号のうち、広く一般に使われるアプリケーションで利用するために、あらかじめ割り当てが決まっているポート。FTPの21、telnetの23、HTTPの80、HTTPSの443など。0〜65535番まであるポート番号のうち、0〜1023まではIANA(Internet Assigned Numbers Authority)という組織によって管理されていて、利用するためにはroot権限が必要になる。 本文中では、1024番以降は自由に使えると説明したが、実際には49151番まで予約済みポートとして使われている(すべてではない)。この中にはめったに使わないアプリケーションもたくさんあるから、あまり過敏になる必要はないが、自分のサーバで使われていないことは確認する必要がある。ウェルノウンポートや予約済みポートについては、IANAのホームページ(http://www.iana.org/)や、インターネット上で公開されている文書を参照していただきたい。 |
しかし、いくら自由だからといっても、サーバごとに好き勝手に設定するわけにはいかない。広く一般に用いられるアプリケーションにもかかわらず、ポート番号がサーバごとに違っていたのでは、利用する側がいちいち意識しなくてはならなくなり、利便性を大きく損なってしまうからだ。例えば、Webサーバのポート番号がサイトごとに違っていたら、アクセスするサイトごとにポート番号を指定しなくてはいけなくなってしまう。
そうしたことが起こらないよう、広く一般に使われるアプリケーションについては、どのサーバでも同じポート番号を指定しなくてはならない。その番号を決定するガイドラインともいえるのが「ウェルノウンポート」(コラム:「ウェルノウンポートとは」参照)で、0から1023番までのポートを特別なポートに位置付け、一般的なアプリケーションが使うポート番号を指定している。逆にいえば、このガイドに従ってポート番号を決定しないと、一般からのアクセスを期待できないということになるのだ。
もちろん、セキュリティ上の理由などでポート番号を変更し、ポート番号を知らない人間はアクセスできないようにすることもあるだろう。そうした場合には、1024番以降のポート番号で、なおかつほかのアプリケーションが使っていない番号を指定すれば問題ない。Apacheの場合にも、管理者用のWebサイトなどを立ち上げるために、あえて別のポート番号を指定することもある(コラム:「ポート番号を指定する」参照)。
Apacheでは、1つのサーバ上で複数のポートを使ったサービスを起動できるようになっているから、こうした場合にWebサーバを複数台用意する必要はない。管理者用のサイトに限らず、社内向けのイントラネットなどでは、ポート番号を分けて複数のサービスを提供することも考えられるだろう。そのあたりの設定など、詳しいことは次回以降に説明するので、今回の内容と併せて参考にしていただきたい。
| ■コラム ポート番号を指定する |
|
本文中では、ポート番号の意味とサーバ側での使い分けを説明したが、クライアント側ではどのように使い分ければいいのだろうか。意外と知られていないのだが、Webブラウザの場合は、URLでポート番号を指定することができる。具体的には、「http://www.atmarkit.co.jp:80/」のように、ドメイン名の直後に「:」(コロン)で区切ってポート番号を指定する。 普段ポート番号を指定しなくてもサーバにアクセスできるのは、HTTPのウェルノウンポートは80と決まっているためで、「http://」から判断して、ブラウザが自動的に80番へとアクセスしているからである。ここで紹介したように、明示的にポート番号を指定した場合は、80番の代わりに指定したポートへとアクセスする。 従って、本文中で説明したようにサーバ側でポート番号を使い分けている場合は、利用したいサービスに合わせてポート番号を指定する。社員紹介ページは「http://172.16.1.10:6666/」、経費清算は「http://172.16.1.10:7070/」、在庫情報は「http://172.16.1.10:5555」といった具合だ。もちろん、これらを1つのポートでサービスすることもできるが、このように使い分けることで、アクセス権限の設定などの柔軟性を確保することが考えられる。 Webに限らず、ポート番号の考え方を理解していると何かと便利である。ここで理解した知識を生かし、さらに高度な使いこなしを学んでいただきたいと思う。 |
ずいぶん長くかかったが、これでようやくクライアントからのリクエストがサーバに届くまでの道筋を理解できたことになる。ここからは、サーバに届けられたリクエストがサーバの内部でどのように処理されるのかという点について、幾つかのポイントに分けて説明していく。どれをとってみても、ApacheをはじめとするWebサーバを設定するうえで欠かせない重要なポイントばかりだから、しっかりと理解しておいてほしい。
| 注:本稿において、特に規定のない用語についてはApacheの用語を用いている。例えば「インデックスファイル」は、Apacheで用いられる用語だから、別のソフトウェアでは「イニシャルファイル」と呼ばれているかもしれない。こうした用語の差異は、しばしば見られることだが、その都度読み替えて理解していただきたい。 |
■サーバに届いたURLの処理
まず初めのポイントは、インデックスファイルについてである。われわれは、どこかのサイトにアクセスする際、ファイル名を指定せずにアクセスすることが多い。つまり、「http://www.atmarkit.co.jp/」とURLを指定することはあっても、「http://www.atmarkit.co.jp/flinux/rensai/apache01/apache01.html」とファイル名までURLに指定することは少ない。
たとえ目的のページが決まっていたとしても、そのページのファイル名が分からないのだから、これは当然の行為だといえる。しかし、ファイルを返すサーバ側にしてみれば、ファイル名を省略されると、どのファイルを返せばよいのか判断に困ってしまうのも当然のことだ。そこで、ファイル名が省略された場合に返す、規定のファイルを指定するのがインデックスファイルである。
インデックスファイルには、慣習的に「index.html」や「index.htm」といったファイル名が指定されており、そのファイルを返すようになっている。試しに「http://www.atmarkit.co.jp/index.html」へとアクセスしてみてほしい。「http://www.atmarkit.co.jp/」でアクセスした場合と同様に、本サイトのホームページが表示されるはずだ(図5)。
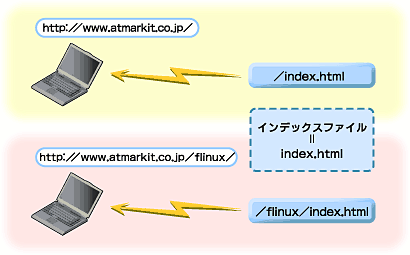 |
| 図5 インデックスファイルによるURLの補完 |
このように、ファイル名を省略したアクセスは「ディレクトリアクセス」と呼ばれ、Webサーバ上の仮想ディレクトリに直接アクセスすることを指す。「http://www.atmarkit.co.jp/」であれば、Webサーバ上の仮想ルートディレクトリにアクセスしているのである。また、「http://www.atmarkit.co.jp/flinux/」とすれば、本サイトのLinux Squareを管理するflinuxディレクトリに対し、ディレクトリアクセスしていることになるわけだ。
ここで紹介したインデックスファイルの設定はサイト全体で共通のものになるが、実際のファイルはディレクトリごとに必要となる。例えば、仮想ルートディレクトリには指定したファイルがあっても、flinuxディレクトリになければ、「http://www.atmarkit.co.jp/flinux/」でディレクトリアクセスすることはできない。このことからも、サイト上のディレクトリ構成と、ファイル構成が重要であると理解できる。
ところで、仮想ディレクトリとは、なんなのだろうか。
■仮想ディレクトリ
「http://www.atmarkit.co.jp/flinux/」の“flinux”は、Webサイト上のディレクトリ(Windows風にいえばフォルダ)である(補足2)。
いうまでもなく、Webサイトを構成するファイルはOSのファイルシステム上に配置される。しかし、すべてを同一のディレクトリに配置してしまうと、ファイルの数が多くなるほど管理しづらくなってしまう。そこで、ファイルの種類やサイトの構成に応じてディレクトリを分割し、ファイルを分散させるのである。こうしておけば、ファイルの管理も容易になるし、アクセスする側も分かりやすい。
それは当然なのだが、Webサイトを構成するディレクトリは、一体どこに作成すればいいのだろうか。1つのサイトを構成するディレクトリは、すべて同じディレクトリの配下に作成しなくてはならないのだろうか。その答えとなるポイントが、「仮想ディレクトリ」である。
仮想ディレクトリは、その名のとおり仮想的なディレクトリ構成を作成するために提供されている考え方、と説明できる。
サイトの構成やサーバの構成などによって、考え方はさまざまなのだが、少なくとも「仮想ルートディレクトリ」だけは必ず設定しなくてはならない。なぜならば、本当のルートディレクトリに対して、サイトのトップページのファイルを配置するわけにはいかないからである。これは、Windowsでいえば、“C:\”の直下にファイルを配置するようなものだ(図6)。
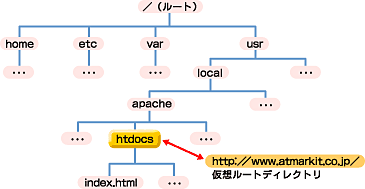 |
| 図6 実ディレクトリと仮想ディレクトリ |
そうした状況にならないよう、/usr/local/apache/htdocsなどに仮想ルートディレクトリ(Apacheではドキュメントルートと呼ばれる)を作成するわけだが、それ以下のディレクトリは仮想ディレクトリとして作成しなくても構わない(注)。仮想ルートディレクトリ以外は、実際のディレクトリを作成するだけで、URLを使ったアクセスができるようになるからである(図7)。
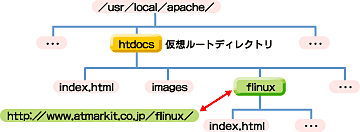 |
| 図7 Webサイトを構成するディレクトリ構造 |
従って、仮想ルートディレクトリ以外には仮想ディレクトリを作成しない例が多いのだが、仮想ディレクトリ(Apacheではエイリアスと呼ばれる)を作成するメリットも皆無ではない。
| 注:ただし、CGIプログラムを配置するディレクトリについてはこの限りでないので注意が必要。CGIプログラムを配置するディレクトリは、スクリプト・エイリアスとして、別途定義しなくてはならない。従って、CGIプログラムと静的なファイルを同じディレクトリに配置することはできないのである。 |
仮想ディレクトリを使うメリットの1つは、ファイルの物理的な配置やディレクトリ名称が変わっても、URLを変えずに済ませられる点である。WindowsのショートカットやUNIXのシンボリックリンクと同じで、再作成か設定変更が必要ではあるが、物理的な変更を使い勝手に影響させずに済む。ユーザーの中にはWebページをブックマークに登録している人もいるし、サイト内のアプリケーションでURLを指定しているかもしれないから、URLの変更を最低限に抑えることは重要だ。
詳しくは次回以降で紹介するが、Apacheではディレクトリごとに細かな設定を設けることができるし、仮想ディレクトリを作成するのも容易である。サイトの構築時にはサイト構成をしっかりと考えるようにし、実際の配置などは後で変更することだって難しくない。
■MIME type
こうして、クライアントの指定したURLがサーバに届けられ、サーバ上の該当するファイルがクライアントに返される(補足3)。しかし、ここでもまた、普段はあまり意識しない技術的なポイントを説明しなくてはならない。それが「MIME」(Multipart Internet Mail Extension)だ。
MIME typeは、「/」(スラッシュ)で区切られた2つの要素、ヘッダとボディから構成された文字列で表される。ヘッダはファイルの分類を表し、ボディはファイルの種類を表す、と考えれば間違いない。例えば、画像に用いられるJPEGファイルのMIME typeはimage/jpgで、HTMLファイルはtext/htmlとなる。
こうしたMIME typeの規定値は、RFC(Request for Comments)で定義されているが(MIME typeはRFC 2045)、それに従うかどうかはユーザーに任されている。サーバ側(Apache)では、ファイルの拡張子に関連付けるMIME typeを自由に定義できるし、クライアント側もMIME typeに関する動作を自由に定義できるからだ。
これが何かを一言で表すならば、「サーバがクライアントに送信した、ファイルの種類を示す識別子」となるだろう。サーバからファイルが送られてきても、それが文書(テキスト)なのか画像なのか、それともほかの何かなのか、判断できなければクライアントは適切な処理ができない。そこで、送信したファイルの種類について、簡単に伝えることができるMIME typeが登場することになったのである。
サーバは、自分が送信するファイルの拡張子を判断し、それに関連付けられたMIME typeをクライアントに送信する。クライアントは、それを受け取ってMIME typeに関連付けられた処理を行う。その処理とは、“Webブラウザで表示せよ”であったり、“別のアプリケーションを起動して表示せよ”であったりする(図8)。
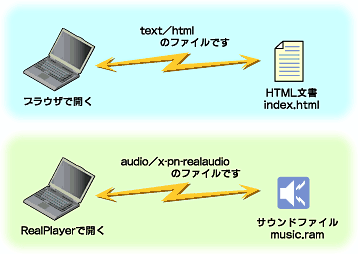 |
| 図8 MIME typeとブラウザの動作 |
Webを利用していて、ビデオ画像にアクセスすると別のアプリケーションが起動したり、音声ファイルにアクセスしたらまた別のアプリケーションが起動した経験がないだろうか。また、ファイルにあったプラグインがないからダウンロードするように、とメッセージが表示された経験はないだろうか。これらは、すべてMIME typeによって判断された動作だから、その設定を変えれば動作も変化するのである。
Apacheの設定でMIME typeを変更する方法は、次回以降に詳しく説明するが、ここではWindows 98やWindows 2000でMIME typeを変更する方法を紹介する。
ご存じのとおり、Internet ExplorerはいまやWindows OSの一部となっている。このため、MIME typeの設定もWindowsの一部となっていて、Internet Explorerを起動しなくても変更できるようになった。その変更はあちこちからできるのだが、エクスプローラやマイコンピュータの表示メニューから、「フォルダオプション」を選択するのが手っ取り早い。
そうして表示された画面から、「ファイルの種類」と書かれたタブを選択する。そこに表示されているのは、ファイルの拡張子に関連付けられたアプリケーションの一覧だ(画面1)。以前(Internet Explorerの登場前)のリストは、拡張子とアプリケーションだけで構成されていたのだが、いまではこのリストに内容の種類(MIME)という項目も追加されている。
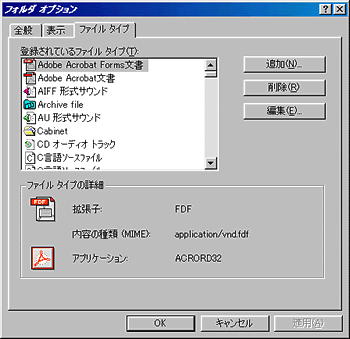 |
| 画面1 Windows 98のフォルダオプションダイアログボックス |
これ以上説明の必要もないと思うが、Internet ExplorerのMIME typeに対する動作や、ファイルの拡張子に対する動作の変更・追加はここで行う。ただInternet Explorerの場合、MIME typeを変更・追加しても、ファイルの拡張子を判断して意図しない動作をする。これもいうまでもないと思うが、Webアプリケーションを開発するときには、1種類のWebブラウザだけでなく、さまざまなWebブラウザでテストすることが肝要である。
これに対し、Netscape Communicatorの場合は、Netscape Communicatorを起動し、編集メニューの設定を開く。表示される画面のカテゴリから、Navigatorのアプリケーションを選択すると、右側に登録されているMIME typeと関連付けられたアプリケーションの一覧が表示される(画面2)。しかし、このリストも実は先に紹介したWindowsの設定を表示しているだけで、先の手順で変更しても同じである。
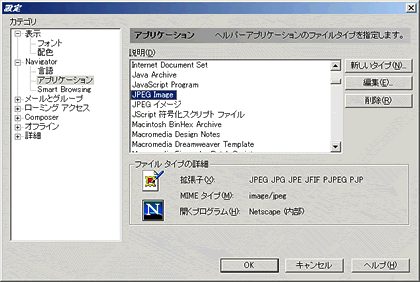 |
| 画面2 Netscape Navigator 4.7xの設定ダイアログボックス |
とにもかくにも、こうして表示されたリストを1つ1つ見ていくと、実にたくさんのMIME typeがあることが理解できると思う。中にはMIME typeの設定がない拡張子もあるが、それらにMIME typeを与えたり、独自に作成したアプリケーションの拡張子を設定することだってできる。そして、そのMIME typeをサーバ側に設定すれば、サーバとクライアントの同期が取れる。
例えば、Microsoft Office関連のアプリケーションに関するMIME typeを、サーバ側では通常設定していない。そこで、クライアント側に自動設定されているMIME type(application/vnd.ms-excelなど)を見て、サーバ側にも拡張子xlsのMIME typeとして設定する。そうすれば、サーバからXLSファイルを取得するとき、自動的にExcelが起動するようになるのだ。
先にも述べたとおり、Internet Explorerを使っている場合は、サーバ側で設定しなくても起動する可能性がある。しかし、Netscapeの場合は、そうならずにファイルを保存しようとするはずだ。このような自動起動のニーズは高いにもかかわらず、MIME typeに関する理解が浸透していないため、相談を受けることも多い。
ぜひ、一度MIME typeについて、いろいろと試してみていただきたい。特に企業内で用いられているイントラネットなどでは威力を発揮するだろうと思う。
| 補足2 WindowsやMacintoshしか知らない、という方にはなじみが薄いかもしれないが、UNIXやLinuxではディレクトリの区切りを「/」(スラッシュ)で表現する。これは、Windowsの「\」(エンサイン:バックスラッシュ)と同じもの、と考えていただけばよい。 |
| 補足3 サーバ上のファイルがプログラムであった場合は、そのプログラムの実行結果(通常はHTML)が返される。このようなページを「動的なWebページ」という。 |
さまざまな技術を一度に紹介しようと思うと、どうしてもすべてを伝えきれないが、本稿はあくまでもApacheについて解説することが趣旨となっているから仕方ない。そこはさまざまな情報源から補足していただきたく思う。
さて、次回はApacheのインストールについて解説する。Windowsのアプリケーションのようなわけにいかないのはもちろん、ApacheはLinux系のフリーソフトの中でも特にさまざまなインストールオプションを持つアプリケーションなのだ。インストールを解説したら、設定ファイルについて解説していくつもりである。
世紀を超えての連載となるが、どうか最後までお付き合いいただきたい。