●DRBDとは
参考URL:CentOS8でDRBD9を動かしてみる
DRBDは「Distributed Replicated Block Device」の略で、名前の通りデータをブロックデバイス単位でリアルタイムにレプリケートするためのソフトウエアです。
詳細については、上記URLを参照してください。
●設定のための準備
参考URL:CentOS8でDRBD9を動かしてみる
参考URL:DRBD9 と Pacemaker の構成
参考URL:CentOS7.4でDRBD8.4を構築してみた
DRBD構築するためのサーバは下記のとおりです。
「VMware Host Clientによる仮想共有ディスクファイルの作成方法」でコントローラの場所として、SCSIコントローラ1 SCSI (1:0)を設定済みです。
したがって、今回作成するDRBD用のディスクは各ホストでSCSI (1:1)としてあらかじめ作成しておきます。
●DRBDのインストール
ELRepoリポジトリを有効にしてDRBD9を両ホストにインストールします。SELinuxを無効にしておきます。
ファイアウォールを有効にしている場合、DRBDで使うファイアウォールのポートを空けます。
●DRBD用のディスクの用意
DRBD用のディスクは、各ホストで同容量のサイズで用意し、各ホストでパーティションを作成します。
DRDB用ディスクを2台目以降の物理ディスク上とする場合は、下記の操作となります。
ちなみに作成したVGを削除するには下記のようにします。
DRDB用ディスクを1台の物理ディスク上の新たなパーティションとして作成する場合は、下記の操作となります。
DRDB用ディスクはあらかじめfdiskコマンドで作成(今回は/dev/sda5)しておきます。
ちなみに作成したVGを削除するには下記のようにします。
●DRBDリソースの定義
/etc/drbd.d/r0.resを編集し、作成したLVを同期させるようにします。
●メタデータ作成及びDRBD起動
仮想ホストでDRDB構成する際、リソース有効化時に下記のようなエラーが出力される場合があります。
参考URL:よくある質問
参考URL:仮想マシンの UEFI セキュア ブートを有効または無効にする
リンク先を参照し下記の方法により解決しました。
各仮想マシンをパワーオフします。
VMware Host Clientにログインして仮想マシンを選択します。
[編集] をクリックします。
[設定の編集] ウィンドウで、[仮想マシンオプション] をクリックします。
[起動オプション] の左側の▶をクリックし、ファームウェアが [EFI] に設定されていることを確認します。
[UEFIセキュア ブートの有効化] チェック ボックスを外し、[OK] をクリックします。
また、過去にDRBDを作成している場合、下記のようなエラーが表示されることがあります。
メタデータを作成し、DRBDリソースを初期化し有効にします。
各ホストはsecondaryとして起動します。
●DRBD同期開始
初期化のためcentos8-str1側をプライマリに昇格させ、ファイルシステムを作成します。
「--force」オプションを付けると、DRBDのストレージの初期同期が開始され、centos8-str1からcentos8-str2にストレージの内容がコピーされます。
●DRBDの停止
セカンダリを先に停止します。
●DRBDデバイスをプライマリホストで使ってみます
DRBDデバイスができたところで、lsblk(list block devices)の内容を確認します。
※「lsblk」(list block devices)は、現在利用できるブロックデバイスを一覧表示するコマンドです。
●セカンダリホストを昇格しマウントしてみます
centos8-str1でDRBDデバイスをアンマウントし、セカンダリに降格させます。
●DRBD9の新機能について
自動プロモーション機能を使って、プライマリ・セカンダリの切り替え状況を確認します。
まず、両サーバをセカンダリに降格させます。
●DRBDの自動起動設定
OS起動時にDRBDが起動するように設定します。
●自動プロモーション
DRBD9は自動プロモーションが有効になっています。
mount操作を実行すると自動的にPrimaryに昇格され、umountで自動的にSecondaryに降格されます。
再度、有効にするにはDRBDを再起動する必要があります。
●DRBDをpacemakerの現在のリソースに追加する
参考URL:ディスクHAクラスタ化(Pacemaker+Corosync+pcs+DRBD)
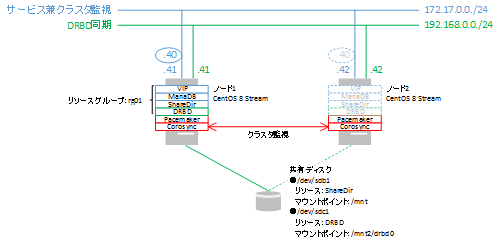
既に構築されているPacemaker(「クラスターの起動(Centos8 Stream向け)」)にDRBDデバイス上のファイルシステムを管理する設定を追加します。
クラスタのプロパティは下記を設定済みです。
この対策のため、自動フェールバックを無効とした方が良いでしょう。(Warningは無視します)。
現在のPacemakerの設定は下記のとおりです。
●DRBDのクラスタ状態を確認
マウント状態を確認します。
設定状態を確認します。
●フェールオーバーの確認
ノードcentos8-str1をスタンバイ状態にし、強制的にフェールオーバーさせます。
マウント先ディレクトリ内のファイルも存在しています。
●フェールバックの確認
centos8-str2をスタンバイ状態にする前に、DRBDデバイス上にファイルを作成します。
centos8-str1側でもクラスタの状態を確認します。
●NIC障害
現在のクラスタ状態は、centos8-str1がセカンダリ、centos8-str2がプライマリです。
擬似NIC障害を故意におこしDRBDの状態変移及び修復方法を確認します。
VMware Host Clientにログインし、centos8-str2のInterconnect側のチェックを外します。
この状態のままcentos8-str2をスタンバイとし、centos8-str1をプライマリに切り替えます。
VMware Host Clientにログインし、先ほど切断したcentos8-str2のInterconnect側のチェックを入れ、接続できるようにします。
これを解消するため下記のように実施します。
逆に言えば、DRBDリソース用のNICの一方が故障中は自動手動に関わらずプライマリ・セカンダリが入れ替わるとこのような状況に陥ると言うことが分かりました。
●スプリットブレインからの復帰
参考URL:6.3. スプリットブレインからの手動回復
参考URL:作っておぼえるHAシステム4
DRBDのクラスタを構成しているサーバでスプリットブレインが検知されていました。
暫くしてからSecondary側で確認すると
最終的に正常な状態となりました。
●open(/dev/mapper/pool-data0) failed: No such file or directory
VMware ESXi(VMware vSpheer Hypervisor)のハードウェアを移行した影響のためか、VM上で構成していたDRBD(Pacemakerで管理)が動作しなくなりました。
DRBDモジュールが読み込まれているか確認します。
VM上の仮想ディスクは正常に認識されていますので、「●メタデータ作成及びDRBD起動」及び「●DRBD用のディスクの用意」を参照して作成し直します。
メタデータを再作成等の作業後、手動でDRBDを起動することができるようになりました。
しかしマウントすると下記のようなエラーが表示されます。
●カーネルアップデート後DRBDが起動しない
DRBDが動作していた時のカーネルリリース番号は 4.18.0-305.3.1.el8.x86_64 でした。
動作しなくなったカーネルリリース番号は下記のとおりです。
kernel-4.18.0-310.el8.x86_64
kernel-4.18.0-315.el8.x86_64
下記コマンドを実行してもエラーとなり、DRBDは起動しません。
DRBDモジュールの確認します。
この状態のため、最新のカーネルリリース番号で起動してもDRBDモジュールが読み込まれないことが分かりました。
いろいろ調べた結果、kmod-drbd90-9.0.29-1.el8.elrepo.x86_64にはkernel-devel-4.18.0-305.3.1.el8.x86_64が必要ということでした。
●カーネルアップデート後DRBDが起動しない(その2)
CentOS Stream 8での出来事です。
誤ってカーネル(4.18.0-305.3.1.el8.x86_64)をアップデート(4.18.0-348.7.1.el8_5.x86_64)してしまったためクラスタが動作しなくなってしまいました。
カーネルのバージョンにかかわらず、pcsのバージョンが0.10.11-2.el8、pcs-0.10.12-1.el8.x86_64、pcs-0.10.12-2.el8.x86_64では下記のエラーが発生します。
ただし、クラスタに組み込むと動作しなくなります(期待しているSlaveにならず「Stopped」のまま)。
アップグレードされた製品は下記のとおりです。
kernel関連の製品は、ダウングレードで対応可能なものはそのように対応し、必要に応じて削除、再インストールします。
その他の製品は元のkernelバージョン(4.18.0-305.3.1.el8.x86_64)で動作していた時のバージョンに一つ一つ戻します。
手動でDRBDの動作確認し、同期・プライマリへの移行・セカンダリへの移行は問題ありませんでした。
次に、クラスターに再度、組込んで動作確認しましたが、DRBD_r0-cloneが「Stopped」となり、これまでのようにSlaveになりませんでした。
(手動でのDRBDの動作確認及びクラスター再組込後の確認は何度も実施した。)
正常にクラスタが動作しないサーバの/var/log/pacemaker/pacemaker.logを確認したところ、下記のようなエラーがあることに気付きました。
drbd90-utils、drbd90-utils-sysvinit、kmod-drbd90を一度、削除、その後、再起動。再起動後、再インストール、再度再起動します。
これで「/dev/drbd0」が認識されました。手動でのDRBDの起動・同期・primaryへの移行・secondaryへの移行・停止は問題ありませんでした。
しかし、クラスターに組み込むと正常に動作しません。
現時点でのlsblk(list block devices)の内容を確認します。
再度、DRBD用のディスクを作成します。
問題が発生しているサーバ単体でクラスターをセットアップし、下記コマンドを実行したところエラーとなりました。
問題が発生しているサーバでは、該当製品はインストール(何度もインストールした)されているのですが、削除・再インストールします。
が、結局、クラスタでの制御が出来なくなってしまいました。
手も足も出ませんので、問題が発生しているサーバのカーネルを最新バージョン(2022年1月14日現在)にアップデートします。
しかし、クラスターでDRBDに関するリソースを追加しようすると、カーネルバージョンアップ前と同様のエラーとなりました。
pcsのバージョンを「0.10.11-1」までダウングレードします。
pcsをダウングレードしただけではクラスタは思ったとおり動作しませんでした。
drbd90-utils及びkmod-drbd90を削除・再インストールします。
すると、参照できなかった「ocf:linbit:drbd」を参照できるようになりました。
設定してクラスタを起動させますが、これまでと同じエラーとなり動作しませんでした。
●仮想サーバ上でblk_update_requestを検知
仮想サーバ上でDEBDを動作させているのですが、Zabbixより「blk_update_request」を検知したメールが飛んできました。
エラーを検知したサーバ上で確認します。
システムログも確認します。
正常な方のサーバ(centos8-str4)のログで「centos8-str3: conn( Connected -> Timeout ) peer( Secondary -> Unknown )」と記録されています。
原因は分かりませんが、何かしら問題が発生したようです。
centos8-str4がDRBDのマスターとなっており。centos8-str3をシャットダウンしても問題ないので、シャットダウンして回復するか確認します。
シャットダウンではなくcentos8-str3のクラスタの再起動、または、DRBDの再起動を実施することでも復旧したかもしれません。
参考URL:CentOS8でDRBD9を動かしてみる
DRBDは「Distributed Replicated Block Device」の略で、名前の通りデータをブロックデバイス単位でリアルタイムにレプリケートするためのソフトウエアです。
詳細については、上記URLを参照してください。
●設定のための準備
参考URL:CentOS8でDRBD9を動かしてみる
参考URL:DRBD9 と Pacemaker の構成
参考URL:CentOS7.4でDRBD8.4を構築してみた
DRBD構築するためのサーバは下記のとおりです。
| ホスト名 | IPアドレス | ディスク |
|---|---|---|
| centos8-str1 | 172.17.0.41 | /dev/sdb |
| centos8-str2 | 172.17.0.42 | /dev/sdb |
「VMware Host Clientによる仮想共有ディスクファイルの作成方法」でコントローラの場所として、SCSIコントローラ1 SCSI (1:0)を設定済みです。
したがって、今回作成するDRBD用のディスクは各ホストでSCSI (1:1)としてあらかじめ作成しておきます。
●DRBDのインストール
ELRepoリポジトリを有効にしてDRBD9を両ホストにインストールします。SELinuxを無効にしておきます。
# rpm --import https://www.elrepo.org/RPM-GPG-KEY-elrepo.org # To install ELRepo for RHEL-9: # dnf -y install https://www.elrepo.org/elrepo-release-9.el9.elrepo.noarch.rpm # dnf -y install drbd9x-utils kmod-drbd9x # To install ELRepo for RHEL-8: # dnf -y install https://www.elrepo.org/elrepo-release-8.el8.elrepo.noarch.rpm # dnf -y install -y drbd90-utils kmod-drbd90DRBDモジュールを有効化するため、ここで再起動します。
ファイアウォールを有効にしている場合、DRBDで使うファイアウォールのポートを空けます。
# firewall-cmd --add-port=6996-7800/tcp --permanent # firewall-cmd --reload
●DRBD用のディスクの用意
DRBD用のディスクは、各ホストで同容量のサイズで用意し、各ホストでパーティションを作成します。
DRDB用ディスクを2台目以降の物理ディスク上とする場合は、下記の操作となります。
[root@centos8-str1 ~]# parted /dev/sdb mklabel msdos 警告: いま存在している /dev/sdb のディスクラベルは破壊され、このディスクの全データが失われます。続行しますか? はい(Y)/Yes/いいえ(N)/No? Y 通知: 必要であれば /etc/fstab を更新するのを忘れないようにしてください。 [root@centos8-str1 ~]# parted /dev/sdb mkpart primary 0% 100% 通知: 必要であれば /etc/fstab を更新するのを忘れないようにしてください。 [root@centos8-str1 ~]# parted /dev/sdb set 1 lvm on 通知: 必要であれば /etc/fstab を更新するのを忘れないようにしてください。LVMをインストールしてPV、VGとLVを作成します
[root@centos8-str1 ~]# dnf install -y lvm2 [root@centos8-str1 ~]# pvcreate /dev/sdb1 WARNING: ext4 signature detected on /dev/sdb1 at offset 1080. Wipe it? [y/n]: y Wiping ext4 signature on /dev/sdb1. Physical volume "/dev/sdb1" successfully created. [root@centos8-str1 ~]# vgcreate pool /dev/sdb1 Volume group "pool" successfully created [root@centos8-str1 ~]# lvcreate -n data0 -l 100%FREE pool Logical volume "data0" created.
ちなみに作成したVGを削除するには下記のようにします。
# vgremove -f pool Logical volume "data0" successfully removed Volume group "pool" successfully removedDRDB用ディスクを2台目以降の物理ディスク上の作業はここまでです。
DRDB用ディスクを1台の物理ディスク上の新たなパーティションとして作成する場合は、下記の操作となります。
DRDB用ディスクはあらかじめfdiskコマンドで作成(今回は/dev/sda5)しておきます。
コマンド (m でヘルプ): n パーティション番号 (5-128, 既定値 5): 最初のセクタ (1847597056-1952448478, 既定値 1847597056): 最終セクタ, +セクタ番号 または +サイズ{K,M,G,T,P} (1847597056-1952448478, 既定値 1952448478): 新しいパーティション 5 をタイプ Linux filesystem、サイズ 50 GiB で作成しました。 コマンド (m でヘルプ): p ディスク /dev/sda: 931 GiB, 999653638144 バイト, 1952448512 セクタ 単位: セクタ (1 * 512 = 512 バイト) セクタサイズ (論理 / 物理): 512 バイト / 512 バイト I/O サイズ (最小 / 推奨): 65536 バイト / 65536 バイト ディスクラベルのタイプ: gpt ディスク識別子: 65E8FDD2-9112-4983-A437-54D32008F1B2 デバイス 開始位置 終了位置 セクタ サイズ タイプ /dev/sda1 2048 1230847 1228800 600M EFI システム /dev/sda2 1230848 3327999 2097152 1G Linux ファイルシステム /dev/sda3 3328000 35973119 32645120 15.6G Linux スワップ /dev/sda4 35973120 1847597055 1811623936 863.9G Linux ファイルシステム /dev/sda5 1847597056 1952448478 104851423 50G Linux ファイルシステム コマンド (m でヘルプ): w パーティション情報が変更されました。 ディスクを同期しています。 コマンド (m でヘルプ): qLVMをインストールしてPV、VGとLVを作成します
[root@centos8-str1 ~]# dnf install -y lvm2 [root@centos8-str1 ~]# pvcreate /dev/sda5 WARNING: ext4 signature detected on /dev/sdb1 at offset 1080. Wipe it? [y/n]: y Wiping ext4 signature on /dev/sdb1. Physical volume "/dev/sdb1" successfully created. [root@centos8-str1 ~]# vgcreate pool /dev/sdb1 Volume group "pool" successfully created [root@centos8-str1 ~]# lvcreate -n data0 -l 100%FREE pool Logical volume "data0" created.
ちなみに作成したVGを削除するには下記のようにします。
# vgremove -f pool Logical volume "data0" successfully removed Volume group "pool" successfully removedDRDB用ディスクを1台の物理ディスク上の新たなパーティションとして作成した場合の作業はここまでです。
●DRBDリソースの定義
/etc/drbd.d/r0.resを編集し、作成したLVを同期させるようにします。
# vi /etc/drbd.d/r0.res
resource r0 {
on centos8-str1 {
device /dev/drbd0;
disk /dev/mapper/pool-data0;
address 172.17.0.41:7789;
meta-disk internal;
}
on centos8-str2 {
device /dev/drbd0;
disk /dev/mapper/pool-data0;
address 172.17.0.42:7789;
meta-disk internal;
}
}
●メタデータ作成及びDRBD起動
仮想ホストでDRDB構成する際、リソース有効化時に下記のようなエラーが出力される場合があります。
[root@centos8-str1 ~]# drbdadm up r0 modprobe: ERROR: could not insert 'drbd': Required key not available Failed to modprobe drbd (No such file or directory) Command 'drbdsetup new-resource drbd0 1' terminated with exit code 20
参考URL:よくある質問
参考URL:仮想マシンの UEFI セキュア ブートを有効または無効にする
リンク先を参照し下記の方法により解決しました。
各仮想マシンをパワーオフします。
VMware Host Clientにログインして仮想マシンを選択します。
[編集] をクリックします。
[設定の編集] ウィンドウで、[仮想マシンオプション] をクリックします。
[起動オプション] の左側の▶をクリックし、ファームウェアが [EFI] に設定されていることを確認します。
[UEFIセキュア ブートの有効化] チェック ボックスを外し、[OK] をクリックします。
また、過去にDRBDを作成している場合、下記のようなエラーが表示されることがあります。
[root@centos8-str1 ~]# drbdadm up r0 new-minor r0 0 0: sysfs node '/sys/devices/virtual/block/drbd0' (already? still?) exists r0: Failure: (161) Minor or volume exists already (delete it first) Command 'drbdsetup new-minor r0 0 0' terminated with exit code 10指示とおり該当nodeを削除しようとしても「削除できません」と表示されてしまいます。
[root@centos8-str1 ~]# rm -rf /sys/devices/virtual/block/drbd0 rm: '/sys/devices/virtual/block/drbd0/uevent' を削除できません: 許可されていない操作です rm: '/sys/devices/virtual/block/drbd0/ext_range' を削除できません: 許可されていない操作です : (以下、省略)この場合、下記のように対処します。
[root@centos8-str1 ~]# drbdadm create-md r0 md_offset 53682892800 al_offset 53682860032 bm_offset 53681221632 Found some data ==> This might destroy existing data! <== Do you want to proceed? [need to type 'yes' to confirm] yes initializing activity log initializing bitmap (1600 KB) to all zero Writing meta data... New drbd meta data block successfully created. success [root@centos8-str1 ~]# drbdadm up r0 (同じエラーが表示されます。) new-minor r0 0 0: sysfs node '/sys/devices/virtual/block/drbd0' (already? still?) exists r0: Failure: (161) Minor or volume exists already (delete it first) Command 'drbdsetup new-minor r0 0 0' terminated with exit code 10 [root@centos8-str1 ~]# drbdadm down r0 [root@centos8-str1 ~]# rm -rf /sys/devices/virtual/block/drbd0 (今度は正常に削除できました。)この後、再度メタデータを作成してください。
メタデータを作成し、DRBDリソースを初期化し有効にします。
各ホストはsecondaryとして起動します。
[root@centos8-str1 ~]# drbdadm create-md r0 [need to type 'yes' to confirm] yes initializing activity log initializing bitmap (320 KB) to all zero Writing meta data... New drbd meta data block successfully created. success [root@centos8-str1 ~]# drbdadm up r0 [root@centos8-str1 ~]# drbdadm status r0 r0 role:Secondary disk:Inconsistent centos8-str2 connection:Connecting [root@centos8-str2 ~]# drbdadm create-md r0 [need to type 'yes' to confirm] yes initializing activity log initializing bitmap (320 KB) to all zero Writing meta data... New drbd meta data block successfully created. success [root@centos8-str2 ~]# drbdadm up r0 [root@centos8-str2 ~]# drbdadm status r0 r0 role:Secondary disk:Inconsistent centos8-str1 connection:Connectingこの時点ではまだデバイスの同期が行われていないため、「Inconsistent」状態になります。
●DRBD同期開始
初期化のためcentos8-str1側をプライマリに昇格させ、ファイルシステムを作成します。
「--force」オプションを付けると、DRBDのストレージの初期同期が開始され、centos8-str1からcentos8-str2にストレージの内容がコピーされます。
[root@centos8-str1 ~]# drbdadm primary --force r0
[root@centos8-str1 ~]# drbdadm status r0
r0 role:Primary
disk:UpToDate
centos8-str2 role:Secondary
replication:SyncSource peer-disk:Inconsistent done:12.17 ← 同期の進捗(%)
同期が完了するとdrbdadm statusの結果は以下の通りとなります。
[root@centos8-str1 ~]# drbdadm status r0
r0 role:Primary
disk:UpToDate
centos8-str2 role:Secondary
peer-disk:UpToDate
[root@centos8-str2 ~]# drbdadm status r0
r0 role:Secondary
disk:UpToDate
centos8-str1 role:Primary
peer-disk:UpToDate
●DRBDの停止
セカンダリを先に停止します。
[root@centos8-str2 ~]# drbdadm down r0 [root@centos8-str2 ~]# drbdadm status r0 # No currently configured DRBD found. r0: No such resource Command 'drbdsetup status r0' terminated with exit code 10 [root@centos8-str1 ~]# drbdadm status r0 r0 role:Primary disk:UpToDate centos8-str2 connection:Connecting次にプライマリを停止します。
※アンマウントしないと下記のようなエラーが表示されます。
[root@centos8-str1 ~]# drbdadm down r0
r0: State change failed: (-12) Device is held open by someone
additional info from kernel:
/dev/drbd0 opened by mount (pid 12542) at 2021-03-18 06:37:27.597
Command 'drbdsetup down r0' terminated with exit code 11
[root@centos8-str1 ~]# umount /mnt2/drbd0
[root@centos8-str1 ~]# drbdadm down r0
以上です。
●DRBDデバイスをプライマリホストで使ってみます
DRBDデバイスができたところで、lsblk(list block devices)の内容を確認します。
※「lsblk」(list block devices)は、現在利用できるブロックデバイスを一覧表示するコマンドです。
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sdc 8:32 0 10G 0 disk
└─sdc1 8:33 0 10G 0 part
└─pool-data0 253:2 0 10G 0 lvm
└─drbd0 147:0 0 10G 0 disk
centos8-str1で作成したDRBDデバイスにファイルシステムを作成してマウントします。
[root@centos8-str1 ~]# mkfs.xfs /dev/drbd0 ← フォーマット [root@centos8-str1 ~]# mkdir /mnt2/drbd0 ← マウントポイント作成 [root@centos8-str1 ~]# mount /dev/drbd0 /mnt2/drbd0 [root@centos8-str1 ~]$ df -hT /mnt2/drbd0 ファイルシス タイプ サイズ 使用 残り 使用% マウント位置 /dev/drbd0 xfs 10G 104M 9.9G 2% /mnt2/drbd0テストデータを書き込んでみます。
[root@centos8-str1 ~]# for i in {0..9}; do DATETIME=`date +%Y%m%d_%H%M%S_%3N`;sudo touch /mnt2/drbd0/${DATETIME}.txt; done
[root@centos8-str1 ~]# ls -l /mnt2/drbd0
合計 0
-rw-r--r-- 1 root root 0 3月 6 08:15 20210306_081512_342.txt
-rw-r--r-- 1 root root 0 3月 6 08:15 20210306_081512_352.txt
-rw-r--r-- 1 root root 0 3月 6 08:15 20210306_081512_362.txt
-rw-r--r-- 1 root root 0 3月 6 08:15 20210306_081512_372.txt
-rw-r--r-- 1 root root 0 3月 6 08:15 20210306_081512_382.txt
-rw-r--r-- 1 root root 0 3月 6 08:15 20210306_081512_391.txt
-rw-r--r-- 1 root root 0 3月 6 08:15 20210306_081512_400.txt
-rw-r--r-- 1 root root 0 3月 6 08:15 20210306_081512_410.txt
-rw-r--r-- 1 root root 0 3月 6 08:15 20210306_081512_419.txt
-rw-r--r-- 1 root root 0 3月 6 08:15 20210306_081512_428.txt
正常に書き込みができました。
●セカンダリホストを昇格しマウントしてみます
centos8-str1でDRBDデバイスをアンマウントし、セカンダリに降格させます。
[root@centos8-str1 ~]# umount /mnt2/drbd0
[root@centos8-str1 ~]# drbdadm secondary r0
[root@centos8-str1 ~]# drbdadm status r0
r0 role:Secondary
disk:UpToDate
centos8-str2 role:Secondary
peer-disk:UpToDate
centos8-str2でプライマリに昇格させて、DRBDデバイスをマウントします。
[root@centos8-str2 ~]# drbdadm primary r0
[root@centos8-str2 ~]# drbdadm status r0
r0 role:Primary
disk:UpToDate
centos8-str1 role:Secondary
peer-disk:UpToDate
[root@centos8-str2 ~]# mkdir /mnt2/drbd0 ← マウントポイント作成
[root@centos8-str2 ~]# mount /dev/drbd0 /mnt2/drbd0
[root@centos8-str2 ~]# df -hT /mnt2/drbd0
ファイルシス タイプ サイズ 使用 残り 使用% マウント位置
/dev/drbd0 xfs 10G 104M 9.9G 2% /mnt2/drbd0
[root@centos8-str2 ~]# ls -al /mnt2/drbd0
合計 0
drwxr-xr-x 2 root root 136 3月 7 00:07 .
drwxr-xr-x 3 root root 19 3月 7 00:10 ..
-rw-r--r-- 1 root root 0 3月 7 00:07 0.txt
-rw-r--r-- 1 root root 0 3月 7 00:07 1.txt
-rw-r--r-- 1 root root 0 3月 7 00:07 2.txt
-rw-r--r-- 1 root root 0 3月 7 00:07 3.txt
-rw-r--r-- 1 root root 0 3月 7 00:07 4.txt
-rw-r--r-- 1 root root 0 3月 7 00:07 5.txt
-rw-r--r-- 1 root root 0 3月 7 00:07 6.txt
-rw-r--r-- 1 root root 0 3月 7 00:07 7.txt
-rw-r--r-- 1 root root 0 3月 7 00:07 8.txt
-rw-r--r-- 1 root root 0 3月 7 00:07 9.txt
●DRBD9の新機能について
自動プロモーション機能を使って、プライマリ・セカンダリの切り替え状況を確認します。
まず、両サーバをセカンダリに降格させます。
[root@centos8-str1 ~]# umount /mnt2/drbd0
[root@centos8-str1 ~]# drbdadm secondary r0
[root@centos8-str1 ~]# drbdadm status r0
r0 role:Secondary
disk:UpToDate
centos8-str2 role:Secondary
peer-disk:UpToDate
[root@centos8-str2 ~]# drbdadm status r0
r0 role:Secondary
disk:UpToDate
centos8-str1 role:Secondary
peer-disk:UpToDate
centos8-str1側でマウントしてみます。drbdadmで昇格させることなく、自動でプライマリに昇格しました。
[root@centos8-str1 ~]# mount /dev/drbd0 /mnt/drbd0
[root@centos8-str1 ~]# drbdadm status r0
r0 role:Primary
disk:UpToDate
centos8-str2 role:Secondary
peer-disk:UpToDate
アンマウントしてみます。
[root@centos8-str1 ~]# umount /mnt/drbd0
[root@centos8-str1 ~]# drbdadm status r0
r0 role:Secondary
disk:UpToDate
centos8-str2 role:Secondary
peer-disk:UpToDate
centos8-str1、centos8-str2でマウントしてみます。centos8-str2側はエラーが表示されてマウント出来ないのが確認できるかと思います。
[root@centos8-str1 ~]# mount /dev/drbd0 /mnt/drbd0
[root@centos8-str1 ~]# drbdadm status r0
r0 role:Primary
disk:UpToDate
centos8-str2 role:Secondary
peer-disk:UpToDate
[root@centos8-str2 ~]# mount /dev/drbd0 /mnt2/drbd0
mount: /mnt2/drbd0: mount(2) システムコールが失敗しました: 不正なメディア形式です.
[root@centos8-str2 ~]# sudo drbdadm status r0
r0 role:Secondary
disk:UpToDate
centos8-str1 role:Primary
peer-disk:UpToDate
●DRBDの自動起動設定
OS起動時にDRBDが起動するように設定します。
[root@centos8-str1 ~]# systemctl enable drbd
Created symlink /etc/systemd/system/multi-user.target.wants/drbd.service → /usr/lib/systemd/system/drbd.service.
[root@centos8-str2 ~]# systemctl enable drbd
Created symlink /etc/systemd/system/multi-user.target.wants/drbd.service → /usr/lib/systemd/system/drbd.service.
[root@centos8-str1 ~]# shutdown -r now
Connection to centos8-str1 closed by remote host.
Connection to centos8-str1 closed.
[root@centos8-str2 ~]# shutdown -r now
Connection to centos8-str2 closed by remote host.
Connection to centos8-str2 closed.
[root@centos8-str1 ~]# drbdadm status r0
r0 role:Secondary
disk:UpToDate
centos8-str2 role:Secondary
peer-disk:UpToDate
[root@centos8-str2 ~]# drbdadm status r0
r0 role:Secondary
disk:UpToDate
centos8-str1 role:Secondary
peer-disk:UpToDate
両ノードのOS再起動後、DRBDが両方Secondary状態で起動することが確認できます。
●自動プロモーション
DRBD9は自動プロモーションが有効になっています。
mount操作を実行すると自動的にPrimaryに昇格され、umountで自動的にSecondaryに降格されます。
[root@centos8-str1 ~]# drbdadm status r0
r0 role:Secondary
disk:UpToDate
centos8-str2 role:Secondary
peer-disk:UpToDate
[root@centos8-str1 ~]# mount /dev/drbd0 /mnt2/drbd0
[root@centos8-str1 ~]# drbdadm status r0
r0 role:Primary
disk:UpToDate
centos8-str2 role:Secondary
peer-disk:UpToDate
なお、既にPrimaryになっているノードがある状態でmount実行しようとすると下記のように失敗します。
[root@centos8-str1 ~]# mount /dev/drbd0 /mnt2/drbd0 mount: /mnt2/drbd0: /dev/drbd0 は /mnt2/drbd0 にマウント済みです. [root@centos8-str2 ~]# mount /dev/drbd0 /mnt2/drbd0 mount: /mnt2/drbd0: mount(2) システムコールが失敗しました: 不正なメディア形式です.また、注意点として、一度drbdadmコマンドで手動でPrimary/Secondaryを切り替えると、自動プロモーションは無効になります。
再度、有効にするにはDRBDを再起動する必要があります。
●DRBDをpacemakerの現在のリソースに追加する
参考URL:ディスクHAクラスタ化(Pacemaker+Corosync+pcs+DRBD)
既に構築されているPacemaker(「クラスターの起動(Centos8 Stream向け)」)にDRBDデバイス上のファイルシステムを管理する設定を追加します。
クラスタのプロパティは下記を設定済みです。
# pcs property set stonith-enabled=false # pcs property set no-quorum-policy=ignoreDRBDは自動フェールバックを無効としておかないとDRDBでフェンシングが発生し、2台ともStandAlone状態となってしまう場合があります。
この対策のため、自動フェールバックを無効とした方が良いでしょう。(Warningは無視します)。
# pcs resource defaults resource-stickiness=INFINITY Warning: This command is deprecated and will be removed. Please use 'pcs resource defaults update' instead. Warning: Defaults do not apply to resources which override them with their own defined values
現在のPacemakerの設定は下記のとおりです。
[root@centos8-str1 ~]# pcs resource config
Group: rg01
Resource: VirtualIP (class=ocf provider=heartbeat type=IPaddr2)
Attributes: cidr_netmask=24 ip=172.17.0.40 nic=ens192
Operations: monitor interval=60s on-fail=standby (VirtualIP-monitor-interval-60s)
start interval=0s timeout=20s (VirtualIP-start-interval-0s)
stop interval=0s timeout=20s (VirtualIP-stop-interval-0s)
Resource: ShareDir (class=ocf provider=heartbeat type=Filesystem)
Attributes: device=/dev/sdb1 directory=/mnt fstype=ext4
Operations: monitor interval=20s timeout=40s (ShareDir-monitor-interval-20s)
start interval=0s timeout=60s (ShareDir-start-interval-0s)
stop interval=0s timeout=60s (ShareDir-stop-interval-0s)
Resource: MariaDB (class=systemd type=mariadb)
Operations: monitor interval=60 timeout=100 (MariaDB-monitor-interval-60)
start interval=0s timeout=100 (MariaDB-start-interval-0s)
stop interval=0s timeout=100 (MariaDB-stop-interval-0s)
現在のクラスタ構成にDRBDリソースr0をDRBD_r0という名前で追加します。
[root@centos8-str1 ~]# pcs resource create DRBD_r0 ocf:linbit:drbd drbd_resource=r0 --group rg01DRBD_r0をmaster/slaveとして設定します。
[root@centos8-str1 ~]# pcs resource promotable DRBD_r0 master-max=1 master-node-max=1 clone-max=2 clone-node-max=1 notify=true
- master-max=1
マスターに昇格させることができるリソースのコピー数 - master-node-max=1
1つのノード上でマスターに昇格させることができるリソースのコピー数 - clone-max=2
いくつのリソースコピーを開始するか。デフォルトはクラスタ内のノード数 - clone-node-max=1
1つのノードで開始状態にできるリソースのコピー数 - notify=true
クローンのコピーを開始、停止する前後に他の全てのコピーに伝える
[root@centos8-str1 ~]# pcs status
Cluster name: bigbang
Cluster Summary:
* Stack: corosync
* Current DC: centos8-str1 (version 2.0.5-8.el8-ba59be7122) - partition with quorum
* Last updated: Mon Mar 8 15:36:14 2021
* Last change: Mon Mar 8 15:35:59 2021 by root via cibadmin on centos8-str1
* 2 nodes configured
* 2 resource instances configured
Node List:
* Online: [ centos8-str1 centos8-str2 ]
Full List of Resources:
* Clone Set: DRBD_r0-clone [DRBD_r0] (promotable):
* Stopped: [ centos8-str1 centos8-str2 ]
Failed Resource Actions:
* DRBD_r0_start_0 on centos8-str1 'not configured' (6): call=119, status='complete', \
exitreason='you really should enable notify when using this RA (or set ignore_missing_notifications=true)', \
last-rc-change='2021-03-08 15:33:32 +09:00', queued=0ms, exec=43ms
Daemon Status:
corosync: active/disabled
pacemaker: active/disabled
pcsd: active/enabled
エラーが表示されていますので、クリアします。
[root@centos8-str1 ~]# pcs resource cleanup DRBD_r0 Cleaned up DRBD_r0:0 on centos8-str2 Cleaned up DRBD_r0:0 on centos8-str1 Cleaned up DRBD_r0:1 on centos8-str2 Cleaned up DRBD_r0:1 on centos8-str1 Waiting for 1 reply from the controller ... got reply (done)/dev/drbd0をxfs形式で/mnt2/drbd0ディレクトリへマウントするクラスタリソース「FS_DRBD0」を作成します。
[root@centos8-str1 ~]# pcs resource create FS_DRBD0 ocf:heartbeat:Filesystem device=/dev/drbd0 directory=/mnt2/drbd0 fstype=xfs --group rg01
[root@centos8-str1 ~]# pcs resource status
* Resource Group: rg01:
* VirtualIP (ocf::heartbeat:IPaddr2): Started centos8-str1
* ShareDir (ocf::heartbeat:Filesystem): Started centos8-str1
* MariaDB (systemd:mariadb): Started centos8-str1
* FS_DRBD0 (ocf::heartbeat:Filesystem): Started centos8-str1
* Clone Set: DRBD_r0-clone [DRBD_r0] (promotable):
* Masters: [ centos8-str1 ]
* Slaves: [ centos8-str2 ]
DRBD_r0がmaster側のノードでリソースグループrg01を起動するように設定します。
[root@centos8-str1 ~]# pcs constraint colocation add DRBD_r0-clone with Master rg01DRBD_r0起動後にリソースグループrg01を起動するように設定します。
[root@centos8-str1 ~]# pcs constraint order promote DRBD_r0-clone then start rg01 Adding DRBD_r0-clone rg01 (kind: Mandatory) (Options: first-action=promote then-action=start)DRBD_r0がMaster側のノードでFS_DRBD0リソースを起動するように設定します。
[root@centos8-str1 ~]# pcs constraint colocation add DRBD_r0-clone with Master FS_DRBD0DRBD_r0起動後にFS_DRBD0リソースを起動するように設定します。
[root@centos8-str1 ~]# pcs constraint order promote DRBD_r0-clone then start FS_DRBD0 Adding DRBD_r0-clone FS_DRBD0 (kind: Mandatory) (Options: first-action=promote then-action=start)
●DRBDのクラスタ状態を確認
マウント状態を確認します。
[root@centos8-str1 ~]# df -h
ファイルシス サイズ 使用 残り 使用% マウント位置
devtmpfs 3.8G 0 3.8G 0% /dev
tmpfs 3.8G 48M 3.8G 2% /dev/shm
tmpfs 3.8G 9.4M 3.8G 1% /run
tmpfs 3.8G 0 3.8G 0% /sys/fs/cgroup
/dev/mapper/cs-root 70G 7.0G 64G 10% /
/dev/mapper/cs-home 421G 3.0G 418G 1% /home
/dev/sda2 1014M 233M 782M 23% /boot
/dev/sda1 599M 7.3M 592M 2% /boot/efi
tmpfs 777M 1.2M 776M 1% /run/user/42
tmpfs 777M 0 777M 0% /run/user/0
/dev/sdb1 49G 174M 47G 1% /mnt
/dev/drbd0 10G 104M 9.9G 2% /mnt2/drbd0
[root@centos8-str2 ~]# df -h
ファイルシス サイズ 使用 残り 使用% マウント位置
devtmpfs 3.8G 0 3.8G 0% /dev
tmpfs 3.8G 47M 3.8G 2% /dev/shm
tmpfs 3.8G 9.4M 3.8G 1% /run
tmpfs 3.8G 0 3.8G 0% /sys/fs/cgroup
/dev/mapper/cs-root 70G 6.7G 64G 10% /
/dev/mapper/cs-home 421G 3.0G 418G 1% /home
/dev/sda2 1014M 233M 782M 23% /boot
/dev/sda1 599M 7.3M 592M 2% /boot/efi
tmpfs 777M 1.2M 776M 1% /run/user/42
tmpfs 777M 0 777M 0% /run/user/0
/mnt2/drbd0 ← マウントされていない
クラスタの状態を確認します。
[root@centos8-str1 ~]# pcs status
Cluster name: bigbang
Cluster Summary:
* Stack: corosync
* Current DC: centos8-str1 (version 2.0.5-8.el8-ba59be7122) - partition with quorum
* Last updated: Mon Mar 8 16:49:55 2021
* Last change: Mon Mar 8 16:49:01 2021 by root via cibadmin on centos8-str1
* 2 nodes configured
* 6 resource instances configured
Node List:
* Online: [ centos8-str1 centos8-str2 ]
Full List of Resources:
* Resource Group: rg01:
* VirtualIP (ocf::heartbeat:IPaddr2): Started centos8-str1
* ShareDir (ocf::heartbeat:Filesystem): Started centos8-str1
* MariaDB (systemd:mariadb): Started centos8-str1
* FS_DRBD0 (ocf::heartbeat:Filesystem): Started centos8-str1
* Clone Set: DRBD_r0-clone [DRBD_r0] (promotable):
* Masters: [ centos8-str1 ]
* Slaves: [ centos8-str2 ]
Daemon Status:
corosync: active/disabled
pacemaker: active/disabled
pcsd: active/enabled
ノードcentos8-str1がMasterで、リソースFS_DRBD0がcentos8-str1で稼働していることがわかります。
設定状態を確認します。
[root@centos8-str1 ~]# pcs config show
Cluster Name: bigbang
Corosync Nodes:
centos8-str1 centos8-str2
Pacemaker Nodes:
centos8-str1 centos8-str2
Resources:
Group: rg01
Resource: VirtualIP (class=ocf provider=heartbeat type=IPaddr2)
Attributes: cidr_netmask=24 ip=172.17.0.40 nic=ens192
Operations: monitor interval=30s (VirtualIP-monitor-interval-30s)
start interval=0s timeout=20s (VirtualIP-start-interval-0s)
stop interval=0s timeout=20s (VirtualIP-stop-interval-0s)
Resource: ShareDir (class=ocf provider=heartbeat type=Filesystem)
Attributes: device=/dev/sdb1 directory=/mnt fstype=ext4
Operations: monitor interval=20s timeout=40s (ShareDir-monitor-interval-20s)
start interval=0s timeout=60s (ShareDir-start-interval-0s)
stop interval=0s timeout=60s (ShareDir-stop-interval-0s)
Resource: MariaDB (class=systemd type=mariadb)
Operations: monitor interval=60 timeout=100 (MariaDB-monitor-interval-60)
start interval=0s timeout=100 (MariaDB-start-interval-0s)
stop interval=0s timeout=100 (MariaDB-stop-interval-0s)
Resource: FS_DRBD0 (class=ocf provider=heartbeat type=Filesystem)
Attributes: device=/dev/drbd0 directory=/mnt2/drbd0 fstype=xfs
Operations: monitor interval=20s timeout=40s (FS_DRBD0-monitor-interval-20s)
start interval=0s timeout=60s (FS_DRBD0-start-interval-0s)
stop interval=0s timeout=60s (FS_DRBD0-stop-interval-0s)
Clone: DRBD_r0-clone
Meta Attrs: clone-max=2 clone-node-max=1 master-max=1 master-node-max=1 notify=true promotable=true
Resource: DRBD_r0 (class=ocf provider=linbit type=drbd)
Attributes: drbd_resource=r0
Operations: demote interval=0s timeout=90 (DRBD_r0-demote-interval-0s)
monitor interval=20 role=Slave timeout=20 (DRBD_r0-monitor-interval-20)
monitor interval=10 role=Master timeout=20 (DRBD_r0-monitor-interval-10)
notify interval=0s timeout=90 (DRBD_r0-notify-interval-0s)
promote interval=0s timeout=90 (DRBD_r0-promote-interval-0s)
reload interval=0s timeout=30 (DRBD_r0-reload-interval-0s)
start interval=0s timeout=240 (DRBD_r0-start-interval-0s)
stop interval=0s timeout=100 (DRBD_r0-stop-interval-0s)
Stonith Devices:
Fencing Levels:
Location Constraints:
Resource: rg01
Enabled on:
Node: centos8-str1 (score:INFINITY) (role:Started) (id:cli-prefer-rg01)
Ordering Constraints:
promote DRBD_r0-clone then start rg01 (kind:Mandatory) (id:order-DRBD_r0-clone-rg01-mandatory)
promote DRBD_r0-clone then start FS_DRBD0 (kind:Mandatory) (id:order-DRBD_r0-clone-FS_DRBD0-mandatory)
Colocation Constraints:
DRBD_r0-clone with rg01 (score:INFINITY) (rsc-role:Started) (with-rsc-role:Master) (id:colocation-DRBD_r0-clone-rg01-INFINITY)
DRBD_r0-clone with FS_DRBD0 (score:INFINITY) (rsc-role:Started) (with-rsc-role:Master) (id:colocation-DRBD_r0-clone-FS_DRBD0-INFINITY)
Ticket Constraints:
Alerts:
No alerts defined
Resources Defaults:
No defaults set
Operations Defaults:
No defaults set
Cluster Properties:
cluster-infrastructure: corosync
cluster-name: bigbang
dc-version: 2.0.5-8.el8-ba59be7122
have-watchdog: false
last-lrm-refresh: 1615188468
no-quorum-policy: ignore
stonith-enabled: false
Tags:
No tags defined
Quorum:
Options:
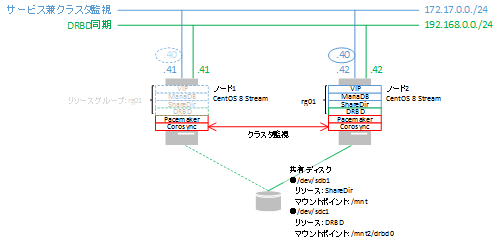
●フェールオーバーの確認
ノードcentos8-str1をスタンバイ状態にし、強制的にフェールオーバーさせます。
[root@centos8-str1 ~]# pcs node standby centos8-str1 [root@centos8-str1 ~]# pcs status Cluster name: bigbang Cluster Summary: * Stack: corosync * Current DC: centos8-str1 (version 2.0.5-8.el8-ba59be7122) - partition with quorum * Last updated: Mon Mar 8 21:09:35 2021 * Last change: Mon Mar 8 21:09:27 2021 by root via cibadmin on centos8-str1 * 2 nodes configured * 6 resource instances configured Node List: * Node centos8-str1: standby * Online: [ centos8-str2 ] Full List of Resources: * Resource Group: rg01: * VirtualIP (ocf::heartbeat:IPaddr2): Started centos8-str2 * ShareDir (ocf::heartbeat:Filesystem): Started centos8-str2 * MariaDB (systemd:mariadb): Started centos8-str2 * FS_DRBD0 (ocf::heartbeat:Filesystem): Started centos8-str2 * Clone Set: DRBD_r0-clone [DRBD_r0] (promotable): * Masters: [ centos8-str2 ] * Stopped: [ centos8-str1 ] Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled [root@centos8-str2 ~]# pcs status Cluster name: bigbang Cluster Summary: * Stack: corosync * Current DC: centos8-str1 (version 2.0.5-8.el8-ba59be7122) - partition with quorum * Last updated: Mon Mar 8 21:09:42 2021 * Last change: Mon Mar 8 21:09:27 2021 by root via cibadmin on centos8-str1 * 2 nodes configured * 6 resource instances configured Node List: * Node centos8-str1: standby * Online: [ centos8-str2 ] Full List of Resources: * Resource Group: rg01: * VirtualIP (ocf::heartbeat:IPaddr2): Started centos8-str2 * ShareDir (ocf::heartbeat:Filesystem): Started centos8-str2 * MariaDB (systemd:mariadb): Started centos8-str2 * FS_DRBD0 (ocf::heartbeat:Filesystem): Started centos8-str2 * Clone Set: DRBD_r0-clone [DRBD_r0] (promotable): * Masters: [ centos8-str2 ] * Stopped: [ centos8-str1 ] Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled [root@centos8-str2 ~]# ls -l /mnt2/drbd0/ 合計 0 -rw-r--r-- 1 root root 0 3月 7 00:07 0.txt -rw-r--r-- 1 root root 0 3月 7 00:07 1.txt -rw-r--r-- 1 root root 0 3月 7 00:07 2.txt -rw-r--r-- 1 root root 0 3月 7 00:07 3.txt -rw-r--r-- 1 root root 0 3月 7 00:07 4.txt -rw-r--r-- 1 root root 0 3月 7 00:07 5.txt -rw-r--r-- 1 root root 0 3月 7 00:07 6.txt -rw-r--r-- 1 root root 0 3月 7 00:07 7.txt -rw-r--r-- 1 root root 0 3月 7 00:07 8.txt -rw-r--r-- 1 root root 0 3月 7 00:07 9.txtcentos8-str1が停止し、リソースがcentos8-str2に移動しています。
マウント先ディレクトリ内のファイルも存在しています。
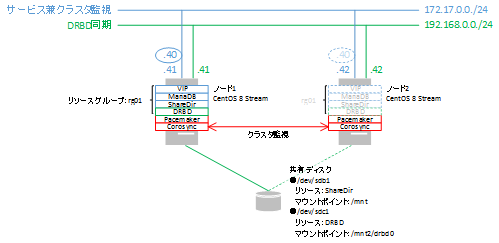
●フェールバックの確認
centos8-str2をスタンバイ状態にする前に、DRBDデバイス上にファイルを作成します。
[root@centos8-str2 ~]# touch /mnt2/drbd0/test-file [root@centos8-str2 ~]# ls -l /mnt2/drbd0/ 合計 0 -rw-r--r-- 1 root root 0 3月 7 00:07 0.txt -rw-r--r-- 1 root root 0 3月 7 00:07 1.txt -rw-r--r-- 1 root root 0 3月 7 00:07 2.txt -rw-r--r-- 1 root root 0 3月 7 00:07 3.txt -rw-r--r-- 1 root root 0 3月 7 00:07 4.txt -rw-r--r-- 1 root root 0 3月 7 00:07 5.txt -rw-r--r-- 1 root root 0 3月 7 00:07 6.txt -rw-r--r-- 1 root root 0 3月 7 00:07 7.txt -rw-r--r-- 1 root root 0 3月 7 00:07 8.txt -rw-r--r-- 1 root root 0 3月 7 00:07 9.txt -rw-r--r-- 1 root root 0 3月 8 21:10 test-filecentos8-str2をスタンバイ状態にし、centos8-str1にフェールバックさせます。
[root@centos8-str1 ~]# pcs node unstandby centos8-str1 [root@centos8-str2 ~]# pcs node standby centos8-str2 [root@centos8-str2 ~]# pcs status Cluster name: bigbang Cluster Summary: * Stack: corosync * Current DC: centos8-str1 (version 2.0.5-8.el8-ba59be7122) - partition with quorum * Last updated: Mon Mar 8 21:12:22 2021 * Last change: Mon Mar 8 21:12:12 2021 by root via cibadmin on centos8-str2 * 2 nodes configured * 6 resource instances configured Node List: * Node centos8-str2: standby * Online: [ centos8-str1 ] Full List of Resources: * Resource Group: rg01: * VirtualIP (ocf::heartbeat:IPaddr2): Started centos8-str1 * ShareDir (ocf::heartbeat:Filesystem): Started centos8-str1 * MariaDB (systemd:mariadb): Started centos8-str1 * FS_DRBD0 (ocf::heartbeat:Filesystem): Started centos8-str1 * Clone Set: DRBD_r0-clone [DRBD_r0] (promotable): * Masters: [ centos8-str1 ] * Stopped: [ centos8-str2 ] Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabledcentos8-str1にフェールバックしています。
centos8-str1側でもクラスタの状態を確認します。
[root@centos8-str1 ~]# pcs status Cluster name: bigbang Cluster Summary: * Stack: corosync * Current DC: centos8-str1 (version 2.0.5-8.el8-ba59be7122) - partition with quorum * Last updated: Mon Mar 8 21:12:32 2021 * Last change: Mon Mar 8 21:12:12 2021 by root via cibadmin on centos8-str2 * 2 nodes configured * 6 resource instances configured Node List: * Node centos8-str2: standby * Online: [ centos8-str1 ] Full List of Resources: * Resource Group: rg01: * VirtualIP (ocf::heartbeat:IPaddr2): Started centos8-str1 * ShareDir (ocf::heartbeat:Filesystem): Started centos8-str1 * MariaDB (systemd:mariadb): Started centos8-str1 * FS_DRBD0 (ocf::heartbeat:Filesystem): Started centos8-str1 * Clone Set: DRBD_r0-clone [DRBD_r0] (promotable): * Masters: [ centos8-str1 ] * Stopped: [ centos8-str2 ] Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled [root@centos8-str1 ~]# ls -l /mnt2/drbd0/ 合計 0 -rw-r--r-- 1 root root 0 3月 7 00:07 0.txt -rw-r--r-- 1 root root 0 3月 7 00:07 1.txt -rw-r--r-- 1 root root 0 3月 7 00:07 2.txt -rw-r--r-- 1 root root 0 3月 7 00:07 3.txt -rw-r--r-- 1 root root 0 3月 7 00:07 4.txt -rw-r--r-- 1 root root 0 3月 7 00:07 5.txt -rw-r--r-- 1 root root 0 3月 7 00:07 6.txt -rw-r--r-- 1 root root 0 3月 7 00:07 7.txt -rw-r--r-- 1 root root 0 3月 7 00:07 8.txt -rw-r--r-- 1 root root 0 3月 7 00:07 9.txt -rw-r--r-- 1 root root 0 3月 8 21:10 test-filecentos8-str2で作成したファイルも正常に反映されています。
●NIC障害
現在のクラスタ状態は、centos8-str1がセカンダリ、centos8-str2がプライマリです。
擬似NIC障害を故意におこしDRBDの状態変移及び修復方法を確認します。
VMware Host Clientにログインし、centos8-str2のInterconnect側のチェックを外します。
[root@centos8-str2 ~]# drbdadm status r0 r0 role:Primary disk:UpToDate centos8-str1 connection:Connecting [root@centos8-str1 ~]# drbdadm status r0 r0 role:Secondary disk:UpToDate centos8-str2 connection:Connecting状態が2台ともConnectingとなります。
この状態のままcentos8-str2をスタンバイとし、centos8-str1をプライマリに切り替えます。
[root@centos8-str2 ~]# pcs node standby centos8-str2 [root@centos8-str2 ~]# pcs node unstandby centos8-str2 [root@centos8-str2 ~]# drbdadm status r0 r0 role:Secondary disk:UpToDate centos8-str1 connection:Connecting [root@centos8-str1 ~]# drbdadm status r0 r0 role:Primary disk:UpToDate centos8-str2 connection:Connectingcentos8-str1のDRBDがプライマリになっていますが、接続状態はConnectingのままです。
VMware Host Clientにログインし、先ほど切断したcentos8-str2のInterconnect側のチェックを入れ、接続できるようにします。
[root@centos8-str2 ~]# drbdadm status r0 r0 role:Secondary disk:UpToDate centos8-str1 connection:StandAlone [root@centos8-str1 ~]# drbdadm status r0 r0 role:Primary disk:UpToDate centos8-str2 connection:StandAloneDRBDは接続できましたが2台ともStandAloneになってしまっています。
これを解消するため下記のように実施します。
[root@centos8-str2 ~]# drbdadm -- --discard-my-data connect r0 [root@centos8-str2 ~]# drbdadm status r0 r0 role:Secondary disk:UpToDate centos8-str1 connection:Connectingcentos8-str2がConnecting状態になりましたので、centos8-str1側で下記を実行します。
[root@centos8-str1 ~]# drbdadm connect r0
[root@centos8-str1 ~]# drbdadm status r0
r0 role:Primary
disk:UpToDate
centos8-str2 role:Secondary
peer-disk:UpToDate
[root@centos8-str2 ~]# drbdadm status r0
r0 role:Secondary
disk:UpToDate
centos8-str1 role:Primary
peer-disk:UpToDate
元の状態に復旧しました。
逆に言えば、DRBDリソース用のNICの一方が故障中は自動手動に関わらずプライマリ・セカンダリが入れ替わるとこのような状況に陥ると言うことが分かりました。
●スプリットブレインからの復帰
参考URL:6.3. スプリットブレインからの手動回復
参考URL:作っておぼえるHAシステム4
DRBDのクラスタを構成しているサーバでスプリットブレインが検知されていました。
[root@centos8-str3 ~]# grep "Split-Brain" /var/log/messages : : Jun 16 16:33:46 centos8-str3 kernel: drbd r0/0 drbd0: Split-Brain detected but unresolved, dropping connection! Jun 16 16:45:50 centos8-str3 kernel: drbd r0/0 drbd0: Split-Brain detected but unresolved, dropping connection! Jun 16 16:45:51 centos8-str3 kernel: drbd r0/0 drbd0: Split-Brain detected but unresolved, dropping connection! Jun 17 14:45:56 centos8-str3 kernel: drbd r0/0 drbd0: Split-Brain detected, manually solved. Sync from this nodeサーバのDRBDの状態は下記のとおりです。
[root@centos8-str3 ~]# drbdadm status r0 r0 role:Primary disk:UpToDate centos8-str4 connection:StandAlone [root@centos8-str4 ~]# drbdadm status r0 r0 role:Secondary disk:UpToDate centos8-str3 connection:StandAloneまず、DRBDのSecondary側で作業します。
[root@centos8-str4 ~]# drbdadm disconnect r0
[root@centos8-str4 ~]# drbdadm secondary r0
[root@centos8-str4 ~]# drbdadm connect --discard-my-data r0
[root@centos8-str4 ~]# drbdadm status r0
r0 role:Secondary
disk:UpToDate
centos8-str3 connection:Connecting
次に、DRBDのPrimary側で作業します。
[root@centos8-str3 ~]# drbdadm disconnect r0
[root@centos8-str3 ~]# drbdadm connect r0
[root@centos8-str3 ~]# drbdadm status r0
r0 role:Primary
disk:UpToDate
centos8-str4 role:Secondary
replication:SyncSource peer-disk:Inconsistent done:1.30
DRBDが再接続され同期が始まっています。
暫くしてからSecondary側で確認すると
[root@centos8-str4 ~]# drbdadm status r0
r0 role:Secondary
disk:Inconsistent
centos8-str3 role:Primary
replication:SyncTarget peer-disk:UpToDate done:24.25
順調に同期が進んでいます(done:1.30 → done:24.25)。
最終的に正常な状態となりました。
[root@centos8-str3 ~]# drbdadm status r0
r0 role:Primary
disk:UpToDate
centos8-str4 role:Secondary
peer-disk:UpToDate
[root@centos8-str4 ~]# drbdadm status r0
r0 role:Secondary
disk:UpToDate
centos8-str3 role:Primary
peer-disk:UpToDate
ログを確認すると、手動で同期が完了した旨のメッセージが記録されていました。
[root@centos8-str3 ~]# grep "Split-Brain" /var/log/messages : : Jun 16 16:33:46 centos8-str3 kernel: drbd r0/0 drbd0: Split-Brain detected but unresolved, dropping connection! Jun 16 16:45:50 centos8-str3 kernel: drbd r0/0 drbd0: Split-Brain detected but unresolved, dropping connection! Jun 16 16:45:51 centos8-str3 kernel: drbd r0/0 drbd0: Split-Brain detected but unresolved, dropping connection! Jun 17 14:45:56 centos8-str3 kernel: drbd r0/0 drbd0: Split-Brain detected, manually solved. Sync from this node [root@centos8-str4 ~]# grep "Split-Brain" /var/log/messages : : Jun 16 16:33:46 centos8-str4 kernel: drbd r0/0 drbd0: Split-Brain detected but unresolved, dropping connection! Jun 16 16:45:50 centos8-str4 kernel: drbd r0/0 drbd0: Split-Brain detected but unresolved, dropping connection! Jun 16 16:45:51 centos8-str4 kernel: drbd r0/0 drbd0: Split-Brain detected but unresolved, dropping connection! Jun 17 14:45:56 centos8-str4 kernel: drbd r0/0 drbd0: Split-Brain detected, manually solved. Sync from peer node
●open(/dev/mapper/pool-data0) failed: No such file or directory
VMware ESXi(VMware vSpheer Hypervisor)のハードウェアを移行した影響のためか、VM上で構成していたDRBD(Pacemakerで管理)が動作しなくなりました。
DRBDモジュールが読み込まれているか確認します。
[root@centos8-str3 ~]# lsmod|grep drbd drbd_transport_tcp 28672 1 drbd 655360 2 drbd_transport_tcp libcrc32c 16384 5 nf_conntrack,nf_nat,nf_tables,xfs,drbd [root@centos8-str4 ~]# lsmod|grep drbd drbd_transport_tcp 28672 1 drbd 655360 2 drbd_transport_tcp libcrc32c 16384 5 nf_conntrack,nf_nat,nf_tables,xfs,drbdDRBDモジュールは正常に読み込まれています。
VM上の仮想ディスクは正常に認識されていますので、「●メタデータ作成及びDRBD起動」及び「●DRBD用のディスクの用意」を参照して作成し直します。
[root@centos8-str3 ~]# drbdadm up r0 open(/dev/mapper/pool-data0) failed: No such file or directory Command 'drbdmeta 0 v09 /dev/mapper/pool-data0 internal apply-al' terminated with exit code 20 [root@centos8-str4 ~]# drbdadm up r0 open(/dev/mapper/pool-data0) failed: No such file or directory Command 'drbdmeta 0 v09 /dev/mapper/pool-data0 internal apply-al' terminated with exit code 20
メタデータを再作成等の作業後、手動でDRBDを起動することができるようになりました。
しかしマウントすると下記のようなエラーが表示されます。
[root@centos8-str3 ~]# mount /dev/drbd0 /mnt mount: /mnt: wrong fs type, bad option, bad superblock on /dev/drbd0, missing codepage or helper program, or other error./dev/drbd0を新たにフォーマットすることにより、再マウントできるようになりました。
[root@centos8-str3 ~]# mkfs.xfs /dev/drbd0
●カーネルアップデート後DRBDが起動しない
DRBDが動作していた時のカーネルリリース番号は 4.18.0-305.3.1.el8.x86_64 でした。
動作しなくなったカーネルリリース番号は下記のとおりです。
kernel-4.18.0-310.el8.x86_64
kernel-4.18.0-315.el8.x86_64
下記コマンドを実行してもエラーとなり、DRBDは起動しません。
[root@centos8-str3 ~]# drbdadm up r0 modinfo: ERROR: Module drbd not found. modinfo: ERROR: Module drbd not found. modprobe: FATAL: Module drbd not found in directory /lib/modules/4.18.0-315.el8.x86_64 Failed to modprobe drbd (No such file or directory) Command 'drbdsetup new-resource r0 0' terminated with exit code 20 [root@centos8-str3 ~]# drbdadm status r0 modinfo: ERROR: Module drbd not found. modinfo: ERROR: Module drbd not found. modprobe: FATAL: Module drbd not found in directory /lib/modules/4.18.0-315.el8.x86_64 Failed to modprobe drbd (No such file or directory) Command 'drbdsetup status r0' terminated with exit code 20上記のようにエラーが表示されます。
DRBDモジュールの確認します。
[root@centos8-str3 ~]# find /lib/modules -name drbd* /lib/modules/4.18.0-305.el8.x86_64/extra/drbd90 /lib/modules/4.18.0-305.el8.x86_64/extra/drbd90/drbd.ko /lib/modules/4.18.0-305.el8.x86_64/extra/drbd90/drbd_transport_tcp.ko /lib/modules/4.18.0-305.3.1.el8.x86_64/weak-updates/drbd90 /lib/modules/4.18.0-305.3.1.el8.x86_64/weak-updates/drbd90/drbd_transport_tcp.ko /lib/modules/4.18.0-305.3.1.el8.x86_64/weak-updates/drbd90/drbd.ko/lib/modules/4.18.0-315.el8.x86_64には存在しませんが、/lib/modules/4.18.0-305.3.1.el8.x86_64には存在しました。
この状態のため、最新のカーネルリリース番号で起動してもDRBDモジュールが読み込まれないことが分かりました。
いろいろ調べた結果、kmod-drbd90-9.0.29-1.el8.elrepo.x86_64にはkernel-devel-4.18.0-305.3.1.el8.x86_64が必要ということでした。
[root@centos8-str3 ~]# rpmbuild --rebuild kmod-drbd90-9.0.29-1.el8_4.elrepo.src.rpm kmod-drbd90-9.0.29-1.el8_4.elrepo.src.rpm をインストール中です。 エラー: ビルド依存性の失敗: kernel-abi-whitelists は kmod-drbd90-9.0.29-1.el8.elrepo.x86_64 に必要とされています kernel-devel = 4.18.0-305.el8 は kmod-drbd90-9.0.29-1.el8.elrepo.x86_64 に必要とされています kernel-rpm-macros は kmod-drbd90-9.0.29-1.el8.elrepo.x86_64 に必要とされていますこのため、drbd90-utils、kmod-drbd90を何度再インストールしても、/lib/modules/4.18.0-315.el8.x86_64にインストールされないという訳です。
[root@centos8-str3 ~]# find /lib/modules -name drbd* /lib/modules/4.18.0-305.el8.x86_64/extra/drbd90 /lib/modules/4.18.0-305.el8.x86_64/extra/drbd90/drbd.ko /lib/modules/4.18.0-305.el8.x86_64/extra/drbd90/drbd_transport_tcp.ko /lib/modules/4.18.0-305.3.1.el8.x86_64/weak-updates/drbd90 /lib/modules/4.18.0-305.3.1.el8.x86_64/weak-updates/drbd90/drbd_transport_tcp.ko /lib/modules/4.18.0-305.3.1.el8.x86_64/weak-updates/drbd90/drbd.koしたがって、当面の間kmod-drbd90-9.0.29-1.el8.elrepo.x86_64を動作させるにはカーネルリリース番号が 4.18.0-305.3.1.el8.x86_64 で運用する必要があります。
●カーネルアップデート後DRBDが起動しない(その2)
CentOS Stream 8での出来事です。
誤ってカーネル(4.18.0-305.3.1.el8.x86_64)をアップデート(4.18.0-348.7.1.el8_5.x86_64)してしまったためクラスタが動作しなくなってしまいました。
カーネルのバージョンにかかわらず、pcsのバージョンが0.10.11-2.el8、pcs-0.10.12-1.el8.x86_64、pcs-0.10.12-2.el8.x86_64では下記のエラーが発生します。
[root@centos8-str2 ~]# pcs resource create DRBD_r0 ocf:linbit:drbd drbd_resource=r0 Error: Agent 'ocf:linbit:drbd' is not installed or does not provide valid metadata: Element content failed to validate content, line 117, use --force to override Error: Errors have occurred, therefore pcs is unable to continue [root@centos8-str2 ~]# pcs resource create DRBD_r0 ocf:linbit:drbd drbd_resource=r0 --force Warning: Agent 'ocf:linbit:drbd' is not installed or does not provide valid metadata: Element content failed to validate content, line 117また、カーネルのバージョンにかかわらずpcsのバージョンが0.10.11-1.el8では上記設定コマンドは正常に終了します。
ただし、クラスタに組み込むと動作しなくなります(期待しているSlaveにならず「Stopped」のまま)。
アップグレードされた製品は下記のとおりです。
インストール済みの製品が更新されています。 アップグレード済み: corosync-3.1.5-2.el8.x86_64 corosynclib-3.1.5-2.el8.x86_64 kernel-headers-4.18.0-348.7.1.el8_5.x86_64 kernel-tools-4.18.0-348.7.1.el8_5.x86_64 kernel-tools-libs-4.18.0-348.7.1.el8_5.x86_64 kmod-25-19.el8.x86_64 kmod-drbd90-9.1.5-1.el8_5.elrepo.x86_64 kmod-kvdo-6.2.5.72-81.el8.x86_64 kmod-libs-25-19.el8.x86_64 pacemaker-2.1.2-2.el8.x86_64 pacemaker-cli-2.1.2-2.el8.x86_64 pacemaker-cluster-libs-2.1.2-2.el8.x86_64 pacemaker-libs-2.1.2-2.el8.x86_64 pacemaker-schemas-2.1.2-2.el8.noarch インストール済み: kernel-4.18.0-348.7.1.el8_5.x86_64 kernel-core-4.18.0-348.7.1.el8_5.x86_64 kernel-devel-4.18.0-348.7.1.el8_5.x86_64 kernel-modules-4.18.0-348.7.1.el8_5.x86_64 削除しました: kernel-4.18.0-310.el8.x86_64 kernel-core-4.18.0-310.el8.x86_64 kernel-devel-4.18.0-310.el8.x86_64 kernel-modules-4.18.0-310.el8.x86_64 完了しました!まず、アップデートしてしまったkernel関連の製品(kernel、kernel-core、kernel-devel、kernel-headers、kernel-modules、kernel-tools、kernel-tools-libs)を元のバージョン(4.18.0-305.3.1.el8.x86_64)に戻します。
kernel関連の製品は、ダウングレードで対応可能なものはそのように対応し、必要に応じて削除、再インストールします。
その他の製品は元のkernelバージョン(4.18.0-305.3.1.el8.x86_64)で動作していた時のバージョンに一つ一つ戻します。
手動でDRBDの動作確認し、同期・プライマリへの移行・セカンダリへの移行は問題ありませんでした。
次に、クラスターに再度、組込んで動作確認しましたが、DRBD_r0-cloneが「Stopped」となり、これまでのようにSlaveになりませんでした。
(手動でのDRBDの動作確認及びクラスター再組込後の確認は何度も実施した。)
正常にクラスタが動作しないサーバの/var/log/pacemaker/pacemaker.logを確認したところ、下記のようなエラーがあることに気付きました。
Jan 11 17:33:33 Filesystem(FS_DRBD0)[10005]: WARNING: Couldn't find device [/dev/drbd0]. Expected /dev/??? to exist確認します。
[root@centos8-str1 ~]# ls /dev/drbd0 /dev/drbd0 [root@centos8-str2 ~]# ls /dev/drbd0 ls: '/dev/drbd0' にアクセスできません: そのようなファイルやディレクトリはありません問題が発生しているサーバにデバイスが存在していないようです。
drbd90-utils、drbd90-utils-sysvinit、kmod-drbd90を一度、削除、その後、再起動。再起動後、再インストール、再度再起動します。
これで「/dev/drbd0」が認識されました。手動でのDRBDの起動・同期・primaryへの移行・secondaryへの移行・停止は問題ありませんでした。
しかし、クラスターに組み込むと正常に動作しません。
現時点でのlsblk(list block devices)の内容を確認します。
[root@centos8-str2 ~]# lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT (一部、省略) sdb 8:16 0 50G 0 disk └─sdb1 8:17 0 50G 0 part └─pool-data0 253:3 0 50G 0 lvmdrbd0が存在していません。
再度、DRBD用のディスクを作成します。
[root@centos8-str2 ~]# vgremove -f pool [root@centos8-str2 ~]# parted /dev/sdb mklabel msdos 警告: いま存在している /dev/sdb のディスクラベルは破壊され、このディスクの全データが失われます。続行しますか? はい(Y)/Yes/いいえ(N)/No? Y 通知: 必要であれば /etc/fstab を更新するのを忘れないようにしてください。 [root@centos8-str2 ~]# parted /dev/sdb mkpart primary 0% 100% 通知: 必要であれば /etc/fstab を更新するのを忘れないようにしてください。 [root@centos8-str2 ~]# parted /dev/sdb set 1 lvm on 通知: 必要であれば /etc/fstab を更新するのを忘れないようにしてください。 [root@centos8-str2 ~]# pvcreate /dev/sdb1 Physical volume "/dev/sdb1" successfully created. [root@centos8-str2 ~]# vgcreate pool /dev/sdb1 Volume group "pool" successfully created [root@centos8-str2 ~]# lvcreate -n data0 -l 100%FREE pool Logical volume "data0" created.が、しかし、再起動すると正常に動作しません。
問題が発生しているサーバ単体でクラスターをセットアップし、下記コマンドを実行したところエラーとなりました。
[root@centos8-str2 ~]# pcs resource create DRBD_r0 ocf:linbit:drbd drbd_resource=r0 Error: Agent 'ocf:linbit:drbd' is not installed or does not provide valid metadata: Element content failed to validate content, line 117, use --force to override Error: Errors have occurred, therefore pcs is unable to continue [root@centos8-str2 ~]# pcs resource create DRBD_r0 ocf:linbit:drbd drbd_resource=r0 --force Warning: Agent 'ocf:linbit:drbd' is not installed or does not provide valid metadata: Element content failed to validate content, line 117「ocf:linbit:drbd」がインストールされていないとのこと。
[root@centos8-str2 ~]# ll /usr/lib/ocf/resource.d/linbit/drbd -rwxr-xr-x 1 root root 56408 12月 15 07:47 /usr/lib/ocf/resource.d/linbit/drbd [root@centos8-str2 ~]# rpm -qf /usr/lib/ocf/resource.d/linbit/drbd drbd90-utils-9.19.1-1.el8.elrepo.x86_64しかし、上記から分かるとおりDRBD90は正常にインストールされています。
問題が発生しているサーバでは、該当製品はインストール(何度もインストールした)されているのですが、削除・再インストールします。
が、結局、クラスタでの制御が出来なくなってしまいました。
手も足も出ませんので、問題が発生しているサーバのカーネルを最新バージョン(2022年1月14日現在)にアップデートします。
# uname -r 4.18.0-358.el8.x86_64DRBDは正常に動作し、他方のクラスタサーバと同期できました。
しかし、クラスターでDRBDに関するリソースを追加しようすると、カーネルバージョンアップ前と同様のエラーとなりました。
[root@centos8-str2 ~]# pcs resource create DRBD_r0 ocf:linbit:drbd drbd_resource=r0 Error: Agent 'ocf:linbit:drbd' is not installed or does not provide valid metadata: Element content failed to validate content, line 117, use --force to override Error: Errors have occurred, therefore pcs is unable to continue [root@centos8-str2 ~]# pcs resource create DRBD_r0 ocf:linbit:drbd drbd_resource=r0 --force Warning: Agent 'ocf:linbit:drbd' is not installed or does not provide valid metadata: Element content failed to validate content, line 117インターネット上の情報で「Downgrading to pcs-0.10.11-1.el8 the issue is not present.」と記載があったので試してみます。
pcsのバージョンを「0.10.11-1」までダウングレードします。
pcsをダウングレードしただけではクラスタは思ったとおり動作しませんでした。
drbd90-utils及びkmod-drbd90を削除・再インストールします。
すると、参照できなかった「ocf:linbit:drbd」を参照できるようになりました。
[root@centos8-str2 ~]# pcs resource describe ocf:linbit:drbd Error: Agent 'ocf:linbit:drbd' is not installed or does not provide valid metadata: Element content failed to validate content, line 117 Error: Errors have occurred, therefore pcs is unable to continue [root@centos8-str2 ~]# pcs resource describe ocf:linbit:drbd ocf:linbit:drbd - Manages a DRBD device as a Master/Slave resource This resource agent manages a DRBD resource as a master/slave resource. DRBD is a shared-nothing replicated storage device. NOTE: To avoid data-divergence, you should enable either DRBD "quorum" and "on-no-quorum io-error" (recommended), or configure proper fencing policies in both DRBD *and* Pacemaker (fencing resource-and-stonith). This cannot be done from this resource agent alone. (以下、省略)もしかしたら、クラスターが正常に動作するかもしれません。DRBDに関する設定をします。
設定してクラスタを起動させますが、これまでと同じエラーとなり動作しませんでした。
●仮想サーバ上でblk_update_requestを検知
仮想サーバ上でDEBDを動作させているのですが、Zabbixより「blk_update_request」を検知したメールが飛んできました。
エラーを検知したサーバ上で確認します。
[root@centos8-str3 ~]# drbdadm status r0
r0 role:Secondary
disk:Diskless
centos8-str4 role:Primary
peer-disk:UpToDate
ディスクの状態が「Diskless」になってしまっています。
システムログも確認します。
Oct 24 20:46:17 centos8-str3 kernel: sd 0:0:0:0: [sda] tag#65 FAILED Result: hostbyte=DID_OK driverbyte=DRIVER_SENSE cmd_age=35s
Oct 24 20:46:17 centos8-str3 kernel: sd 0:0:0:0: [sda] tag#65 Sense Key : Hardware Error [current]
Oct 24 20:46:17 centos8-str3 kernel: sd 0:0:0:0: [sda] tag#65 Add. Sense: Internal target failure
Oct 24 20:46:17 centos8-str3 kernel: sd 0:0:0:0: [sda] tag#65 CDB: Write(10) 2a 00 3c 52 55 e0 00 00 10 00
Oct 24 20:46:17 centos8-str3 kernel: blk_update_request: critical target error, dev sda, sector 1012028896 op 0x1:(WRITE) flags 0x100000 phys_seg 2 prio class 0
Oct 24 20:46:17 centos8-str3 kernel: dm-0: writeback error on inode 201481807, offset 0, sector 110257632
Oct 24 20:46:21 centos8-str3 kernel: dm-0: writeback error on inode 201481804, offset 0, sector 110257640
Oct 24 20:46:21 centos8-str3 kernel: drbd r0 centos8-str4: sock was shut down by peer
Oct 24 20:46:21 centos8-str3 kernel: drbd r0 centos8-str4: conn( Connected -> BrokenPipe ) peer( Primary -> Unknown )
Oct 24 20:46:21 centos8-str3 kernel: drbd r0/0 drbd0: disk( UpToDate -> Consistent )
Oct 24 20:46:21 centos8-str3 kernel: drbd r0/0 drbd0 centos8-str4: pdsk( UpToDate -> DUnknown ) repl( Established -> Off )
Oct 24 20:46:21 centos8-str3 kernel: drbd r0 centos8-str4: ack_receiver terminated
Oct 24 20:46:21 centos8-str3 kernel: drbd r0 centos8-str4: Terminating ack_recv thread
Oct 24 20:46:21 centos8-str3 kernel: drbd r0 centos8-str4: Terminating sender thread
Oct 24 20:46:21 centos8-str3 kernel: drbd r0 centos8-str4: Starting sender thread (from drbd_r_r0 [16434])
Oct 24 20:46:29 centos8-str3 kernel: drbd r0: Preparing cluster-wide state change 3633269163 (0->-1 0/0)
Oct 24 20:46:29 centos8-str3 kernel: drbd r0: Committing cluster-wide state change 3633269163 (0ms)
Oct 24 20:46:29 centos8-str3 kernel: drbd r0/0 drbd0: disk( Consistent -> UpToDate )
Oct 24 20:46:29 centos8-str3 kernel: drbd r0 centos8-str4: Connection closed
Oct 24 20:46:29 centos8-str3 kernel: drbd r0 centos8-str4: helper command: /sbin/drbdadm disconnected
Oct 24 20:46:29 centos8-str3 kernel: drbd r0 centos8-str4: helper command: /sbin/drbdadm disconnected exit code 0
Oct 24 20:46:29 centos8-str3 kernel: drbd r0 centos8-str4: conn( BrokenPipe -> Unconnected )
Oct 24 20:46:29 centos8-str3 kernel: drbd r0 centos8-str4: Restarting receiver thread
Oct 24 20:46:29 centos8-str3 kernel: drbd r0 centos8-str4: conn( Unconnected -> Connecting )
Oct 24 20:46:29 centos8-str3 kernel: drbd r0 centos8-str4: Handshake to peer 1 successful: Agreed network protocol version 121
Oct 24 20:46:29 centos8-str3 kernel: drbd r0 centos8-str4: Feature flags enabled on protocol level: 0xf TRIM THIN_RESYNC WRITE_SAME WRITE_ZEROES.
Oct 24 20:46:29 centos8-str3 kernel: drbd r0 centos8-str4: Starting ack_recv thread (from drbd_r_r0 [16434])
Oct 24 20:46:29 centos8-str3 kernel: drbd r0: Preparing cluster-wide state change 4036694197 (0->1 499/146)
Oct 24 20:46:29 centos8-str3 kernel: drbd r0/0 drbd0 centos8-str4: drbd_sync_handshake:
Oct 24 20:46:29 centos8-str3 kernel: drbd r0/0 drbd0 centos8-str4: self C7D1AC4DA78335DA:0000000000000000:C52A48D39D54ADAE:C2FD9CE6F3A6844A bits:0 flags:120
Oct 24 20:46:29 centos8-str3 kernel: drbd r0/0 drbd0 centos8-str4: peer 82BEC97C2C28ADE9:C7D1AC4DA78335DB:494E7C557F4336A2:70F41924EC96F6E0 bits:2418 flags:120
Oct 24 20:46:29 centos8-str3 kernel: drbd r0/0 drbd0 centos8-str4: uuid_compare()=target-use-bitmap by rule=bitmap-peer
Oct 24 20:46:29 centos8-str3 kernel: drbd r0: State change 4036694197: primary_nodes=2, weak_nodes=FFFFFFFFFFFFFFFC
Oct 24 20:46:29 centos8-str3 kernel: drbd r0: Committing cluster-wide state change 4036694197 (6ms)
Oct 24 20:46:29 centos8-str3 kernel: drbd r0 centos8-str4: conn( Connecting -> Connected ) peer( Unknown -> Primary )
Oct 24 20:46:29 centos8-str3 kernel: drbd r0/0 drbd0: disk( UpToDate -> Outdated )
Oct 24 20:46:29 centos8-str3 kernel: drbd r0/0 drbd0 centos8-str4: pdsk( DUnknown -> UpToDate ) repl( Off -> WFBitMapT )
Oct 24 20:46:32 centos8-str3 kernel: drbd r0/0 drbd0 centos8-str4: receive bitmap stats [Bytes(packets)]: plain 0(0), RLE 1020(1), total 1020; compression: 100.0%
Oct 24 20:46:32 centos8-str3 kernel: drbd r0/0 drbd0 centos8-str4: send bitmap stats [Bytes(packets)]: plain 0(0), RLE 1020(1), total 1020; compression: 100.0%
Oct 24 20:46:32 centos8-str3 kernel: drbd r0/0 drbd0 centos8-str4: helper command: /sbin/drbdadm before-resync-target
Oct 24 20:46:32 centos8-str3 kernel: drbd r0/0 drbd0 centos8-str4: helper command: /sbin/drbdadm before-resync-target exit code 0
Oct 24 20:46:32 centos8-str3 kernel: drbd r0/0 drbd0: disk( Outdated -> Inconsistent )
Oct 24 20:46:32 centos8-str3 kernel: drbd r0/0 drbd0 centos8-str4: repl( WFBitMapT -> SyncTarget )
Oct 24 20:46:32 centos8-str3 kernel: drbd r0/0 drbd0 centos8-str4: Began resync as SyncTarget (will sync 9672 KB [2418 bits set]).
Oct 24 20:46:21 centos8-str4 kernel: drbd r0/0 drbd0 centos8-str3: Remote failed to finish a request within 42244ms > ko-count (7) * timeout (60 * 0.1s)
Oct 24 20:46:21 centos8-str4 kernel: drbd r0 centos8-str3: conn( Connected -> Timeout ) peer( Secondary -> Unknown )
Oct 24 20:46:21 centos8-str4 kernel: drbd r0/0 drbd0 centos8-str3: pdsk( UpToDate -> DUnknown ) repl( Established -> Off )
Oct 24 20:46:21 centos8-str4 kernel: drbd r0 centos8-str3: ack_receiver terminated
Oct 24 20:46:21 centos8-str4 kernel: drbd r0 centos8-str3: Terminating ack_recv thread
Oct 24 20:46:21 centos8-str4 kernel: drbd r0 centos8-str3: Terminating sender thread
Oct 24 20:46:21 centos8-str4 kernel: drbd r0 centos8-str3: Starting sender thread (from drbd_r_r0 [7336])
Oct 24 20:46:21 centos8-str4 kernel: drbd r0/0 drbd0: new current UUID: 82BEC97C2C28ADE9 weak: FFFFFFFFFFFFFFFD
Oct 24 20:46:21 centos8-str4 kernel: drbd r0 centos8-str3: Connection closed
Oct 24 20:46:21 centos8-str4 kernel: drbd r0 centos8-str3: helper command: /sbin/drbdadm disconnected
Oct 24 20:46:21 centos8-str4 kernel: drbd r0 centos8-str3: helper command: /sbin/drbdadm disconnected exit code 0
Oct 24 20:46:21 centos8-str4 kernel: drbd r0 centos8-str3: conn( Timeout -> Unconnected )
Oct 24 20:46:21 centos8-str4 kernel: drbd r0 centos8-str3: Restarting receiver thread
Oct 24 20:46:21 centos8-str4 kernel: drbd r0 centos8-str3: conn( Unconnected -> Connecting )
Oct 24 20:46:29 centos8-str4 kernel: drbd r0 centos8-str3: Handshake to peer 0 successful: Agreed network protocol version 121
Oct 24 20:46:29 centos8-str4 kernel: drbd r0 centos8-str3: Feature flags enabled on protocol level: 0xf TRIM THIN_RESYNC WRITE_SAME WRITE_ZEROES.
Oct 24 20:46:29 centos8-str4 kernel: drbd r0 centos8-str3: Starting ack_recv thread (from drbd_r_r0 [7336])
Oct 24 20:46:29 centos8-str4 kernel: drbd r0 centos8-str3: Preparing remote state change 4036694197
Oct 24 20:46:29 centos8-str4 kernel: drbd r0/0 drbd0 centos8-str3: drbd_sync_handshake:
Oct 24 20:46:29 centos8-str4 kernel: drbd r0/0 drbd0 centos8-str3: self 82BEC97C2C28ADE9:C7D1AC4DA78335DB:494E7C557F4336A2:70F41924EC96F6E0 bits:2418 flags:120
Oct 24 20:46:29 centos8-str4 kernel: drbd r0/0 drbd0 centos8-str3: peer C7D1AC4DA78335DA:0000000000000000:C52A48D39D54ADAE:C2FD9CE6F3A6844A bits:0 flags:120
Oct 24 20:46:29 centos8-str4 kernel: drbd r0/0 drbd0 centos8-str3: uuid_compare()=source-use-bitmap by rule=bitmap-self
Oct 24 20:46:29 centos8-str4 kernel: drbd r0 centos8-str3: Committing remote state change 4036694197 (primary_nodes=2)
Oct 24 20:46:29 centos8-str4 kernel: drbd r0 centos8-str3: conn( Connecting -> Connected ) peer( Unknown -> Secondary )
Oct 24 20:46:29 centos8-str4 kernel: drbd r0/0 drbd0 centos8-str3: pdsk( DUnknown -> Consistent ) repl( Off -> WFBitMapS )
Oct 24 20:46:29 centos8-str4 kernel: drbd r0/0 drbd0 centos8-str3: pdsk( Consistent -> Outdated )
Oct 24 20:46:29 centos8-str4 kernel: drbd r0/0 drbd0 centos8-str3: send bitmap stats [Bytes(packets)]: plain 0(0), RLE 1020(1), total 1020; compression: 100.0%
Oct 24 20:46:32 centos8-str4 kernel: drbd r0/0 drbd0 centos8-str3: receive bitmap stats [Bytes(packets)]: plain 0(0), RLE 1020(1), total 1020; compression: 100.0%
Oct 24 20:46:32 centos8-str4 kernel: drbd r0/0 drbd0 centos8-str3: helper command: /sbin/drbdadm before-resync-source
Oct 24 20:46:32 centos8-str4 kernel: drbd r0/0 drbd0 centos8-str3: helper command: /sbin/drbdadm before-resync-source exit code 0
Oct 24 20:46:32 centos8-str4 kernel: drbd r0/0 drbd0 centos8-str3: pdsk( Outdated -> Inconsistent ) repl( WFBitMapS -> SyncSource )
Oct 24 20:46:32 centos8-str4 kernel: drbd r0/0 drbd0 centos8-str3: Began resync as SyncSource (will sync 10084 KB [2521 bits set]).
Oct 24 20:46:17 centos8-str3 kernel: sd 0:0:0:0: [sda] tag#65 Sense Key : Hardware Error [current]
Oct 24 20:46:17 centos8-str3 kernel: sd 0:0:0:0: [sda] tag#65 Add. Sense: Internal target failure
Oct 24 20:46:17 centos8-str3 kernel: sd 0:0:0:0: [sda] tag#65 CDB: Write(10) 2a 00 3c 52 55 e0 00 00 10 00
Oct 24 20:46:17 centos8-str3 kernel: blk_update_request: critical target error, dev sda, sector 1012028896 op 0x1:(WRITE) flags 0x100000 phys_seg 2 prio class 0
Oct 24 20:46:17 centos8-str3 kernel: dm-0: writeback error on inode 201481807, offset 0, sector 110257632
Oct 24 20:46:21 centos8-str3 kernel: dm-0: writeback error on inode 201481804, offset 0, sector 110257640
Oct 24 20:46:21 centos8-str3 kernel: drbd r0 centos8-str4: sock was shut down by peer
Oct 24 20:46:21 centos8-str3 kernel: drbd r0 centos8-str4: conn( Connected -> BrokenPipe ) peer( Primary -> Unknown )
Oct 24 20:46:21 centos8-str3 kernel: drbd r0/0 drbd0: disk( UpToDate -> Consistent )
Oct 24 20:46:21 centos8-str3 kernel: drbd r0/0 drbd0 centos8-str4: pdsk( UpToDate -> DUnknown ) repl( Established -> Off )
Oct 24 20:46:21 centos8-str3 kernel: drbd r0 centos8-str4: ack_receiver terminated
Oct 24 20:46:21 centos8-str3 kernel: drbd r0 centos8-str4: Terminating ack_recv thread
Oct 24 20:46:21 centos8-str3 kernel: drbd r0 centos8-str4: Terminating sender thread
Oct 24 20:46:21 centos8-str3 kernel: drbd r0 centos8-str4: Starting sender thread (from drbd_r_r0 [16434])
Oct 24 20:46:29 centos8-str3 kernel: drbd r0: Preparing cluster-wide state change 3633269163 (0->-1 0/0)
Oct 24 20:46:29 centos8-str3 kernel: drbd r0: Committing cluster-wide state change 3633269163 (0ms)
Oct 24 20:46:29 centos8-str3 kernel: drbd r0/0 drbd0: disk( Consistent -> UpToDate )
Oct 24 20:46:29 centos8-str3 kernel: drbd r0 centos8-str4: Connection closed
Oct 24 20:46:29 centos8-str3 kernel: drbd r0 centos8-str4: helper command: /sbin/drbdadm disconnected
Oct 24 20:46:29 centos8-str3 kernel: drbd r0 centos8-str4: helper command: /sbin/drbdadm disconnected exit code 0
Oct 24 20:46:29 centos8-str3 kernel: drbd r0 centos8-str4: conn( BrokenPipe -> Unconnected )
Oct 24 20:46:29 centos8-str3 kernel: drbd r0 centos8-str4: Restarting receiver thread
Oct 24 20:46:29 centos8-str3 kernel: drbd r0 centos8-str4: conn( Unconnected -> Connecting )
Oct 24 20:46:29 centos8-str3 kernel: drbd r0 centos8-str4: Handshake to peer 1 successful: Agreed network protocol version 121
Oct 24 20:46:29 centos8-str3 kernel: drbd r0 centos8-str4: Feature flags enabled on protocol level: 0xf TRIM THIN_RESYNC WRITE_SAME WRITE_ZEROES.
Oct 24 20:46:29 centos8-str3 kernel: drbd r0 centos8-str4: Starting ack_recv thread (from drbd_r_r0 [16434])
Oct 24 20:46:29 centos8-str3 kernel: drbd r0: Preparing cluster-wide state change 4036694197 (0->1 499/146)
Oct 24 20:46:29 centos8-str3 kernel: drbd r0/0 drbd0 centos8-str4: drbd_sync_handshake:
Oct 24 20:46:29 centos8-str3 kernel: drbd r0/0 drbd0 centos8-str4: self C7D1AC4DA78335DA:0000000000000000:C52A48D39D54ADAE:C2FD9CE6F3A6844A bits:0 flags:120
Oct 24 20:46:29 centos8-str3 kernel: drbd r0/0 drbd0 centos8-str4: peer 82BEC97C2C28ADE9:C7D1AC4DA78335DB:494E7C557F4336A2:70F41924EC96F6E0 bits:2418 flags:120
Oct 24 20:46:29 centos8-str3 kernel: drbd r0/0 drbd0 centos8-str4: uuid_compare()=target-use-bitmap by rule=bitmap-peer
Oct 24 20:46:29 centos8-str3 kernel: drbd r0: State change 4036694197: primary_nodes=2, weak_nodes=FFFFFFFFFFFFFFFC
Oct 24 20:46:29 centos8-str3 kernel: drbd r0: Committing cluster-wide state change 4036694197 (6ms)
Oct 24 20:46:29 centos8-str3 kernel: drbd r0 centos8-str4: conn( Connecting -> Connected ) peer( Unknown -> Primary )
Oct 24 20:46:29 centos8-str3 kernel: drbd r0/0 drbd0: disk( UpToDate -> Outdated )
Oct 24 20:46:29 centos8-str3 kernel: drbd r0/0 drbd0 centos8-str4: pdsk( DUnknown -> UpToDate ) repl( Off -> WFBitMapT )
Oct 24 20:46:32 centos8-str3 kernel: drbd r0/0 drbd0 centos8-str4: receive bitmap stats [Bytes(packets)]: plain 0(0), RLE 1020(1), total 1020; compression: 100.0%
Oct 24 20:46:32 centos8-str3 kernel: drbd r0/0 drbd0 centos8-str4: send bitmap stats [Bytes(packets)]: plain 0(0), RLE 1020(1), total 1020; compression: 100.0%
Oct 24 20:46:32 centos8-str3 kernel: drbd r0/0 drbd0 centos8-str4: helper command: /sbin/drbdadm before-resync-target
Oct 24 20:46:32 centos8-str3 kernel: drbd r0/0 drbd0 centos8-str4: helper command: /sbin/drbdadm before-resync-target exit code 0
Oct 24 20:46:32 centos8-str3 kernel: drbd r0/0 drbd0: disk( Outdated -> Inconsistent )
Oct 24 20:46:32 centos8-str3 kernel: drbd r0/0 drbd0 centos8-str4: repl( WFBitMapT -> SyncTarget )
Oct 24 20:46:32 centos8-str3 kernel: drbd r0/0 drbd0 centos8-str4: Began resync as SyncTarget (will sync 9672 KB [2418 bits set]).
Oct 24 20:46:21 centos8-str4 kernel: drbd r0/0 drbd0 centos8-str3: Remote failed to finish a request within 42244ms > ko-count (7) * timeout (60 * 0.1s)
Oct 24 20:46:21 centos8-str4 kernel: drbd r0 centos8-str3: conn( Connected -> Timeout ) peer( Secondary -> Unknown )
Oct 24 20:46:21 centos8-str4 kernel: drbd r0/0 drbd0 centos8-str3: pdsk( UpToDate -> DUnknown ) repl( Established -> Off )
Oct 24 20:46:21 centos8-str4 kernel: drbd r0 centos8-str3: ack_receiver terminated
Oct 24 20:46:21 centos8-str4 kernel: drbd r0 centos8-str3: Terminating ack_recv thread
Oct 24 20:46:21 centos8-str4 kernel: drbd r0 centos8-str3: Terminating sender thread
Oct 24 20:46:21 centos8-str4 kernel: drbd r0 centos8-str3: Starting sender thread (from drbd_r_r0 [7336])
Oct 24 20:46:21 centos8-str4 kernel: drbd r0/0 drbd0: new current UUID: 82BEC97C2C28ADE9 weak: FFFFFFFFFFFFFFFD
Oct 24 20:46:21 centos8-str4 kernel: drbd r0 centos8-str3: Connection closed
Oct 24 20:46:21 centos8-str4 kernel: drbd r0 centos8-str3: helper command: /sbin/drbdadm disconnected
Oct 24 20:46:21 centos8-str4 kernel: drbd r0 centos8-str3: helper command: /sbin/drbdadm disconnected exit code 0
Oct 24 20:46:21 centos8-str4 kernel: drbd r0 centos8-str3: conn( Timeout -> Unconnected )
Oct 24 20:46:21 centos8-str4 kernel: drbd r0 centos8-str3: Restarting receiver thread
Oct 24 20:46:21 centos8-str4 kernel: drbd r0 centos8-str3: conn( Unconnected -> Connecting )
Oct 24 20:46:29 centos8-str4 kernel: drbd r0 centos8-str3: Handshake to peer 0 successful: Agreed network protocol version 121
Oct 24 20:46:29 centos8-str4 kernel: drbd r0 centos8-str3: Feature flags enabled on protocol level: 0xf TRIM THIN_RESYNC WRITE_SAME WRITE_ZEROES.
Oct 24 20:46:29 centos8-str4 kernel: drbd r0 centos8-str3: Starting ack_recv thread (from drbd_r_r0 [7336])
Oct 24 20:46:29 centos8-str4 kernel: drbd r0 centos8-str3: Preparing remote state change 4036694197
Oct 24 20:46:29 centos8-str4 kernel: drbd r0/0 drbd0 centos8-str3: drbd_sync_handshake:
Oct 24 20:46:29 centos8-str4 kernel: drbd r0/0 drbd0 centos8-str3: self 82BEC97C2C28ADE9:C7D1AC4DA78335DB:494E7C557F4336A2:70F41924EC96F6E0 bits:2418 flags:120
Oct 24 20:46:29 centos8-str4 kernel: drbd r0/0 drbd0 centos8-str3: peer C7D1AC4DA78335DA:0000000000000000:C52A48D39D54ADAE:C2FD9CE6F3A6844A bits:0 flags:120
Oct 24 20:46:29 centos8-str4 kernel: drbd r0/0 drbd0 centos8-str3: uuid_compare()=source-use-bitmap by rule=bitmap-self
Oct 24 20:46:29 centos8-str4 kernel: drbd r0 centos8-str3: Committing remote state change 4036694197 (primary_nodes=2)
Oct 24 20:46:29 centos8-str4 kernel: drbd r0 centos8-str3: conn( Connecting -> Connected ) peer( Unknown -> Secondary )
Oct 24 20:46:29 centos8-str4 kernel: drbd r0/0 drbd0 centos8-str3: pdsk( DUnknown -> Consistent ) repl( Off -> WFBitMapS )
Oct 24 20:46:29 centos8-str4 kernel: drbd r0/0 drbd0 centos8-str3: pdsk( Consistent -> Outdated )
Oct 24 20:46:29 centos8-str4 kernel: drbd r0/0 drbd0 centos8-str3: send bitmap stats [Bytes(packets)]: plain 0(0), RLE 1020(1), total 1020; compression: 100.0%
Oct 24 20:46:32 centos8-str4 kernel: drbd r0/0 drbd0 centos8-str3: receive bitmap stats [Bytes(packets)]: plain 0(0), RLE 1020(1), total 1020; compression: 100.0%
Oct 24 20:46:32 centos8-str4 kernel: drbd r0/0 drbd0 centos8-str3: helper command: /sbin/drbdadm before-resync-source
Oct 24 20:46:32 centos8-str4 kernel: drbd r0/0 drbd0 centos8-str3: helper command: /sbin/drbdadm before-resync-source exit code 0
Oct 24 20:46:32 centos8-str4 kernel: drbd r0/0 drbd0 centos8-str3: pdsk( Outdated -> Inconsistent ) repl( WFBitMapS -> SyncSource )
Oct 24 20:46:32 centos8-str4 kernel: drbd r0/0 drbd0 centos8-str3: Began resync as SyncSource (will sync 10084 KB [2521 bits set]).
正常な方のサーバ(centos8-str4)のログで「centos8-str3: conn( Connected -> Timeout ) peer( Secondary -> Unknown )」と記録されています。
原因は分かりませんが、何かしら問題が発生したようです。
centos8-str4がDRBDのマスターとなっており。centos8-str3をシャットダウンしても問題ないので、シャットダウンして回復するか確認します。
[root@centos8-str3 ~]# drbdadm status r0
r0 role:Secondary
disk:Inconsistent
centos8-str4 role:Primary
replication:SyncTarget peer-disk:UpToDate done:28.10
[root@centos8-str3 ~]# drbdadm status r0
r0 role:Secondary
disk:Inconsistent
centos8-str4 role:Primary
replication:SyncTarget peer-disk:UpToDate done:68.44
[root@centos8-str3 ~]# drbdadm status r0
r0 role:Secondary
disk:UpToDate
centos8-str4 role:Primary
peer-disk:UpToDate
Primary、Secondaryの関係に無事復旧しました。
シャットダウンではなくcentos8-str3のクラスタの再起動、または、DRBDの再起動を実施することでも復旧したかもしれません。