●Pacemaker、Corosync、Stonithについて
●VMware ESXi 6.7上でCentOS 7 + Pacemaker + Corosyncの設定に挑戦
参考URL:CentOS 7 + Pacemaker + CorosyncでMariaDBをクラスタ化する① (準備・インストール編)
参考URL:Pacemakerの概要
参考URL:VMware ESXiに仮想共有ディスクファイルを作成する
参考URL:
参考URL:【ざっくり概要】Linuxファイルシステムの種類や作成方法まとめ!
ノードの準備
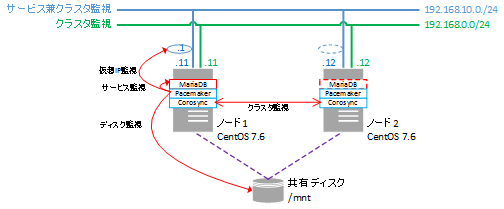
ノード(centos7-1、centos7-2)を準備します。
今回はCentOS 7のカーネルバージョン3.10.0-957.21.3.el7.x86_64でノードを構築します。
VMware Host Clientにログインし、インターコネクト用のネットワーク(名称:Interconnect)を作成します。
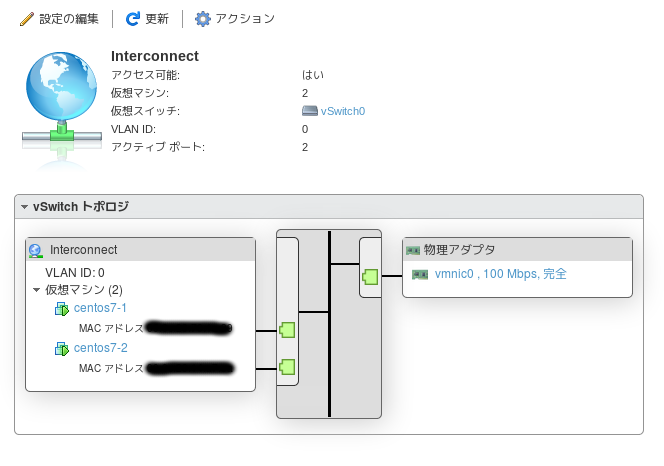
各ノードでインターコネクト用のNIC(ネットワークアダプタ2)を作成します。
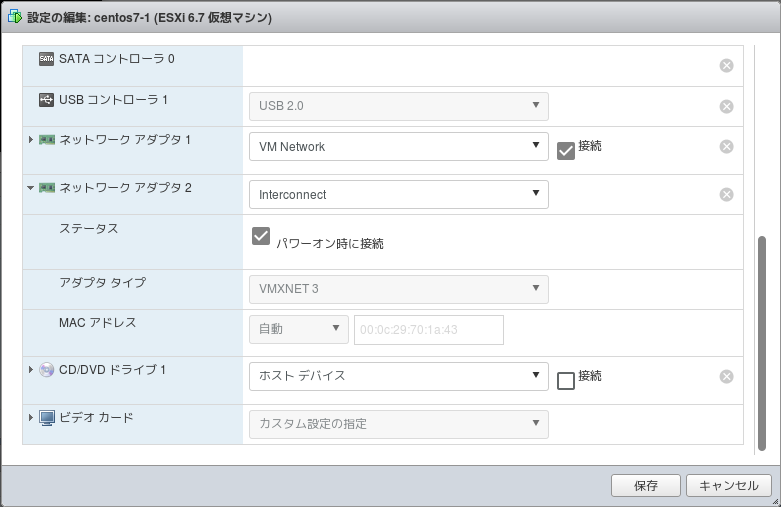
このNICにはPacemakerで使用するインターコネクト用のIPアドレスを割り当てます(例:centos7-1:192.168.0.11、centos7-2:192.168.0.12)。
SELinux及びFirewalldについて操作が不慣れな場合、ノードのSELinux及びFirewalldは無効にしておくことをお薦めします。
共有ディスクの作成
共有ストレージをベースとした仮想ディスクは、VMFSデータストア上でEagerZeroedThickオプションを使用して作成する必要があります。
これらの操作は、コンソール上で、vmkfstoolsコマンドを実行する方法とユーザインターフェースとしてVMware Host Clientを使用する方法があります。
ここでは下記の条件で仮想共有ディスクファイルを作成します。
コンソールより仮想共有ディスクファイルを作成方法
コンソールより仮想共有ディスクファイルを作成するには、下記のようにします。
VMware Host Clientによる仮想共有ディスクファイルの作成方法
下記は同じ(一つの)仮想ディスクを2台の仮想ホストによりSCSIで共有させる(いずれかの仮想ホストからのみマウント)時に実施した方法です。
DRBDを構築する場合、各仮想ホストで同サイズの仮想ディスクを作成し、各仮想ホストに接続する必要がありますので、各仮想ホストで仮想ディスクを新規作成してください。
事前にディレクトリ下記のディレクトリを作成します。
起動後、各ノード(centos7-1、centos7-2)からディスクのデバイスを見ることができるか確認します。
パーティションの設定
デバイスが認識されましたので、ファイルシステムの作成及びパーティションを設定します。
●Pacemaker及びCorosyncのインストール・初期設定(CentOS Stream 8)
参考URL:CentOS 8 + PacemakerでSquidとUnboundを冗長化する
参考URL:CentOS 8.1 (1911)でPacemaker / Corosyncが利用可能に
CentOS 7の場合は「 Pacemaker及びCorosyncのインストール・初期設定 」以降を参照してください。
CentOS 8からクラスタソフトのリポジトリが変更されたようです。
クラスタ用ユーザを設定する。yumでインストールすると、「hacluster」ユーザが作成されているはずなので確認します。
クラスタサービスを利用できるようファイアーウォールを設定します。
※片方のノードで実施
Pacemaker・Corosyncのクラスタを作成(CentOS Stream 8)
172.17.0/24側に仮想IPを設定するため、下記のように実行しました。
クラスタの管理通信の確認は以下コマンドで実施します。2つのリンクが設定されていることがわかります。
クラスタのプロパティを設定(CentOS Stream 8)
参考URL:Pacemaker/Corosync の設定値について
検証目的ですので、STONITHは無効化します。クラスタの設定として、STONITHの無効化を行い、no-quorum-policyをignoreに設定します。
本来、スプリットブレイン発生時の対策として、STONITHは有効化するべきです。
no-quorum-policyについて、通常クォーラムは多数決の原理でアクティブなノードを決定する仕組みですが、2台構成のクラスタの場合は多数決による決定ができません。
この場合、クォーラム設定は「ignore」に設定するのがセオリーのようです。
この時、スプリットブレインが発生したとしても、各ノードのリソースは特に何も制御されないという設定となるため、STONITHによって片方のノードを強制的に電源を落として対応することになります。
リソースエージェントを使ってリソースを構成する(CentOS Stream 8)
参考URL:動かして理解するPacemaker ~CRM設定編~ その2
リソースを制御するために、リソースエージェントを利用します。リソースエージェントとは、クラスタソフトで用意されているリソースの起動・監視・停止を制御するためのスクリプトとなります。
今回の構成では、以下のリソースエージェントを利用します。
起動:「仮想IPアドレス」→「ファイルシステム」→「MariaDB」
停止:「MariaDB」→「ファイルシステム」→「仮想IPアドレス」
この順序を制御するために、リソースの順序を付けてグループ化した「リソースグループ」を作成します。
クラスタの起動(CentOS Stream 8)
クラスタを起動します。
手動フェールオーバーその1(CentOS Stream 8)
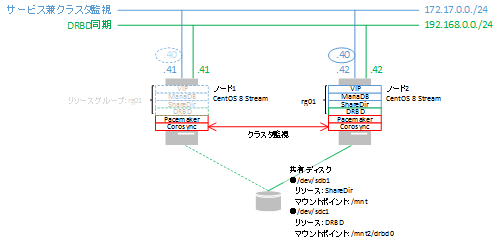
手動でフェールオーバーさせるために、わざわざサーバーを再起動させるのは面倒なので、コマンドでリソースグループをフェールオーバーさせます。
手動フェールオーバーその2(CentOS Stream 8)
コマンドでフェールオーバーさせる手順以外にも、ノードをスタンバイにすることで強制的にリソースグループを移動させることもできます。
サーバーダウン障害(CentOS Stream 8)
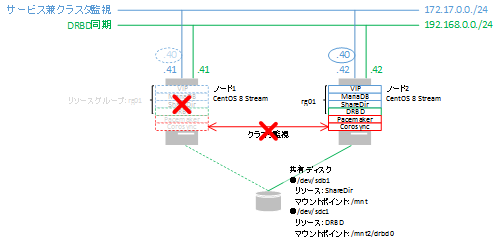
VMware Host Clientにて、仮想マシンの再起動を実施します。
リソースグループrg01が移動していることが分かります。
このままではクラスタとして稼働しませんので、元の状態にするためにクラスタに組み込みます。
NIC障害(CentOS Stream 8)
参考URL:6.6. リソースの動作
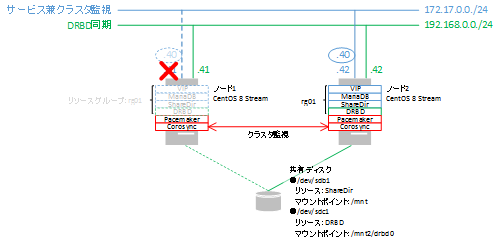
VIPの監視にon-fail=standbyのオプションを指定しないとうまく切り替わらないので、あらかじめ設定しておきます。
切断するNIC(チェックを外します。上手く動作しない場合、完全に削除します。)は仮想IPアドレスが割り当てられるネットワークに属するNICアダプタです。
1分程度でリソースVirtualIPがFAILEDステータスになり、リソースグループがフェールオーバーされます。
その後、障害ノードを復旧させ、クラスタに組み込むために以下コマンドを実行します。
どうやらもともと稼働していたノードのスコアがINFINITYのままになるため、フェイルバックするようです。
この辺りをきちんと制御する意味でも、STONITHの設定を有効にし、障害が発生したノードは強制停止する設定をした方がよいかもしれません。
●PacemakerでZabbix-Serverを制御する(DRBD利用)(CentOS Stream 8)
参考URL:Pacemaker/Corosync の設定値について
参考URL:CentOS8でZabbix5をインストールし、Zabbix Agentを監視する
参考URL:HAクラスタをDRBDとPacemakerで作ってみよう [Pacemaker編]
※この方法でPacemakerを構成した場合、シャットダウンする前に下記を実施してください。
1.スタンバイ側のクラスタ機能の停止
2.Zabbixサーバの停止
3.MariaDBの停止
4.シャットダウンの実施
または
1.Pacemakerの停止
2.シャットダウンの実施
必要なソフトをインストールします(インストール済みの場合、該当作業は不要です)。
Paeemakerで制御されるZabbixで使用するMariaDBのデータベースディレクトリをDRBDを使用してマウントされているディレクトリ上に保存しています。
このDRBDもPacemakerにより制御されます。
DRBDの構築方法については「DRBDの構築について」を参照してください。
MariaDBのデータベースディレクトリの変更方法については「MariaDB(MySQL)のデータベースのフォルダを変更するには(pacemaker、DRBD対応)」を参照してください。
特に記載がない場合、2ホストとも同じ作業を行います。
特定のホストでのみ行う作業は、プロンプトにホスト名を記載します。
DRBDは設定済みとします。
DRBDは自動フェールバックを無効としておかないとDRDBでスプリットブレインが発生し、2台ともStandAlone状態となってしまう場合があります。
この対策のため、自動フェールバックを無効とします(Warningは無視します)。
ファイアーウォールを動作させている場合、各ソフトで使用するポート(http用ポート:80、Zabbix用ポート:10051)を開けてください。
MariaDBは「MariaDB(MySQL)のデータベースのフォルダを変更するには(pacemaker、DRBD対応)」により設定済みとします。
必要なソフトをインストールします(インストール済みの場合、該当作業は不要です)。
Zabbixのデータベース設定(CentOS Stream 8)
MariaDBにログインする。
firewalldの設定
http,Zabbix Agentの通信を許可するために下記のコマンドを実行する。
Zabbixサービス起動
centos8-str1でzabbix-server等を起動します。
Zabbix 5.4インストール時の初期設定画面はこちらです。
Next stepを押下します。

全ての項目が「OK」となっていることを確認してください。
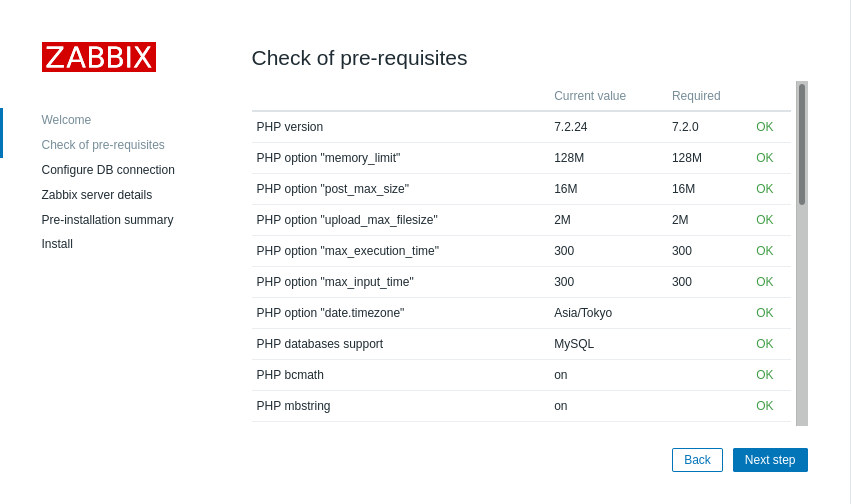

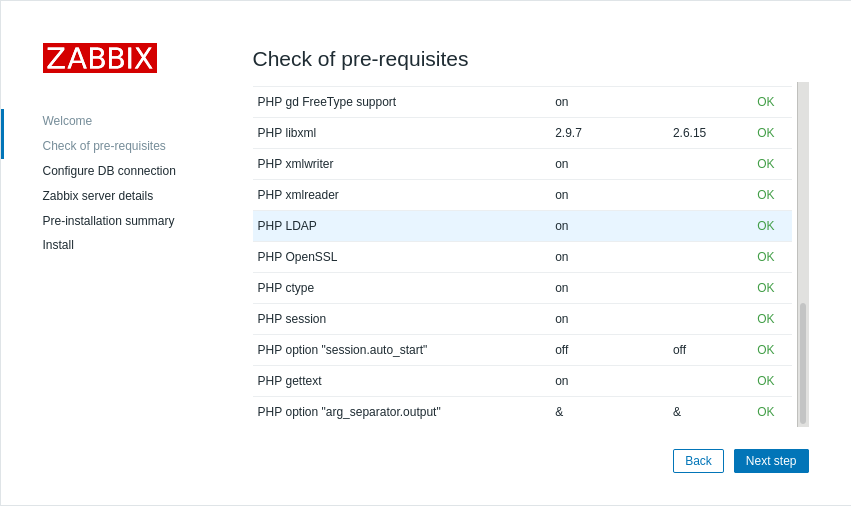
/etc/zabbix/zabbix_server.confで設定した値を入力します。
portは0のままで構いません。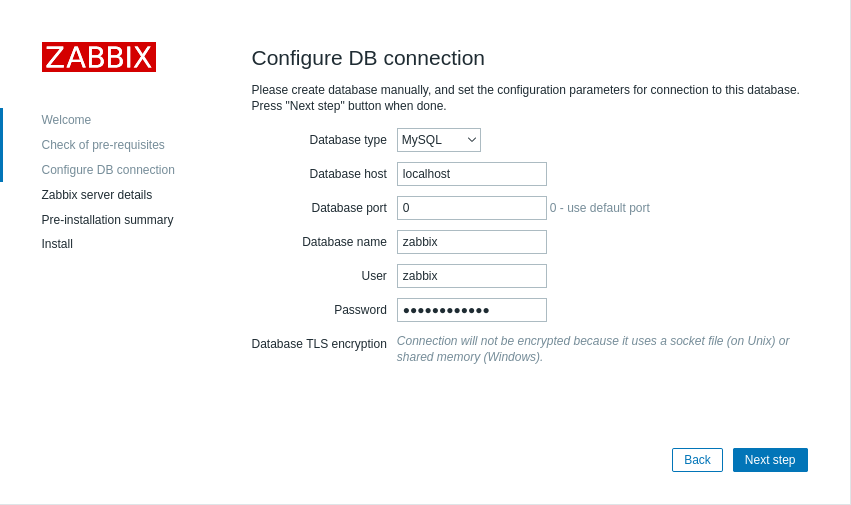
下記ウィンドウではデフォルトのまま次に進みます。
設定情報を確認し、問題なければ次に進みます。

無事設定が完了しました。
デフォルトのユーザ名とパスワードは下記のとおりです。
セットアップ完了後にウィザードによって作成された /etc/zabbix/web/zabbix.conf.php は、centos8-str2にもコピーしておく必要があります。
設定済みのリソースグループ rg01 に追加するので、クラスタ(pcsd)を停止する必要はありません。
●pacemakerの現在のリソースを破棄し、新たな順序でリソースを作成する(CentOS Stream 8)
参考URL:Pacemaker/Corosync の設定値について
pacemakerのリソースを下記のような順序で起動するように(停止はその逆)再設定します。
新たな順序でリソースを作成するため、現在設定されているリソースを削除します。
また、1回の障害検知でフェールオーバーするように設定しています。
プロセスを停止した場合(Apache)(CentOS Stream 8)
参考URL:HAクラスタをDRBDとPacemakerで作ってみよう [Pacemaker編]
httpdを停止します。
fail-countがmigration-thresholdに到達すると、リソースは他のノードで起動します。
今回は制約を設定していますので、原因となるリソース以外も他のノードにフェールオーバーすることになります。
一度、このfail-countをリセットします。
リソースをクリーンアップして綺麗な状態にしておきます。
プロセスを停止した場合(MariaDB)(CentOS Stream 8)
参考URL:HAクラスタをDRBDとPacemakerで作ってみよう [Pacemaker編]
1回でもfail-countがカウントされるとフェールオーバーするように設定していない場合、migration-thresholdのデフォルト値(migration-threshold=1000000)を変更してフェールオーバーするようにします。
MariaDBを停止します。
エラーをクリーンアップし、フェールバックさせます(下記は正常にフェールバックしないパターンです(2021.03.30現在)。)。
下記コマンドを実行しましたが、暫くしても反応がないため Ctrl + C で抜けました。
とりあえず記録されているFailed Resource Actionsをクリーンアップします。
Zabbix ServerがFAILED centos8-str2 (blocked)となる前(timeout前)に、残存しているZabbix Serverのプロセスを全てkillすることでリソースが移動できることを確認しました。
2021.03.31現在、Pacemaker単独でこれを解決する方法が見つからなかったため、cronで1分毎にMariaDBのプロセスがなくなったこと(MariaDBの停止)を検知したら、強制的にZabbix Serverのプロセスを全てkillする方法としました。
下記に記載していますが、Zabbix Serverのプロセス停止時には正常にリソースが移動することを利用することとしました。
プロセスを停止した場合(Zabbix Server)(CentOS Stream 8)
参考URL:HAクラスタをDRBDとPacemakerで作ってみよう [Pacemaker編]
1回でもfail-countがカウントされるとフェールオーバーするように設定していない場合、migration-thresholdのデフォルト値(migration-threshold=1000000)を変更してフェールオーバーするようにします。
Zabbix Serverを停止します。
エラーをクリーンアップし、フェールオーバーさせます。
-
Pcs:Pacemaker/Corosync構成ツール
コマンドラインインターフェースによるpacemaker/corosyncの制御や設定が可能です。
Pacemakerのクラスタについて、作成・表示・変更などを設定できます。 -
Pacemaker:リソース制御機能
-
アプリケーション監視・制御機能
Apache, nginx, Tomcat, JBoss, PostgreSQL, Oracle, MySQL, ファイルシステム制御、仮想IPアドレス制御、等、多数のリソースエージェント(RA)を同梱しています。
また、RAを自作すればどんなアプリケーションでも監視可能です。 -
ネットワーク監視・制御機能
定期的に指定された宛先へpingを送信することでネットワーク接続の正常性を監視できます。 -
ノード監視機能
定期的に互いにハートビート通信を行いノード監視をします。
また、STONITH機能により通信不可となったノードの電源を強制的に停止し、両系稼働状態(スプリットブレイン)を回避できます。 -
自己監視機能
Pacemaker関連プロセスの停止時は影響度合いに応じ適宜、プロセス再起動、またはフェイルオーバを実施します。
また、watchdog機能を併用し、メインプロセス停止時は自動的にOS再起動(およびフェイルオーバ)を実行します。 -
ディスク監視・制御機能
指定されたディスクの読み込みを定期的に実施し、ディスクアクセスの正常性を監視します。
-
アプリケーション監視・制御機能
- Corosync:クラスタ制御機能
-
Stonith:排他制御機能
制御が利かなくなったノードの電源を強制的に停止してクラスタから「強制的に離脱(Fencing)」させる機能のことです。
-
フェンシング(電源断)制御
ipmi(IPMIデバイス用)
libvirt(KVM,Xen等仮想マシン制御用)
ec2(AmazonEC2用)
等
-
サーバ生死確認、相撃ち防止
stonith-helper
-
フェンシング(電源断)制御
●VMware ESXi 6.7上でCentOS 7 + Pacemaker + Corosyncの設定に挑戦
参考URL:CentOS 7 + Pacemaker + CorosyncでMariaDBをクラスタ化する① (準備・インストール編)
参考URL:Pacemakerの概要
参考URL:VMware ESXiに仮想共有ディスクファイルを作成する
参考URL:
参考URL:【ざっくり概要】Linuxファイルシステムの種類や作成方法まとめ!
ノードの準備
ノード(centos7-1、centos7-2)を準備します。
今回はCentOS 7のカーネルバージョン3.10.0-957.21.3.el7.x86_64でノードを構築します。
VMware Host Clientにログインし、インターコネクト用のネットワーク(名称:Interconnect)を作成します。
各ノードでインターコネクト用のNIC(ネットワークアダプタ2)を作成します。
このNICにはPacemakerで使用するインターコネクト用のIPアドレスを割り当てます(例:centos7-1:192.168.0.11、centos7-2:192.168.0.12)。
SELinux及びFirewalldについて操作が不慣れな場合、ノードのSELinux及びFirewalldは無効にしておくことをお薦めします。
共有ディスクの作成
共有ストレージをベースとした仮想ディスクは、VMFSデータストア上でEagerZeroedThickオプションを使用して作成する必要があります。
これらの操作は、コンソール上で、vmkfstoolsコマンドを実行する方法とユーザインターフェースとしてVMware Host Clientを使用する方法があります。
ここでは下記の条件で仮想共有ディスクファイルを作成します。
-
仮想共有ディスクのvmdkファイルを置く場所
/vmfs/volumes/datastore2/com_datastore -
仮想共有ディスクファイル名
com1.vmdk -
仮想共有ディスクの容量
5GB
コンソールより仮想共有ディスクファイルを作成方法
コンソールより仮想共有ディスクファイルを作成するには、下記のようにします。
# ssh vmware password: [root@vmware:~] mkdir /vmfs/volumes/datastore2/com_datastore [root@vmware:~] vmkfstools -d eagerzeroedthick -c 5G /vmfs/volumes/datastore2/com_datastore/com1.vmdkこちらの方法では、VMware Host Client上の設定で共有ディスクの作成時にzeroedthickと認識されてしまい、2つのノードから共有させることができませんでした(原因不明)。
VMware Host Clientによる仮想共有ディスクファイルの作成方法
下記は同じ(一つの)仮想ディスクを2台の仮想ホストによりSCSIで共有させる(いずれかの仮想ホストからのみマウント)時に実施した方法です。
DRBDを構築する場合、各仮想ホストで同サイズの仮想ディスクを作成し、各仮想ホストに接続する必要がありますので、各仮想ホストで仮想ディスクを新規作成してください。
事前にディレクトリ下記のディレクトリを作成します。
# ssh vmware password: [root@vmware:~] mkdir /vmfs/volumes/datastore2/com_datastoreVMware Host Clientからログインし、共有ディスク作成します。 (上記のコマンドによる作成方法では、eagerzeroedthickタイプで認識されませんでした。) 1つ目のノード(centos7-1)で共有ディスクを作成します。
-
新たにSCSIコントローラを作成します。
SCSIバスの共有:仮想
※同一のESXiに存在するノード間でディスクを共有したい場合は「仮想」を選択し、複数のESXiをまたいでディスクを共有したい場合は「物理」を選択する。
-
ハードディスクを追加します。
「ハードディスクの追加」 - 「新規標準ハードディスク」
「新規ハードディスク」の右側の▶をクリックし展開します。
以下は設定した箇所
容量:5GB
場所:[datastore2] com_datastore/com1.vmdk
ディスク プロビジョニング:シック プロビジョニング (Eager Zeroed)
シェア:標準
制限-IOPs:制限なし
コントローラの場所:SCSIコントローラ1 SCSI (1:0)
ディスクモード:独立型:通常
共有:マルチライターの共有
右下の「保存」をクリックすると共有ディスクが作成されます。
2つ目のノード(centos7-2)で上記で作成した共有ディスクを利用してSCSIコントローラ等を作成します。
-
新たにSCSIコントローラを作成します。
SCSIバスの共有:仮想
-
ハードディスクを追加します。
「ハードディスクの追加」 - 「既存のハードディスク」で「[datastore2] com_datastore/com1.vmdk」を選択します。
タイプが「シック プロビジョニング (Lazy Zeroed)」になっていても、この状態のまま一度保存します。
再度、該当VMの設定を開きます。
すると、タイプが「シック プロビジョニング (Eager Zeroed) 」として表示されるはずです。
以下を設定します。
シェア:標準
制限-IOPs:制限なし
コントローラの場所:SCSIコントローラ1 SCSI (1:0)
ディスクモード:独立型:通常
共有:マルチライターの共有
右下の「保存」をクリックします。
起動後、各ノード(centos7-1、centos7-2)からディスクのデバイスを見ることができるか確認します。
■centos7-1で確認 [root@centos7-1 ~]# fdisk -l /dev/sdb Disk /dev/sdb: 5368 MB, 5368709120 bytes, 10485760 sectors Units = sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O サイズ (最小 / 推奨): 512 バイト / 512 バイト ■centos7-2で確認 [root@centos7-2 ~]# fdisk -l /dev/sdb Disk /dev/sdb: 5368 MB, 5368709120 bytes, 10485760 sectors Units = sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O サイズ (最小 / 推奨): 512 バイト / 512 バイト
パーティションの設定
デバイスが認識されましたので、ファイルシステムの作成及びパーティションを設定します。
作成したパーティションをフォーマットします。デバイスを間違えないよう注意してください。[root@centos7-1 ~]# fdisk /dev/sdb Welcome to fdisk (util-linux 2.23.2). Changes will remain in memory only, until you decide to write them. Be careful before using the write command. Device does not contain a recognized partition table Building a new DOS disklabel with disk identifier 0x631b680e. コマンド (m でヘルプ): m コマンドの動作 a toggle a bootable flag b edit bsd disklabel c toggle the dos compatibility flag d delete a partition g create a new empty GPT partition table G create an IRIX (SGI) partition table l list known partition types m print this menu n add a new partition o create a new empty DOS partition table p print the partition table q quit without saving changes s create a new empty Sun disklabel t change a partition's system id u change display/entry units v verify the partition table w write table to disk and exit x extra functionality (experts only) 現時点でのパーティション情報を表示させます。 コマンド (m でヘルプ): p Disk /dev/sdb: 5368 MB, 5368709120 bytes, 10485760 sectors Units = sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O サイズ (最小 / 推奨): 512 バイト / 512 バイト Disk label type: dos ディスク識別子: 0x631b680e デバイス ブート 始点 終点 ブロック Id システム パーティションの設定作業未実施のため、何も表示されません。 パーティションを設定します。 コマンド (m でヘルプ): n Partition type: p primary (0 primary, 0 extended, 4 free) e extended プライマリパーティションとして作成します。 サイズは全領域を指定します。 Select (default p): p パーティション番号 (1-4, default 1): (リターン) 最初 sector (2048-10485759, 初期値 2048): (リターン) 初期値 2048 を使います Last sector, +sectors or +size{K,M,G} (2048-10485759, 初期値 10485759): (リターン) 初期値 10485759 を使います Partition 1 of type Linux and of size 5 GiB is set ファイルシステムが作成されているか確認します。 コマンド (m でヘルプ): p Disk /dev/sdb: 5368 MB, 5368709120 bytes, 10485760 sectors Units = sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O サイズ (最小 / 推奨): 512 バイト / 512 バイト Disk label type: dos ディスク識別子: 0x631b680e デバイス ブート 始点 終点 ブロック Id システム /dev/sdb1 2048 10485759 5241856 83 Linux コマンド (m でヘルプ): w パーティションテーブルは変更されました!
下記コマンドでマウントします。[root@centos7-1 ~]# mkfs.ext4 /dev/sdb1 mke2fs 1.42.9 (28-Dec-2013) Filesystem label= OS type: Linux Block size=4096 (log=2) Fragment size=4096 (log=2) Stride=0 blocks, Stripe width=0 blocks 327680 inodes, 1310464 blocks 65523 blocks (5.00%) reserved for the super user First data block=0 Maximum filesystem blocks=1342177280 40 block groups 32768 blocks per group, 32768 fragments per group 8192 inodes per group Superblock backups stored on blocks: 32768, 98304, 163840, 229376, 294912, 819200, 884736 Allocating group tables: done Writing inode tables: done Creating journal (32768 blocks): done Writing superblocks and filesystem accounting information: done
[root@centos7-1 ~]# mount /dev/sdb1 /mnt
●Pacemaker及びCorosyncのインストール・初期設定(CentOS Stream 8)
参考URL:CentOS 8 + PacemakerでSquidとUnboundを冗長化する
参考URL:CentOS 8.1 (1911)でPacemaker / Corosyncが利用可能に
CentOS 7の場合は「 Pacemaker及びCorosyncのインストール・初期設定 」以降を参照してください。
CentOS 8からクラスタソフトのリポジトリが変更されたようです。
pacemaker及びpcsをインストールします。# dnf repolist all repo id repo の名前 状態 appstream CentOS Stream 8 - AppStream 有効化 baseos CentOS Stream 8 - BaseOS 有効化 debuginfo CentOS Stream 8 - Debuginfo 無効化 epel Extra Packages for Enterprise Linux 8 - x86_64 無効化 epel-debuginfo Extra Packages for Enterprise Linux 8 - x86_64 - Debug 無効化 epel-modular Extra Packages for Enterprise Linux Modular 8 - x86_64 有効化 epel-modular-debuginfo Extra Packages for Enterprise Linux Modular 8 - x86_64 - Debug 無効化 epel-modular-source Extra Packages for Enterprise Linux Modular 8 - x86_64 - Source 無効化 epel-playground Extra Packages for Enterprise Linux 8 - Playground - x86_64 無効化 epel-playground-debuginfo Extra Packages for Enterprise Linux 8 - Playground - x86_64 - Debug 無効化 epel-playground-source Extra Packages for Enterprise Linux 8 - Playground - x86_64 - Source 無効化 epel-source Extra Packages for Enterprise Linux 8 - x86_64 - Source 無効化 epel-testing Extra Packages for Enterprise Linux 8 - Testing - x86_64 無効化 epel-testing-debuginfo Extra Packages for Enterprise Linux 8 - Testing - x86_64 - Debug 無効化 epel-testing-modular Extra Packages for Enterprise Linux Modular 8 - Testing - x86_64 無効化 epel-testing-modular-debuginfo Extra Packages for Enterprise Linux Modular 8 - Testing - x86_64 - Debug 無効化 epel-testing-modular-source Extra Packages for Enterprise Linux Modular 8 - Testing - x86_64 - Source 無効化 epel-testing-source Extra Packages for Enterprise Linux 8 - Testing - x86_64 - Source 無効化 extras CentOS Stream 8 - Extras 有効化 ha CentOS Stream 8 - HighAvailability 無効化 media-appstream CentOS Stream 8 - Media - AppStream 無効化 media-baseos CentOS Stream 8 - Media - BaseOS 無効化 powertools CentOS Stream 8 - PowerTools 無効化 rt CentOS Stream 8 - RealTime 無効化
※両ノードで実施 # dnf --enablerepo=ha install -y pacemaker pcs fence-agents-all/etc/hostsを設定します。
クラスタ用ユーザを設定する。yumでインストールすると、「hacluster」ユーザが作成されているはずなので確認します。
※両ノードで実施 [root@centos8-1 ~]# cat /etc/passwd | grep hacluster hacluster:x:189:189:cluster user:/home/hacluster:/sbin/nologin [root@centos8-2 ~]# cat /etc/passwd | grep hacluster hacluster:x:189:189:cluster user:/home/hacluster:/sbin/nologinパスワードを設定します。両ノードで同一のパスワードです。
※両ノードで実施 # passwd hacluster ユーザ hacluster のパスワードを変更。 新しいパスワード: 新しいパスワードを再入力してください: passwd: すべての認証トークンが正しく更新できました。
# vi /etc/hosts 10.0.0.41 centos8-str1 10.0.0.42 centos8-str2 192.168.0.41 centos8-str1c 192.168.0.42 centos8-str2cクラスタサービスを起動します。
# systemctl enable --now pcsd or # systemctl start pcsd.service # systemctl enable pcsd.service以上でインストール作業は完了です。
クラスタサービスを利用できるようファイアーウォールを設定します。
※両ノードで実施 # firewall-cmd --add-service=high-availability --permanent success # firewall-cmd --reload success以降、クラスタの初期設定を行います。
※片方のノードで実施
[root@centos8-str1 ~]# pcs host auth centos8-str1 centos8-str2 Username: hacluster Password: centos8-str2: Authorized centos8-str1: Authorized
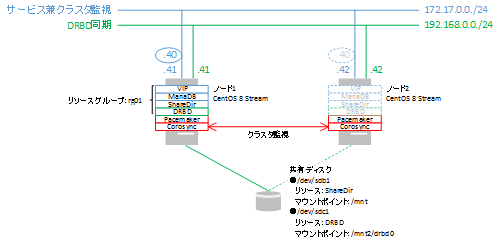
Pacemaker・Corosyncのクラスタを作成(CentOS Stream 8)
172.17.0/24側に仮想IPを設定するため、下記のように実行しました。
[root@centos8-str1 ~]# pcs cluster setup --start bigbang centos8-str1 addr=10.0.0.41 addr=192.168.0.41 \
centos8-str2 addr=10.0.0.42 addr=192.168.0.42
Destroying cluster on hosts: 'centos8-str1', 'centos8-str2'...
centos8-str1: Successfully destroyed cluster
centos8-str2: Successfully destroyed cluster
Requesting remove 'pcsd settings' from 'centos8-str1', 'centos8-str2'
centos8-str1: successful removal of the file 'pcsd settings'
centos8-str2: successful removal of the file 'pcsd settings'
Sending 'corosync authkey', 'pacemaker authkey' to 'centos8-str1', 'centos8-str2'
centos8-str1: successful distribution of the file 'corosync authkey'
centos8-str1: successful distribution of the file 'pacemaker authkey'
centos8-str2: successful distribution of the file 'corosync authkey'
centos8-str2: successful distribution of the file 'pacemaker authkey'
Sending 'corosync.conf' to 'centos8-str1', 'centos8-str2'
centos8-str1: successful distribution of the file 'corosync.conf'
centos8-str2: successful distribution of the file 'corosync.conf'
Cluster has been successfully set up.
Starting cluster on hosts: 'centos8-str1', 'centos8-str2'...
クラスタの初期状態を確認します。
設定したホスト名でクラスタが2台ともオンラインとなっています。[root@centos8-str1 ~]# pcs status Cluster name: bigbang WARNINGS: No stonith devices and stonith-enabled is not false Cluster Summary: * Stack: corosync * Current DC: centos8-str2 (version 2.0.5-8.el8-ba59be7122) - partition with quorum * Last updated: Fri Mar 5 14:33:04 2021 * Last change: Fri Mar 5 14:32:07 2021 by hacluster via crmd on centos8-str2 * 2 nodes configured * 0 resource instances configured Node List: * Online: [ centos8-str1 centos8-str2 ] Full List of Resources: * No resources Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled
クラスタの管理通信の確認は以下コマンドで実施します。2つのリンクが設定されていることがわかります。
[root@centos8-str1 ~]# corosync-cfgtool -s Printing link status. Local node ID 1 LINK ID 0 addr = 10.0.0.41 status: nodeid 1: localhost nodeid 2: connected LINK ID 1 addr = 192.168.0.41 status: nodeid 1: localhost nodeid 2: connected
クラスタのプロパティを設定(CentOS Stream 8)
参考URL:Pacemaker/Corosync の設定値について
-
no-quorum-policy: クラスタがquorumを持っていないときの動作を定義します。デフォルトはstop(全リソース停止)です。
2台構成の場合は、片方が停止しても動作を続行できるよう、ignore(全リソースはそのまま動作を続行)を指定します。 -
stonith-enabled: フェンシング(STONITH)を有効にするかどうかを指定します。デフォルトはtrue(有効)です。
これが有効、かつSTONITHリソースが未設定の場合リソースが起動できません。 -
cluster-recheck-interval: クラスタのチェック間隔を指定します。デフォルトは15分です。
failure-timeout(failcountを自動クリアするまでの時間)など、時間ベースの動作が反映されるまでの時間に影響します。
検証目的ですので、STONITHは無効化します。クラスタの設定として、STONITHの無効化を行い、no-quorum-policyをignoreに設定します。
本来、スプリットブレイン発生時の対策として、STONITHは有効化するべきです。
no-quorum-policyについて、通常クォーラムは多数決の原理でアクティブなノードを決定する仕組みですが、2台構成のクラスタの場合は多数決による決定ができません。
この場合、クォーラム設定は「ignore」に設定するのがセオリーのようです。
この時、スプリットブレインが発生したとしても、各ノードのリソースは特に何も制御されないという設定となるため、STONITHによって片方のノードを強制的に電源を落として対応することになります。
[root@centos8-str1 ~]# pcs property Cluster Properties: cluster-infrastructure: corosync cluster-name: bigbang dc-version: 2.0.5-8.el8-ba59be7122 have-watchdog: false # pcs property set stonith-enabled=false # pcs property set no-quorum-policy=ignore # pcs property Cluster Properties: cluster-infrastructure: corosync cluster-name: bigbang dc-version: 2.0.5-8.el8-ba59be7122 have-watchdog: false no-quorum-policy: ignore stonith-enabled: false自動フェールバックを無効とします(Warningは無視します)。
# pcs resource defaults resource-stickiness=INFINITY Warning: This command is deprecated and will be removed. Please use 'pcs resource defaults update' instead. Warning: Defaults do not apply to resources which override them with their own defined values
リソースエージェントを使ってリソースを構成する(CentOS Stream 8)
参考URL:動かして理解するPacemaker ~CRM設定編~ その2
リソースを制御するために、リソースエージェントを利用します。リソースエージェントとは、クラスタソフトで用意されているリソースの起動・監視・停止を制御するためのスクリプトとなります。
今回の構成では、以下のリソースエージェントを利用します。
- ocf:heartbeat:IPaddr2 : 仮想IPアドレスを制御
- ocf:heartbeat:Filesystem : ファイルシステムのマウントを制御
- systemd:mariadb : MariaDBを制御
# pcs resource describe <リソースエージェント>まず、仮想IPアドレスの設定を行います。付与するIPアドレス・サブネットマスク・NICを指定します。また、interval=30sとして監視間隔を30秒に変更します。
※片方のノードで実施 [root@centos8-str1 ~]# pcs resource create VirtualIP ocf:heartbeat:IPaddr2 ip=10.0.0.140 cidr_netmask=24 nic=ens192 op monitor interval=30sVIP resource を定義 (IPaddr2 は Linux 向けの VIP 設定、場所は /usr/lib/ocf/resource.d/heartbeat/IPaddr2)
- IPaddr
manages virtual IPv4 addresses (portable version) - IPaddr2
manages virtual IPv4 addresses (Linux specific version)
※片方のノードで実施 [root@centos8-str1 ~]# pcs resource create ShareDir ocf:heartbeat:Filesystem device=/dev/sdb1 directory=/mnt fstype=ext4最後にMariaDBの設定です。こちらはシンプルに以下コマンドで設定するだけです。
※片方のノードで実施 [root@centos8-str1 ~]# pcs resource create MariaDB systemd:mariadb上記3つのリソースは起動・停止の順番を考慮する必要があります。
起動:「仮想IPアドレス」→「ファイルシステム」→「MariaDB」
停止:「MariaDB」→「ファイルシステム」→「仮想IPアドレス」
この順序を制御するために、リソースの順序を付けてグループ化した「リソースグループ」を作成します。
※片方のノードで実施 [root@centos8-str1 ~]# pcs resource group add rg01 VirtualIP ShareDir MariaDB以上でリソース設定が完了となりますので、クラスタの設定を確認します。
リソース設定の詳細内容を確認したい場合、下記コマンドを利用します。※片方のノードで実施 [root@centos8-str1 ~]# pcs status Cluster name: bigbang Cluster Summary: * Stack: corosync * Current DC: centos8-str2 (version 2.0.5-8.el8-ba59be7122) - partition with quorum * Last updated: Fri Mar 5 14:38:16 2021 * Last change: Fri Mar 5 14:38:07 2021 by root via cibadmin on centos8-str1 * 2 nodes configured * 3 resource instances configured Node List: * Online: [ centos8-str1 centos8-str2 ] Full List of Resources: * Resource Group: rg01: * VirtualIP (ocf::heartbeat:IPaddr2): Started centos8-str1 * ShareDir (ocf::heartbeat:Filesystem): Started centos8-str1 * MariaDB (systemd:mariadb): Started centos8-str1 Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled
問題なく設定されています。[root@centos8-str1 ~]# pcs resource config Group: rg01 Resource: VirtualIP (class=ocf provider=heartbeat type=IPaddr2) Attributes: cidr_netmask=24 ip=10.0.0.140 nic=ens192 Operations: monitor interval=30s (VirtualIP-monitor-interval-30s) start interval=0s timeout=20s (VirtualIP-start-interval-0s) stop interval=0s timeout=20s (VirtualIP-stop-interval-0s) Resource: ShareDir (class=ocf provider=heartbeat type=Filesystem) Attributes: device=/dev/sdb1 directory=/mnt fstype=ext4 Operations: monitor interval=20s timeout=40s (ShareDir-monitor-interval-20s) start interval=0s timeout=60s (ShareDir-start-interval-0s) stop interval=0s timeout=60s (ShareDir-stop-interval-0s) Resource: MariaDB (class=systemd type=mariadb) Operations: monitor interval=60 timeout=100 (MariaDB-monitor-interval-60) start interval=0s timeout=100 (MariaDB-start-interval-0s) stop interval=0s timeout=100 (MariaDB-stop-interval-0s)
クラスタの起動(CentOS Stream 8)
クラスタを起動します。
[root@centos8-str1 ~]# pcs cluster start --all centos8-str1: Starting Cluster... centos8-str2: Starting Cluster...起動後のステータスを確認します。
[root@centos8-str1 ~]# pcs status Cluster name: bigbang Cluster Summary: * Stack: corosync * Current DC: centos8-str2 (version 2.0.5-8.el8-ba59be7122) - partition with quorum * Last updated: Fri Mar 5 14:45:03 2021 * Last change: Fri Mar 5 14:38:07 2021 by root via cibadmin on centos8-str1 * 2 nodes configured * 3 resource instances configured Node List: * Online: [ centos8-str1 centos8-str2 ] Full List of Resources: * Resource Group: rg01: * VirtualIP (ocf::heartbeat:IPaddr2): Started centos8-str1 * ShareDir (ocf::heartbeat:Filesystem): Started centos8-str1 * MariaDB (systemd:mariadb): Started centos8-str1 Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled
手動フェールオーバーその1(CentOS Stream 8)
手動でフェールオーバーさせるために、わざわざサーバーを再起動させるのは面倒なので、コマンドでリソースグループをフェールオーバーさせます。
[root@centos8-str1 ~]# pcs resource status
* Resource Group: rg01:
* VirtualIP (ocf::heartbeat:IPaddr2): Started centos8-str1
* ShareDir (ocf::heartbeat:Filesystem): Started centos8-str1
* MariaDB (systemd:mariadb): Started centos8-str1
コマンドでリソースグループrg01をノードcentos8-str2に移動させます。
[root@centos8-str1 ~]# pcs resource move rg01 centos8-str2
[root@centos8-str1 ~]# pcs resource move rg01
[root@centos8-str1 ~]# pcs resource clear rg01
リソースグループがcentos8-str2に移動していることが分かります。
[root@centos8-str1 ~]# pcs resource status
* Resource Group: rg01:
* VirtualIP (ocf::heartbeat:IPaddr2): Started centos8-str2
* ShareDir (ocf::heartbeat:Filesystem): Started centos8-str2
* MariaDB (systemd:mariadb): Started centos8-str2
リソースグループをフェイルバックさせます。
[[root@centos8-str1 ~]# pcs resource move rg01 centos8-str1
[root@centos8-str1 ~]# pcs resource move rg01
[root@centos8-str1 ~]# pcs resource clear rg01
元の状態に戻っていることが分かります。
[root@centos8-str1 ~]# pcs resource status
* Resource Group: rg01:
* VirtualIP (ocf::heartbeat:IPaddr2): Started centos8-str1
* ShareDir (ocf::heartbeat:Filesystem): Started centos8-str1
* MariaDB (systemd:mariadb): Started centos8-str1
手動フェールオーバーその2(CentOS Stream 8)
コマンドでフェールオーバーさせる手順以外にも、ノードをスタンバイにすることで強制的にリソースグループを移動させることもできます。
現在リソースグループが起動しているcentos8-str1をスタンバイにします。[root@centos8-str1 ~]# pcs status Cluster name: bigbang Cluster Summary: * Stack: corosync * Current DC: centos8-str2 (version 2.0.5-8.el8-ba59be7122) - partition with quorum * Last updated: Fri Mar 5 14:48:22 2021 * Last change: Fri Mar 5 14:47:55 2021 by root via crm_resource on centos8-str1 * 2 nodes configured * 3 resource instances configured Node List: * Online: [ centos8-str1 centos8-str2 ] Full List of Resources: * Resource Group: rg01: * VirtualIP (ocf::heartbeat:IPaddr2): Started centos8-str1 * ShareDir (ocf::heartbeat:Filesystem): Started centos8-str1 * MariaDB (systemd:mariadb): Started centos8-str1 Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled
[root@centos8-str1 ~]# pcs node standby centos8-str1リソースグループrg01が移動していることが分かります。
リソースグループrg01をフェイルバックさせるには下記のようにします。[root@centos8-str1 ~]# pcs status Cluster name: bigbang Cluster Summary: * Stack: corosync * Current DC: centos8-str2 (version 2.0.5-8.el8-ba59be7122) - partition with quorum * Last updated: Fri Mar 5 14:49:16 2021 * Last change: Fri Mar 5 14:49:04 2021 by root via cibadmin on centos8-str1 * 2 nodes configured * 3 resource instances configured Node List: * Node centos8-str1: standby * Online: [ centos8-str2 ] Full List of Resources: * Resource Group: rg01: * VirtualIP (ocf::heartbeat:IPaddr2): Started centos8-str2 * ShareDir (ocf::heartbeat:Filesystem): Started centos8-str2 * MariaDB (systemd:mariadb): Started centos8-str2 Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled
[root@centos8-str1 ~]# pcs node unstandby centos8-str1 [root@centos8-str1 ~]# pcs node standby centos8-str2 [root@centos8-str1 ~]# pcs node unstandby centos8-str2元に戻っていることが確認できます。
[root@centos8-str1 ~]# pcs status Cluster name: bigbang Cluster Summary: * Stack: corosync * Current DC: centos8-str2 (version 2.0.5-8.el8-ba59be7122) - partition with quorum * Last updated: Fri Mar 5 14:50:19 2021 * Last change: Fri Mar 5 14:50:14 2021 by root via cibadmin on centos8-str1 * 2 nodes configured * 3 resource instances configured Node List: * Online: [ centos8-str1 centos8-str2 ] Full List of Resources: * Resource Group: rg01: * VirtualIP (ocf::heartbeat:IPaddr2): Started centos8-str1 * ShareDir (ocf::heartbeat:Filesystem): Started centos8-str1 * MariaDB (systemd:mariadb): Started centos8-str1 Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled
サーバーダウン障害(CentOS Stream 8)
VMware Host Clientにて、仮想マシンの再起動を実施します。
[root@centos8-str1 ~]# shutdown -r now Connection to centos8-str1 closed by remote host. Connection to centos8-str1 closed.
リソースグループrg01が移動していることが分かります。
障害になったノードは起動後、クラスタに組み込まれていない状態となります。[root@centos8-str2 ~]# pcs status Cluster name: bigbang Cluster Summary: * Stack: corosync * Current DC: centos8-str2 (version 2.0.5-8.el8-ba59be7122) - partition with quorum * Last updated: Fri Mar 5 14:56:47 2021 * Last change: Fri Mar 5 14:50:14 2021 by root via cibadmin on centos8-str1 * 2 nodes configured * 3 resource instances configured Node List: * Online: [ centos8-str2 ] * OFFLINE: [ centos8-str1 ] Full List of Resources: * Resource Group: rg01: * VirtualIP (ocf::heartbeat:IPaddr2): Started centos8-str2 * ShareDir (ocf::heartbeat:Filesystem): Started centos8-str2 * MariaDB (systemd:mariadb): Started centos8-str2 Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled
このままではクラスタとして稼働しませんので、元の状態にするためにクラスタに組み込みます。
[root@centos8-str2 ~]# pcs cluster start centos8-str1 centos8-str1: Starting Cluster...状態を確認すると、元の状態に戻っていることが分かります。
[root@centos8-str2 ~]# pcs statusCluster name: bigbang Cluster Summary: * Stack: corosync * Current DC: centos8-str2 (version 2.0.5-8.el8-ba59be7122) - partition with quorum * Last updated: Fri Mar 5 14:57:50 2021 * Last change: Fri Mar 5 14:50:14 2021 by root via cibadmin on centos8-str1 * 2 nodes configured * 3 resource instances configured Node List: * Online: [ centos8-str1 centos8-str2 ] Full List of Resources: * Resource Group: rg01: * VirtualIP (ocf::heartbeat:IPaddr2): Started centos8-str1 * ShareDir (ocf::heartbeat:Filesystem): Started centos8-str1 * MariaDB (systemd:mariadb): Started centos8-str1 Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled
NIC障害(CentOS Stream 8)
参考URL:6.6. リソースの動作
VIPの監視にon-fail=standbyのオプションを指定しないとうまく切り替わらないので、あらかじめ設定しておきます。
疑似NIC障害を起こすため、仮想マシンのNICを切断(チェックを外します。上手く動作しない場合、完全に削除します。)し保存します。[root@centos8-str1 ~]# pcs resource update VirtualIP op monitor on-fail=standby [root@centos8-str1 ~]# pcs resource config Group: rg01 Resource: VirtualIP (class=ocf provider=heartbeat type=IPaddr2) Attributes: cidr_netmask=24 ip=10.0.0.140 nic=ens192 Operations: monitor interval=60s on-fail=standby (VirtualIP-monitor-interval-60s) start interval=0s timeout=20s (VirtualIP-start-interval-0s) stop interval=0s timeout=20s (VirtualIP-stop-interval-0s) Resource: ShareDir (class=ocf provider=heartbeat type=Filesystem) Attributes: device=/dev/sdb1 directory=/mnt fstype=ext4 Operations: monitor interval=20s timeout=40s (ShareDir-monitor-interval-20s) start interval=0s timeout=60s (ShareDir-start-interval-0s) stop interval=0s timeout=60s (ShareDir-stop-interval-0s) Resource: MariaDB (class=systemd type=mariadb) Operations: monitor interval=60 timeout=100 (MariaDB-monitor-interval-60) start interval=0s timeout=100 (MariaDB-start-interval-0s) stop interval=0s timeout=100 (MariaDB-stop-interval-0s)
切断するNIC(チェックを外します。上手く動作しない場合、完全に削除します。)は仮想IPアドレスが割り当てられるネットワークに属するNICアダプタです。
1分程度でリソースVirtualIPがFAILEDステータスになり、リソースグループがフェールオーバーされます。
削除したネットワークアダプタを復活させます。[root@centos8-str2 ~]# pcs status Cluster name: bigbang Cluster Summary: * Stack: corosync * Current DC: centos8-str2 (version 2.0.5-8.el8-ba59be7122) - partition with quorum * Last updated: Fri Mar 5 15:05:45 2021 * Last change: Fri Mar 5 14:58:41 2021 by root via cibadmin on centos8-str2 * 2 nodes configured * 3 resource instances configured Node List: * Node centos8-str1: standby (on-fail) * Online: [ centos8-str2 ] Full List of Resources: * Resource Group: rg01: * VirtualIP (ocf::heartbeat:IPaddr2): Started centos8-str2 * ShareDir (ocf::heartbeat:Filesystem): Started centos8-str2 * MariaDB (systemd:mariadb): Starting centos8-str2 Failed Resource Actions: * VirtualIP_monitor_60000 on centos8-str1 'not running' (7): call=20, status='complete', exitreason='', \ last-rc-change='2021-03-05 15:05:42 +09:00', queued=0ms, exec=0ms Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled
その後、障害ノードを復旧させ、クラスタに組み込むために以下コマンドを実行します。
上記コマンドでクラスタを復旧させると、リソースグループが元のノードにフェイルバックするので注意が必要です。[root@centos8-str1 ~]# pcs resource cleanup Cleaned up all resources on all nodes Waiting for 1 reply from the controller ... got reply (done) [root@centos8-str1 ~]# pcs status Cluster name: bigbang Cluster Summary: * Stack: corosync * Current DC: centos8-str2 (version 2.0.5-8.el8-ba59be7122) - partition with quorum * Last updated: Fri Mar 5 15:10:57 2021 * Last change: Fri Mar 5 15:10:36 2021 by hacluster via crmd on centos8-str1 * 2 nodes configured * 3 resource instances configured Node List: * Online: [ centos8-str1 centos8-str2 ] Full List of Resources: * Resource Group: rg01: * VirtualIP (ocf::heartbeat:IPaddr2): Started centos8-str1 * ShareDir (ocf::heartbeat:Filesystem): Started centos8-str1 * MariaDB (systemd:mariadb): Started centos8-str1 Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled
どうやらもともと稼働していたノードのスコアがINFINITYのままになるため、フェイルバックするようです。
この辺りをきちんと制御する意味でも、STONITHの設定を有効にし、障害が発生したノードは強制停止する設定をした方がよいかもしれません。
●PacemakerでZabbix-Serverを制御する(DRBD利用)(CentOS Stream 8)
参考URL:Pacemaker/Corosync の設定値について
参考URL:CentOS8でZabbix5をインストールし、Zabbix Agentを監視する
参考URL:HAクラスタをDRBDとPacemakerで作ってみよう [Pacemaker編]
※この方法でPacemakerを構成した場合、シャットダウンする前に下記を実施してください。
1.スタンバイ側のクラスタ機能の停止
2.Zabbixサーバの停止
3.MariaDBの停止
4.シャットダウンの実施
または
1.Pacemakerの停止
2.シャットダウンの実施
必要なソフトをインストールします(インストール済みの場合、該当作業は不要です)。
# dnf install httpd php php-fpm php-mbstring # vi /etc/php.ini date.timezone ="Asia/Tokyo" # dnf install httpdZabbix用のデータベースにMariaDBを利用します。
Paeemakerで制御されるZabbixで使用するMariaDBのデータベースディレクトリをDRBDを使用してマウントされているディレクトリ上に保存しています。
このDRBDもPacemakerにより制御されます。
DRBDの構築方法については「DRBDの構築について」を参照してください。
MariaDBのデータベースディレクトリの変更方法については「MariaDB(MySQL)のデータベースのフォルダを変更するには(pacemaker、DRBD対応)」を参照してください。
特に記載がない場合、2ホストとも同じ作業を行います。
特定のホストでのみ行う作業は、プロンプトにホスト名を記載します。
DRBDは設定済みとします。
DRBDは自動フェールバックを無効としておかないとDRDBでスプリットブレインが発生し、2台ともStandAlone状態となってしまう場合があります。
この対策のため、自動フェールバックを無効とします(Warningは無視します)。
# pcs resource defaults resource-stickiness=INFINITY Warning: This command is deprecated and will be removed. Please use 'pcs resource defaults update' instead. Warning: Defaults do not apply to resources which override them with their own defined valuesクラスタのプロパティは下記を設定済みです。
# pcs property set stonith-enabled=false # pcs property set no-quorum-policy=ignoreSELinuxを無効化していない場合、下記のコマンドを実施し、SELinuxを無効化します。
# vi /etc/selinux/config SELINUX=disabledホストを再起動します。
ファイアーウォールを動作させている場合、各ソフトで使用するポート(http用ポート:80、Zabbix用ポート:10051)を開けてください。
MariaDBは「MariaDB(MySQL)のデータベースのフォルダを変更するには(pacemaker、DRBD対応)」により設定済みとします。
必要なソフトをインストールします(インストール済みの場合、該当作業は不要です)。
# dnf install mariadb mariadb-server # rpm -Uvh https://repo.zabbix.com/zabbix/5.0/rhel/8/x86_64/zabbix-release-5.0-1.el8.noarch.rpm # rpm -Uvh https://repo.zabbix.com/zabbix/5.4/rhel/8/x86_64/zabbix-release-5.4-1.el8.noarch.rpm # dnf clean all # dnf install zabbix-server-mysql zabbix-web-mysql zabbix-apache-conf zabbix-agent # dnf install zabbix-server-mysql zabbix-web-service zabbix-sql-scripts zabbix-agent # dnf install zabbix-server-mysql zabbix-web-service zabbix-sql-scripts zabbix-agent zabbix-web-mysql zabbix-apache-conf zabbix-web-japanese zabbix-getcentos8-str1にてMariaDBが起動していることを確認し、Zabbix用のデータベースを作成します。
[root@centos8-str1 ~]# systemctl start mariadb [root@centos8-str1 ~]# systemctl status mariadb [root@centos8-str1 ~]# mysql_secure_installationNOTE: RUNNING ALL PARTS OF THIS SCRIPT IS RECOMMENDED FOR ALL MariaDB SERVERS IN PRODUCTION USE! PLEASE READ EACH STEP CAREFULLY! In order to log into MariaDB to secure it, we'll need the current password for the root user. If you've just installed MariaDB, and you haven't set the root password yet, the password will be blank, so you should just press enter here. Enter current password for root (enter for none): OK, successfully used password, moving on... Setting the root password ensures that nobody can log into the MariaDB root user without the proper authorisation. Set root password? [Y/n] Y New password: Re-enter new password: Password updated successfully! Reloading privilege tables.. ... Success! By default, a MariaDB installation has an anonymous user, allowing anyone to log into MariaDB without having to have a user account created for them. This is intended only for testing, and to make the installation go a bit smoother. You should remove them before moving into a production environment. Remove anonymous users? [Y/n] Y ... Success! Normally, root should only be allowed to connect from 'localhost'. This ensures that someone cannot guess at the root password from the network. Disallow root login remotely? [Y/n] Y ... Success! By default, MariaDB comes with a database named 'test' that anyone can access. This is also intended only for testing, and should be removed before moving into a production environment. Remove test database and access to it? [Y/n] Y - Dropping test database... ... Success! - Removing privileges on test database... ... Success! Reloading the privilege tables will ensure that all changes made so far will take effect immediately. Reload privilege tables now? [Y/n] Y ... Success! Cleaning up... All done! If you've completed all of the above steps, your MariaDB installation should now be secure. Thanks for using MariaDB!
Zabbixのデータベース設定(CentOS Stream 8)
MariaDBにログインする。
[root@centos8-str1 ~]# mysql -uroot -pzabbix-serverとPHPの設定を編集しておきます。centos8-str1とcentos8-str2の両ホストで編集しておく必要があります。Enter password: MariaDB [(none)]> create database zabbix character set utf8 collate utf8_bin; MariaDB [(none)]> create user zabbix@localhost identified by 'password'; MariaDB [(none)]> grant all privileges on zabbix.* to zabbix@localhost; MariaDB [(none)]> flush privileges; MariaDB [(none)]> quit [root@centos8-str1 ~]# zcat /usr/share/doc/zabbix-server-mysql*/create.sql.gz | mysql -uzabbix -p zabbix [root@centos8-str1 ~]# zcat /usr/share/doc/zabbix-sql-scripts/mysql/create.sql.gz | mysql -uzabbix zabbix -p Enter password: or [root@centos8-str1 ~]# zcat /usr/share/doc/zabbix-sql-scripts/mysql/create.sql.gz | mysql -uzabbix -p zabbix Enter password:
# vi /etc/zabbix/zabbix_server.conf DBSocket=/mnt2/drbd0/mysql/mysql.sock DBHost=localhost DBName=zabbix DBUser=zabbix DBPassword=yourpassword # vi /etc/zabbix/web/zabbix.conf.php $DB['SERVER'] = 'localhost'; ← 変更前 ↓ $DB['SERVER'] = '127.0.0.1'; ← 変更後 ※このファイルをscpで他方のホストにコピーする場合、所有者に注意してください。 [root@centos8-str2 ~]# ls -la /etc/zabbix/web/zabbix.conf.php -rw------- 1 apache apache 1482 3月 26 18:55 /etc/zabbix/web/zabbix.conf.php アクセス権がapacheでない場合、webフロントエンドで configuration file error permission denied と表示されてログインできなくなります。 # vi /etc/php-fpm.d/zabbix.conf php_value[date.timezone] = "Asia/Tokyo"
firewalldの設定
http,Zabbix Agentの通信を許可するために下記のコマンドを実行する。
# firewall-cmd --add-port=10051/tcp --permanent # firewall-cmd --add-service=http --permanent # systemctl restart firewalld
Zabbixサービス起動
centos8-str1でzabbix-server等を起動します。
[root@centos8-str1 ~]# systemctl restart zabbix-server zabbix-agent httpd php-fpmhttp://centos8-str1のIPアドレス/zabbix/ または http://仮想IPアドレス/zabbix/ へアクセスし、Zabbixのセットアップを進めてください。
Zabbix 5.4インストール時の初期設定画面はこちらです。
Next stepを押下します。
全ての項目が「OK」となっていることを確認してください。
/etc/zabbix/zabbix_server.confで設定した値を入力します。
portは0のままで構いません。
- DBHost=localhost
- DBName=zabbix
- DBUser=zabbix
- DBPassword=yourpassword
下記ウィンドウではデフォルトのまま次に進みます。
設定情報を確認し、問題なければ次に進みます。
無事設定が完了しました。
デフォルトのユーザ名とパスワードは下記のとおりです。
- ユーザ名:Admin
- パスワード:zabbix
セットアップ完了後にウィザードによって作成された /etc/zabbix/web/zabbix.conf.php は、centos8-str2にもコピーしておく必要があります。
[root@centos8-str1 ~]# scp /etc/zabbix/web/zabbix.conf.php centos8-str2:/etc/zabbix/web/zabbix.conf.php root@centos8-str2's password: # vi /etc/zabbix/zabbix_server.conf DBSocket=/mnt2/drbd0/mysql/mysql.sock DBHost=localhost DBName=zabbix DBUser=zabbix DBPassword=yourpassword # vi /etc/zabbix/web/zabbix.conf.php $DB['SERVER'] = 'localhost'; ← 変更前 ↓ $DB['SERVER'] = '127.0.0.1'; ← 変更後 ※このファイルをscpで他方のホストにコピーする場合、所有者に注意してください。 [root@centos8-str2 ~]# ls -la /etc/zabbix/web/zabbix.conf.php -rw------- 1 apache apache 1482 3月 26 18:55 /etc/zabbix/web/zabbix.conf.php アクセス権がapacheでない場合、webフロントエンドで configuration file error permission denied と表示されてログインできなくなります。 # vi /etc/php-fpm.d/zabbix.conf php_value[date.timezone] = "Asia/Tokyo"Zabbixのダッシュボードが表示されるところまでの動作を確認できたら、今後、httpd と zabbix-server はPacemakerで制御したいので、centos8-str1で一時的に起動していたリソースを停止します。
設定済みのリソースグループ rg01 に追加するので、クラスタ(pcsd)を停止する必要はありません。
[root@centos8-str1 ~]# systemctl stop httpd [root@centos8-str1 ~]# systemctl stop zabbix-server現在利用しているリソースグループ rg01 に httpd と zabbix-server を追加します。
[root@centos8-str1 ~]# pcs resource create httpd systemd:httpd --group rg01 [root@centos8-str1 ~]# pcs resource create zabbix-server systemd:zabbix-server --group rg01クラスタ状態を確認します。
[root@centos8-str1 ~]# pcs statusクラスタ設定状態を確認します。Cluster name: bigbang Cluster Summary: * Stack: corosync * Current DC: centos8-str2 (version 2.0.5-8.el8-ba59be7122) - partition with quorum * Last updated: Thu Mar 25 15:47:26 2021 * Last change: Thu Mar 25 15:47:08 2021 by root via cibadmin on centos8-str1 * 2 nodes configured * 8 resource instances configured Node List: * Online: [ centos8-str1 centos8-str2 ] Full List of Resources: * Resource Group: rg01: * VirtualIP (ocf::heartbeat:IPaddr2): Started centos8-str1 * ShareDir (ocf::heartbeat:Filesystem): Started centos8-str1 * MariaDB (systemd:mariadb): Started centos8-str1 * FS_DRBD0 (ocf::heartbeat:Filesystem): Started centos8-str1 * httpd (systemd:httpd): Started centos8-str1 * zabbix-server (systemd:zabbix-server): Started centos8-str1 * Clone Set: DRBD-clone [DRBD] (promotable): * Masters: [ centos8-str1 ] * Slaves: [ centos8-str2 ] Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled
[root@centos8-str1 ~]# pcs config showCluster Name: bigbang Corosync Nodes: centos8-str1 centos8-str2 Pacemaker Nodes: centos8-str1 centos8-str2 Resources: Group: rg01 Resource: VirtualIP (class=ocf provider=heartbeat type=IPaddr2) Attributes: cidr_netmask=24 ip=10.0.0.140 nic=ens192 Operations: monitor interval=60s on-fail=standby (VirtualIP-monitor-interval-60s) start interval=0s timeout=20s (VirtualIP-start-interval-0s) stop interval=0s timeout=20s (VirtualIP-stop-interval-0s) Resource: ShareDir (class=ocf provider=heartbeat type=Filesystem) Attributes: device=/dev/sdb1 directory=/mnt fstype=ext4 Operations: monitor interval=20s timeout=40s (ShareDir-monitor-interval-20s) start interval=0s timeout=60s (ShareDir-start-interval-0s) stop interval=0s timeout=60s (ShareDir-stop-interval-0s) Resource: MariaDB (class=systemd type=mariadb) Operations: monitor interval=60 timeout=100 (MariaDB-monitor-interval-60) start interval=0s timeout=100 (MariaDB-start-interval-0s) stop interval=0s timeout=100 (MariaDB-stop-interval-0s) Resource: FS_DRBD0 (class=ocf provider=heartbeat type=Filesystem) Attributes: device=/dev/drbd0 directory=/mnt2/drbd0 fstype=xfs Operations: monitor interval=20s timeout=40s (FS_DRBD0-monitor-interval-20s) start interval=0s timeout=60s (FS_DRBD0-start-interval-0s) stop interval=0s timeout=60s (FS_DRBD0-stop-interval-0s) Resource: httpd (class=systemd type=httpd) Operations: monitor interval=60 timeout=100 (httpd-monitor-interval-60) start interval=0s timeout=100 (httpd-start-interval-0s) stop interval=0s timeout=100 (httpd-stop-interval-0s) Resource: zabbix-server (class=systemd type=zabbix-server) Operations: monitor interval=60 timeout=100 (zabbix-server-monitor-interval-60) start interval=0s timeout=100 (zabbix-server-start-interval-0s) stop interval=0s timeout=100 (zabbix-server-stop-interval-0s) Clone: DRBD-clone Meta Attrs: clone-max=2 clone-node-max=1 master-max=1 master-node-max=1 notify=true promotable=true Resource: DRBD (class=ocf provider=linbit type=drbd) Attributes: drbd_resource=r0 Operations: demote interval=0s timeout=90 (DRBD-demote-interval-0s) monitor interval=20 role=Slave timeout=20 (DRBD-monitor-interval-20) monitor interval=10 role=Master timeout=20 (DRBD-monitor-interval-10) notify interval=0s timeout=90 (DRBD-notify-interval-0s) promote interval=0s timeout=90 (DRBD-promote-interval-0s) reload interval=0s timeout=30 (DRBD-reload-interval-0s) start interval=0s timeout=240 (DRBD-start-interval-0s) stop interval=0s timeout=100 (DRBD-stop-interval-0s) Stonith Devices: Fencing Levels: Location Constraints: Ordering Constraints: promote DRBD-clone then start rg01 (kind:Mandatory) (id:order-DRBD-clone-rg01-mandatory) promote DRBD-clone then start FS_DRBD0 (kind:Mandatory) (id:order-DRBD-clone-FS_DRBD0-mandatory) Colocation Constraints: DRBD-clone with rg01 (score:INFINITY) (rsc-role:Started) (with-rsc-role:Master) (id:colocation-DRBD-clone-rg01-INFINITY) DRBD-clone with FS_DRBD0 (score:INFINITY) (rsc-role:Started) (with-rsc-role:Master) (id:colocation-DRBD-clone-FS_DRBD0-INFINITY) Ticket Constraints: Alerts: No alerts defined Resources Defaults: No defaults set Operations Defaults: No defaults set Cluster Properties: cluster-infrastructure: corosync cluster-name: bigbang dc-version: 2.0.5-8.el8-ba59be7122 have-watchdog: false last-lrm-refresh: 1616654708 no-quorum-policy: ignore stonith-enabled: false Tags: No tags defined Quorum: Options:
●pacemakerの現在のリソースを破棄し、新たな順序でリソースを作成する(CentOS Stream 8)
参考URL:Pacemaker/Corosync の設定値について
pacemakerのリソースを下記のような順序で起動するように(停止はその逆)再設定します。
- DRBDr0
DRBDリソースr0をMaster/Slaveで設定 - FS_DRBD0
/dev/drbd0をxfs形式で/mnt2/drbd0ディレクトリへマウント。DRBDr0のMaster側で稼働 - ShareDir
/dev/sdb1をxfs形式で/mntディレクトリへマウント - MariaDB
FS_DRBD0でマウントされたデータベースを読み込んでMariaDBを起動。Active/Standby。DRBDr0のMaster側で稼働 - VirtualIP
仮想IPの割り当て。DRBDr0のMaster側で稼働 - Apache
httpdサービスを起動。Active/Standby。DRBDr0のMaster側で稼働 - Zabbix-Server
zabbix-serverサービスを起動。Active/Standby。DRBDr0のMaster側で稼働
新たな順序でリソースを作成するため、現在設定されているリソースを削除します。
[root@centos8-str1 ~]# pcs resource remove zabbix-server Attempting to stop: zabbix-server... Stopped [root@centos8-str1 ~]# pcs resource remove httpd Attempting to stop: httpd... Stopped [root@centos8-str1 ~]# pcs resource remove VirtualIP Attempting to stop: VirtualIP... Stopped [root@centos8-str1 ~]# pcs resource remove MariaDB Attempting to stop: MariaDB... Stopped [root@centos8-str1 ~]# pcs resource remove ShareDir Attempting to stop: ShareDir... Stopped [root@centos8-str1 ~]# pcs resource remove FS_DRBD0 Attempting to stop: FS_DRBD0... Stopped [root@centos8-str1 ~]# pcs resource remove DRBD_r0-clone Attempting to stop: DRBD... StoppedDRBD関連の設定は「●DRBDをpacemakerの現在のリソースに追加する」で設定済みです。
また、1回の障害検知でフェールオーバーするように設定しています。
# pcs resource defaults migration-threshold=1リソースを再作成します。
[root@centos8-str1 ~]# pcs resource create DRBD_r0 ocf:linbit:drbd drbd_resource=r0
[root@centos8-str1 ~]# pcs resource promotable DRBD_r0 master-max=1 master-node-max=1 clone-max=2 clone-node-max=1 notify=true
優先的にcentos8-str1がMasterとして起動するようにします。
スコア値が高いほど優先的に起動するようです。
-INFINITY<-100<0<100<INFINITY
[root@centos8-str1 ~]# pcs constraint location DRBD_r0-clone prefers centos8-str1=100
[root@centos8-str1 ~]# pcs resource cleanup DRBD_r0
[root@centos8-str1 ~]# pcs resource create FS_DRBD0 ocf:heartbeat:Filesystem \
device=/dev/drbd0 directory=/mnt2/drbd0 fstype=xfs --group zabbix-group
[root@centos8-str1 ~]# pcs resource create MariaDB systemd:mariadb --group zabbix-group
[root@centos8-str1 ~]# pcs resource create VirtualIP ocf:heartbeat:IPaddr2 ip=10.0.0.140 \
cidr_netmask=24 nic=ens192 op monitor interval=30s --group zabbix-group
[root@centos8-str1 ~]# pcs resource create httpd systemd:httpd --group zabbix-group
[root@centos8-str1 ~]# pcs resource create zabbix-server systemd:zabbix-server --group zabbix-group
[root@centos8-str1 ~]# pcs resource create ShareDir ocf:heartbeat:Filesystem \
device=/dev/sdb1 directory=/mnt fstype=ext4 --group zabbix-group
起動制約設定
## DRBD_r0がMaster側のノードでFS_DRBD0リソースを起動するように設定 [root@centos8-str1 ~]# pcs constraint colocation add DRBD_r0-clone with Master FS_DRBD0 ## DRBD_r0起動後にFS_DRBD0リソースを起動 [root@centos8-str1 ~]# pcs constraint order promote DRBD_r0-clone then start FS_DRBD0 Adding DRBD_r0-clone FS_DRBD0 (kind: Mandatory) (Options: first-action=promote then-action=start) ## zabbix-groupはDRBD_r0のMasterと同じノードで起動 [root@centos8-str1 ~]# pcs constraint colocation add zabbix-group with Master DRBD_r0-clone INFINITY ## MariaDBはDRBD_r0のMasterと同じノードで起動(異常検知で必要) [root@centos8-str1 ~]# pcs constraint colocation add master DRBD_r0 with MariaDB INFINITY --force [root@centos8-str1 ~]# pcs constraint colocation add master DRBD_r0-clone with MariaDB INFINITY ## VirtualIPはDRBD_r0のMasterと同じノードで起動(異常検知で必要) [root@centos8-str1 ~]# pcs constraint colocation add master DRBD_r0 with VirtualIP INFINITY --force [root@centos8-str1 ~]# pcs constraint colocation add master DRBD_r0-clone with VirtualIP INFINITY ## httpdはDRBD_r0のMasterと同じノードで起動(異常検知で必要) [root@centos8-str1 ~]# pcs constraint colocation add master DRBD_r0 with httpd INFINITY --force [root@centos8-str1 ~]# pcs constraint colocation add master DRBD_r0-clone with httpd INFINITY ## zabbix-serverはDRBD_r0のMasterと同じノードで起動(異常検知で必要) [root@centos8-str1 ~]# pcs constraint colocation add master DRBD_r0 with zabbix-server INFINITY --force [root@centos8-str1 ~]# pcs constraint colocation add master DRBD_r0-clone with zabbix-server INFINITY ## ShareDirはDRBD_r0のMasterと同じノードで起動(異常検知で必要):後日追加 [root@centos8-str1 ~]# pcs constraint colocation add master DRBD_r0 with ShareDir INFINITY --force [root@centos8-str1 ~]# pcs constraint colocation add master DRBD_r0-clone with ShareDir INFINITY [root@centos8-str1 ~]# pcs constraint colocation add master DRBD_r0-clone with ShareDir INFINITYクラスタの状態を確認します。
[root@centos8-str1 ~]# pcs statusconfigの状態を確認します。Cluster name: bigbang Cluster Summary: * Stack: corosync * Current DC: centos8-str1 (version 2.0.5-8.el8-ba59be7122) - partition with quorum * Last updated: Mon Mar 29 11:17:19 2021 * Last change: Mon Mar 29 11:10:05 2021 by root via cibadmin on centos8-str1 * 2 nodes configured * 8 resource instances configured Node List: * Online: [ centos8-str1 centos8-str2 ] Full List of Resources: * Clone Set: DRBD_r0-clone [DRBD_r0] (promotable): * Masters: [ centos8-str1 ] * Slaves: [ centos8-str2 ] * Resource Group: zabbix-group: * FS_DRBD0 (ocf::heartbeat:Filesystem): Started centos8-str1 * MariaDB (systemd:mariadb): Started centos8-str1 * VirtualIP (ocf::heartbeat:IPaddr2): Started centos8-str1 * httpd (systemd:httpd): Started centos8-str1 * zabbix-server (systemd:zabbix-server): Started centos8-str1 * ShareDir (ocf::heartbeat:Filesystem): Started centos8-str1 Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled
[root@centos8-str1 ~]# pcs config showCluster Name: bigbang Corosync Nodes: centos8-str1 centos8-str2 Pacemaker Nodes: centos8-str1 centos8-str2 Resources: Clone: DRBD_r0-clone Meta Attrs: clone-max=2 clone-node-max=1 master-max=1 master-node-max=1 notify=true promotable=true Resource: DRBD_r0 (class=ocf provider=linbit type=drbd) Attributes: drbd_resource=r0 Operations: demote interval=0s timeout=90 (DRBD_r0-demote-interval-0s) monitor interval=20 role=Slave timeout=20 (DRBD_r0-monitor-interval-20) monitor interval=10 role=Master timeout=20 (DRBD_r0-monitor-interval-10) notify interval=0s timeout=90 (DRBD_r0-notify-interval-0s) promote interval=0s timeout=90 (DRBD_r0-promote-interval-0s) reload interval=0s timeout=30 (DRBD_r0-reload-interval-0s) start interval=0s timeout=240 (DRBD_r0-start-interval-0s) stop interval=0s timeout=100 (DRBD_r0-stop-interval-0s) Group: zabbix-group Resource: FS_DRBD0 (class=ocf provider=heartbeat type=Filesystem) Attributes: device=/dev/drbd0 directory=/mnt2/drbd0 fstype=xfs Operations: monitor interval=20s timeout=40s (FS_DRBD0-monitor-interval-20s) start interval=0s timeout=60s (FS_DRBD0-start-interval-0s) stop interval=0s timeout=60s (FS_DRBD0-stop-interval-0s) Resource: MariaDB (class=systemd type=mariadb) Operations: monitor interval=60 timeout=100 (MariaDB-monitor-interval-60) start interval=0s timeout=100 (MariaDB-start-interval-0s) stop interval=0s timeout=100 (MariaDB-stop-interval-0s) Resource: VirtualIP (class=ocf provider=heartbeat type=IPaddr2) Attributes: cidr_netmask=24 ip=10.0.0.140 nic=ens192 Operations: monitor interval=30s (VirtualIP-monitor-interval-30s) start interval=0s timeout=20s (VirtualIP-start-interval-0s) stop interval=0s timeout=20s (VirtualIP-stop-interval-0s) Resource: httpd (class=systemd type=httpd) Operations: monitor interval=60 timeout=100 (httpd-monitor-interval-60) start interval=0s timeout=100 (httpd-start-interval-0s) stop interval=0s timeout=100 (httpd-stop-interval-0s) Resource: zabbix-server (class=systemd type=zabbix-server) Operations: monitor interval=60 timeout=100 (zabbix-server-monitor-interval-60) start interval=0s timeout=100 (zabbix-server-start-interval-0s) stop interval=0s timeout=100 (zabbix-server-stop-interval-0s) Resource: ShareDir (class=ocf provider=heartbeat type=Filesystem) Attributes: device=/dev/sdb1 directory=/mnt fstype=ext4 Operations: monitor interval=20s timeout=40s (ShareDir-monitor-interval-20s) start interval=0s timeout=60s (ShareDir-start-interval-0s) stop interval=0s timeout=60s (ShareDir-stop-interval-0s) Stonith Devices: Fencing Levels: Location Constraints: Ordering Constraints: promote DRBD_r0-clone then start FS_DRBD0 (kind:Mandatory) (id:order-DRBD_r0-clone-FS_DRBD0-mandatory) Colocation Constraints: DRBD_r0-clone with FS_DRBD0 (score:INFINITY) (rsc-role:Started) (with-rsc-role:Master) (id:colocation-DRBD_r0-clone-FS_DRBD0-INFINITY) FS_DRBD0 with zabbix-group (score:INFINITY) (rsc-role:Master) (with-rsc-role:Started) (id:colocation-FS_DRBD0-zabbix-group-INFINITY) DRBD_r0 with MariaDB (score:INFINITY) (rsc-role:Master) (with-rsc-role:Started) (id:colocation-DRBD_r0-MariaDB-INFINITY) DRBD_r0 with VirtualIP (score:INFINITY) (rsc-role:Master) (with-rsc-role:Started) (id:colocation-DRBD_r0-VirtualIP-INFINITY) DRBD_r0 with httpd (score:INFINITY) (rsc-role:Master) (with-rsc-role:Started) (id:colocation-DRBD_r0-httpd-INFINITY) DRBD_r0 with zabbix-server (score:INFINITY) (rsc-role:Master) (with-rsc-role:Started) (id:colocation-DRBD_r0-zabbix-server-INFINITY) Ticket Constraints: Alerts: No alerts defined Resources Defaults: Meta Attrs: rsc_defaults-meta_attributes migration-threshold=1 Operations Defaults: No defaults set Cluster Properties: cluster-infrastructure: corosync cluster-name: bigbang dc-version: 2.0.5-8.el8-ba59be7122 have-watchdog: false last-lrm-refresh: 1616983434 no-quorum-policy: ignore stonith-enabled: false Tags: No tags defined Quorum: Options:
プロセスを停止した場合(Apache)(CentOS Stream 8)
参考URL:HAクラスタをDRBDとPacemakerで作ってみよう [Pacemaker編]
httpdを停止します。
[root@centos8-str1 ~]# kill -kill `pgrep -f httpd` [root@centos8-str1 ~]# ps axu | grep http[d] (30秒ほど待ちます。) [root@centos8-str1 ~]# pcs status --fullkillされたhttpdがPacemakerにより再スタートされ、fail-countというカウンターがカウントされます。Cluster name: bigbang Cluster Summary: * Stack: corosync * Current DC: centos8-str1 (version 2.0.5-8.el8-ba59be7122) - partition with quorum * Last updated: Mon Mar 29 13:42:44 2021 * Last change: Mon Mar 29 13:24:34 2021 by hacluster via crmd on centos8-str2 * 2 nodes configured * 8 resource instances configured Node List: * Online: [ centos8-str1 (1) centos8-str2 (2) ] Full List of Resources: * Resource Group: rg01: * FS_DRBD0 (ocf::heartbeat:Filesystem): Started centos8-str1 * ShareDir (ocf::heartbeat:Filesystem): Started centos8-str1 * MariaDB (systemd:mariadb): Started centos8-str1 * VirtualIP (ocf::heartbeat:IPaddr2): Started centos8-str1 * httpd (systemd:httpd): Started centos8-str1 ← pacemakerによって新たに起動されています。 * zabbix-server (systemd:zabbix-server): Started centos8-str1 * Clone Set: DRBD-clone [DRBD] (promotable): * DRBD (ocf::linbit:drbd): Slave centos8-str2 * DRBD (ocf::linbit:drbd): Master centos8-str1 Node Attributes: * Node: centos8-str1 (1): * master-DRBD : 10000 * Node: centos8-str2 (2): * master-DRBD : 10000 Migration Summary: * Node: centos8-str1 (1): * httpd: migration-threshold=1000000 fail-count=1 last-failure='Mon Mar 29 13:42:10 2021' ↑ centos8-str1でhttpdにfail-countが加算されています。 Failed Resource Actions: ← centos8-str1でhttpdが起動していなかった事が記録されています。 * httpd_monitor_60000 on centos8-str1 'not running' (7): call=256, \ status='complete', exitreason='', last-rc-change='2021-03-29 13:42:10 +09:00', queued=0ms, exec=0ms Tickets: PCSD Status: centos8-str1: Online centos8-str2: Online Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled
fail-countがmigration-thresholdに到達すると、リソースは他のノードで起動します。
今回は制約を設定していますので、原因となるリソース以外も他のノードにフェールオーバーすることになります。
一度、このfail-countをリセットします。
[root@centos8-str1 ~]# pcs resource cleanup httpd今度は、migration-thresholdのデフォルト値を変更して、1回でもfail-countがカウントされるとフェールオーバーするようにします。
[root@centos8-str1 ~]# pcs resource defaults migration-threshold=1 Warning: This command is deprecated and will be removed. Please use 'pcs resource defaults update' instead. Warning: Defaults do not apply to resources which override them with their own defined values [root@centos8-str1 ~]# kill -kill `pgrep -f httpd` [root@centos8-str1 ~]# ps axu | grep http[d]他方のホスト(centos8-str2)でApacheを停止させ、元のホスト(centos8-str1)にフェールバックさせます。
[root@centos8-str2 ~]# pkill httpd [root@centos8-str2 ~]# ps axu | grep http[d] (30秒ほど待ちます。) [root@centos8-str2 ~]# pcs status --full元のホスト(centos8-str1)にフェールオーバーしていることが分かります。Cluster name: bigbang Cluster Summary: * Stack: corosync * Current DC: centos8-str1 (1) (version 2.0.5-8.el8-ba59be7122) - partition with quorum * Last updated: Mon Mar 29 13:49:59 2021 * Last change: Mon Mar 29 13:47:34 2021 by hacluster via crmd on centos8-str1 * 2 nodes configured * 8 resource instances configured Node List: * Online: [ centos8-str1 (1) centos8-str2 (2) ] Full List of Resources: * Clone Set: DRBD_r0-clone [DRBD_r0] (promotable): * DRBD_r0 (ocf::linbit:drbd): Master centos8-str1 * DRBD_r0 (ocf::linbit:drbd): Slave centos8-str2 * Resource Group: zabbix-group: * FS_DRBD0 (ocf::heartbeat:Filesystem): Started centos8-str1 * MariaDB (systemd:mariadb): Started centos8-str1 * VirtualIP (ocf::heartbeat:IPaddr2): Started centos8-str1 * httpd (systemd:httpd): Started centos8-str1 * zabbix-server (systemd:zabbix-server): Started centos8-str1 * ShareDir (ocf::heartbeat:Filesystem): Started centos8-str1 Node Attributes: * Node: centos8-str1 (1): * master-DRBD_r0 : 10000 * Node: centos8-str2 (2): * master-DRBD_r0 : 10000 Migration Summary: * Node: centos8-str2 (2): * httpd: migration-threshold=1 fail-count=1 last-failure='Mon Mar 29 13:49:25 2021' Failed Resource Actions: * httpd_monitor_60000 on centos8-str2 'not running' (7): call=134, status='complete', exitreason='', \ last-rc-change='2021-03-29 13:49:24 +09:00', queued=0ms, exec=0ms Tickets: PCSD Status: centos8-str1: Online centos8-str2: Online Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled
リソースをクリーンアップして綺麗な状態にしておきます。
[root@centos8-str1 ~]# pcs resource cleanup httpd
プロセスを停止した場合(MariaDB)(CentOS Stream 8)
参考URL:HAクラスタをDRBDとPacemakerで作ってみよう [Pacemaker編]
1回でもfail-countがカウントされるとフェールオーバーするように設定していない場合、migration-thresholdのデフォルト値(migration-threshold=1000000)を変更してフェールオーバーするようにします。
[root@centos8-str1 ~]# pcs resource defaults migration-threshold=1
MariaDBを停止します。
[root@centos8-str1 ~]# kill -kill `pgrep -f mysqld` [root@centos8-str1 ~]# ps axu | grep mysqld (30秒ほど待ちます。) [root@centos8-str1 ~]# pcs status --fullリソースが他方のホスト(centos8-str2)に移動していることが分かります。Cluster name: bigbang Cluster Summary: * Stack: corosync * Current DC: centos8-str1 (1) (version 2.0.5-8.el8-ba59be7122) - partition with quorum * Last updated: Tue Mar 30 09:40:05 2021 * Last change: Mon Mar 29 18:08:20 2021 by hacluster via crmd on centos8-str2 * 2 nodes configured * 8 resource instances configured Node List: * Online: [ centos8-str1 (1) centos8-str2 (2) ] Full List of Resources: * Clone Set: DRBD_r0-clone [DRBD_r0] (promotable): * DRBD_r0 (ocf::linbit:drbd): Slave centos8-str1 * DRBD_r0 (ocf::linbit:drbd): Master centos8-str2 * Resource Group: zabbix-group: * FS_DRBD0 (ocf::heartbeat:Filesystem): Started centos8-str2 * MariaDB (systemd:mariadb): Started centos8-str2 * VirtualIP (ocf::heartbeat:IPaddr2): Started centos8-str2 * httpd (systemd:httpd): Started centos8-str2 * zabbix-server (systemd:zabbix-server): Started centos8-str2 * ShareDir (ocf::heartbeat:Filesystem): Started centos8-str2 Node Attributes: * Node: centos8-str1 (1): * master-DRBD_r0 : 10000 * Node: centos8-str2 (2): * master-DRBD_r0 : 10000 Migration Summary: * Node: centos8-str1 (1): * MariaDB: migration-threshold=1 fail-count=1 last-failure='Tue Mar 30 09:39:21 2021' Failed Resource Actions: * MariaDB_monitor_60000 on centos8-str1 'not running' (7): call=40, status='complete', exitreason='', \ last-rc-change='2021-03-30 09:39:21 +09:00', queued=0ms, exec=0ms Tickets: PCSD Status: centos8-str1: Online centos8-str2: Online Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled
エラーをクリーンアップし、フェールバックさせます(下記は正常にフェールバックしないパターンです(2021.03.30現在)。)。
[root@centos8-str2 ~]# pcs resource cleanup MariaDB [root@centos8-str2 ~]# kill -kill `pgrep -f mysqld` [root@centos8-str2 ~]# ps axu | grep mysqld (30秒ほど待ちます。) [root@centos8-str2 ~]# pcs status --full;date確認するとZabbix Serverのプロセスが残っています。Cluster name: bigbang Cluster Summary: * Stack: corosync * Current DC: centos8-str1 (1) (version 2.0.5-8.el8-ba59be7122) - partition with quorum * Last updated: Tue Mar 30 10:02:50 2021 * Last change: Tue Mar 30 09:42:57 2021 by hacluster via crmd on centos8-str1 * 2 nodes configured * 8 resource instances configured (1 BLOCKED from further action due to failure) Node List: * Online: [ centos8-str1 (1) centos8-str2 (2) ] Full List of Resources: * Clone Set: DRBD_r0-clone [DRBD_r0] (promotable): * DRBD_r0 (ocf::linbit:drbd): Slave centos8-str1 * DRBD_r0 (ocf::linbit:drbd): Master centos8-str2 * Resource Group: zabbix-group: * FS_DRBD0 (ocf::heartbeat:Filesystem): Started centos8-str2 * MariaDB (systemd:mariadb): FAILED centos8-str2 * VirtualIP (ocf::heartbeat:IPaddr2): Stopped * httpd (systemd:httpd): Stopped * zabbix-server (systemd:zabbix-server): FAILED centos8-str2 (blocked) * ShareDir (ocf::heartbeat:Filesystem): Stopped Node Attributes: * Node: centos8-str1 (1): * master-DRBD_r0 : 10000 * Node: centos8-str2 (2): * master-DRBD_r0 : 10000 Migration Summary: * Node: centos8-str2 (2): * MariaDB: migration-threshold=1 fail-count=1 last-failure='Tue Mar 30 09:44:32 2021' * zabbix-server: migration-threshold=1 fail-count=1000000 last-failure='Tue Mar 30 09:46:14 2021' Failed Resource Actions: * MariaDB_monitor_60000 on centos8-str2 'not running' (7): call=46, status='complete', exitreason='', \ last-rc-change='2021-03-30 09:44:32 +09:00', queued=0ms, exec=0ms * zabbix-server_stop_0 on centos8-str2 'OCF_TIMEOUT' (198): call=64, status='Timed Out', exitreason='', \ last-rc-change='2021-03-30 09:46:14 +09:00', queued=0ms, exec=99987ms Tickets: PCSD Status: centos8-str1: Online centos8-str2: Online Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled
下記コマンドを実行しましたが、暫くしても反応がないため Ctrl + C で抜けました。
[root@centos8-str2 ~]# systemctl stop zabbix-server ^Cその後、下記コマンドを実施したところZabbix Serverの全てのプロセスがなくなりました。
[root@centos8-str2 ~]# kill -kill `pgrep -f zabbix_server`この時点では、まだ、フェールバックしておらず障害状態のままです。
とりあえず記録されているFailed Resource Actionsをクリーンアップします。
[root@centos8-str2 ~]# pcs resource cleanup MariaDB [root@centos8-str2 ~]# pcs resource cleanup zabbix-server [root@centos8-str2 ~]# pcs constraint colocation add MariaDB with zabbix-server INFINITY [root@centos8-str2 ~]# pcs config showこれにより障害は回復しましたが、リソースが移動することはありませんでした。Cluster Name: bigbang Corosync Nodes: centos8-str1 centos8-str2 Pacemaker Nodes: centos8-str1 centos8-str2 Resources: Clone: DRBD_r0-clone Meta Attrs: clone-max=2 clone-node-max=1 master-max=1 master-node-max=1 notify=true promotable=true Resource: DRBD_r0 (class=ocf provider=linbit type=drbd) Attributes: drbd_resource=r0 Operations: demote interval=0s timeout=90 (DRBD_r0-demote-interval-0s) monitor interval=20 role=Slave timeout=20 (DRBD_r0-monitor-interval-20) monitor interval=10 role=Master timeout=20 (DRBD_r0-monitor-interval-10) notify interval=0s timeout=90 (DRBD_r0-notify-interval-0s) promote interval=0s timeout=90 (DRBD_r0-promote-interval-0s) reload interval=0s timeout=30 (DRBD_r0-reload-interval-0s) start interval=0s timeout=240 (DRBD_r0-start-interval-0s) stop interval=0s timeout=100 (DRBD_r0-stop-interval-0s) Group: zabbix-group Resource: FS_DRBD0 (class=ocf provider=heartbeat type=Filesystem) Attributes: device=/dev/drbd0 directory=/mnt2/drbd0 fstype=xfs Operations: monitor interval=20s timeout=40s (FS_DRBD0-monitor-interval-20s) start interval=0s timeout=60s (FS_DRBD0-start-interval-0s) stop interval=0s timeout=60s (FS_DRBD0-stop-interval-0s) Resource: MariaDB (class=systemd type=mariadb) Operations: monitor interval=60 timeout=100 (MariaDB-monitor-interval-60) start interval=0s timeout=100 (MariaDB-start-interval-0s) stop interval=0s timeout=100 (MariaDB-stop-interval-0s) Resource: VirtualIP (class=ocf provider=heartbeat type=IPaddr2) Attributes: cidr_netmask=24 ip=10.0.0.140 nic=ens192 Operations: monitor interval=30s (VirtualIP-monitor-interval-30s) start interval=0s timeout=20s (VirtualIP-start-interval-0s) stop interval=0s timeout=20s (VirtualIP-stop-interval-0s) Resource: httpd (class=systemd type=httpd) Operations: monitor interval=60 timeout=100 (httpd-monitor-interval-60) start interval=0s timeout=100 (httpd-start-interval-0s) stop interval=0s timeout=100 (httpd-stop-interval-0s) Resource: zabbix-server (class=systemd type=zabbix-server) Operations: monitor interval=60 timeout=100 (zabbix-server-monitor-interval-60) start interval=0s timeout=100 (zabbix-server-start-interval-0s) stop interval=0s timeout=100 (zabbix-server-stop-interval-0s) Resource: ShareDir (class=ocf provider=heartbeat type=Filesystem) Attributes: device=/dev/sdb1 directory=/mnt fstype=ext4 Operations: monitor interval=20s timeout=40s (ShareDir-monitor-interval-20s) start interval=0s timeout=60s (ShareDir-start-interval-0s) stop interval=0s timeout=60s (ShareDir-stop-interval-0s) Stonith Devices: Fencing Levels: Location Constraints: Ordering Constraints: promote DRBD_r0-clone then start FS_DRBD0 (kind:Mandatory) (id:order-DRBD_r0-clone-FS_DRBD0-mandatory) Colocation Constraints: DRBD_r0-clone with FS_DRBD0 (score:INFINITY) (rsc-role:Started) (with-rsc-role:Master) (id:colocation-DRBD_r0-clone-FS_DRBD0-INFINITY) FS_DRBD0 with zabbix-group (score:INFINITY) (rsc-role:Master) (with-rsc-role:Started) (id:colocation-FS_DRBD0-zabbix-group-INFINITY) DRBD_r0 with MariaDB (score:INFINITY) (rsc-role:Master) (with-rsc-role:Started) (id:colocation-DRBD_r0-MariaDB-INFINITY) DRBD_r0 with VirtualIP (score:INFINITY) (rsc-role:Master) (with-rsc-role:Started) (id:colocation-DRBD_r0-VirtualIP-INFINITY) DRBD_r0 with httpd (score:INFINITY) (rsc-role:Master) (with-rsc-role:Started) (id:colocation-DRBD_r0-httpd-INFINITY) DRBD_r0 with zabbix-server (score:INFINITY) (rsc-role:Master) (with-rsc-role:Started) (id:colocation-DRBD_r0-zabbix-server-INFINITY) DRBD_r0 with ShareDir (score:INFINITY) (rsc-role:Master) (with-rsc-role:Started) (id:colocation-DRBD_r0-ShareDir-INFINITY) MariaDB with zabbix-server (score:INFINITY) (id:colocation-MariaDB-zabbix-server-INFINITY) Ticket Constraints: Alerts: No alerts defined Resources Defaults: Meta Attrs: rsc_defaults-meta_attributes migration-threshold=1 Operations Defaults: No defaults set Cluster Properties: cluster-infrastructure: corosync cluster-name: bigbang dc-version: 2.0.5-8.el8-ba59be7122 have-watchdog: false last-lrm-refresh: 1617067515 no-quorum-policy: ignore stonith-enabled: false Tags: No tags defined Quorum: Options:
Zabbix ServerがFAILED centos8-str2 (blocked)となる前(timeout前)に、残存しているZabbix Serverのプロセスを全てkillすることでリソースが移動できることを確認しました。
2021.03.31現在、Pacemaker単独でこれを解決する方法が見つからなかったため、cronで1分毎にMariaDBのプロセスがなくなったこと(MariaDBの停止)を検知したら、強制的にZabbix Serverのプロセスを全てkillする方法としました。
下記に記載していますが、Zabbix Serverのプロセス停止時には正常にリソースが移動することを利用することとしました。
プロセスを停止した場合(Zabbix Server)(CentOS Stream 8)
参考URL:HAクラスタをDRBDとPacemakerで作ってみよう [Pacemaker編]
1回でもfail-countがカウントされるとフェールオーバーするように設定していない場合、migration-thresholdのデフォルト値(migration-threshold=1000000)を変更してフェールオーバーするようにします。
[root@centos8-str1 ~]# pcs resource defaults migration-threshold=1
Zabbix Serverを停止します。
[root@centos8-str1 ~]# kill -kill `pgrep -f zabbix_server` [root@centos8-str1 ~]# ps axu | grep zabbix_server (30秒ほど待ちます。) [root@centos8-str1 ~]# pcs status --fullリソースが他方のホスト(centos8-str2)に移動していることが分かります。Cluster name: bigbang Cluster Summary: * Stack: corosync * Current DC: centos8-str1 (1) (version 2.0.5-8.el8-ba59be7122) - partition with quorum * Last updated: Mon Mar 29 17:41:43 2021 * Last change: Mon Mar 29 17:39:12 2021 by hacluster via crmd on centos8-str2 * 2 nodes configured * 8 resource instances configured Node List: * Online: [ centos8-str1 (1) centos8-str2 (2) ] Full List of Resources: * Clone Set: DRBD_r0-clone [DRBD_r0] (promotable): * DRBD_r0 (ocf::linbit:drbd): Slave centos8-str1 * DRBD_r0 (ocf::linbit:drbd): Master centos8-str2 * Resource Group: zabbix-group: * FS_DRBD0 (ocf::heartbeat:Filesystem): Started centos8-str2 * MariaDB (systemd:mariadb): Started centos8-str2 * VirtualIP (ocf::heartbeat:IPaddr2): Started centos8-str2 * httpd (systemd:httpd): Started centos8-str2 * zabbix-server (systemd:zabbix-server): Started centos8-str2 * ShareDir (ocf::heartbeat:Filesystem): Started centos8-str2 Node Attributes: * Node: centos8-str1 (1): * master-DRBD_r0 : 10000 * Node: centos8-str2 (2): * master-DRBD_r0 : 10000 Migration Summary: * Node: centos8-str1 (1): * zabbix-server: migration-threshold=1 fail-count=1 last-failure='Mon Mar 29 17:41:02 2021' Failed Resource Actions: * zabbix-server_monitor_60000 on centos8-str1 'not running' (7): call=298, status='complete', exitreason='', \ last-rc-change='2021-03-29 17:41:02 +09:00', queued=0ms, exec=0ms Tickets: PCSD Status: centos8-str1: Online centos8-str2: Online Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled
エラーをクリーンアップし、フェールオーバーさせます。
[root@centos8-str2 ~]# pcs resource cleanup zabbix-server [root@centos8-str2 ~]# kill -kill `pgrep -f zabbix_server` [root@centos8-str2 ~]# ps axu | grep zabbix_server (30秒ほど待ちます。) [root@centos8-str2 ~]# pcs status --fullCluster name: bigbang Cluster Summary: * Stack: corosync * Current DC: centos8-str1 (1) (version 2.0.5-8.el8-ba59be7122) - partition with quorum * Last updated: Mon Mar 29 17:46:45 2021 * Last change: Mon Mar 29 17:45:27 2021 by hacluster via crmd on centos8-str1 * 2 nodes configured * 8 resource instances configured Node List: * Online: [ centos8-str1 (1) centos8-str2 (2) ] Full List of Resources: * Clone Set: DRBD_r0-clone [DRBD_r0] (promotable): * DRBD_r0 (ocf::linbit:drbd): Master centos8-str1 * DRBD_r0 (ocf::linbit:drbd): Slave centos8-str2 * Resource Group: zabbix-group: * FS_DRBD0 (ocf::heartbeat:Filesystem): Started centos8-str1 * MariaDB (systemd:mariadb): Started centos8-str1 * VirtualIP (ocf::heartbeat:IPaddr2): Started centos8-str1 * httpd (systemd:httpd): Started centos8-str1 * zabbix-server (systemd:zabbix-server): Started centos8-str1 * ShareDir (ocf::heartbeat:Filesystem): Started centos8-str1 Node Attributes: * Node: centos8-str1 (1): * master-DRBD_r0 : 10000 * Node: centos8-str2 (2): * master-DRBD_r0 : 10000 Migration Summary: * Node: centos8-str2 (2): * zabbix-server: migration-threshold=1 fail-count=1 last-failure='Mon Mar 29 17:46:14 2021' Failed Resource Actions: * zabbix-server_monitor_60000 on centos8-str2 'not running' (7): call=304, status='complete', exitreason='', \ last-rc-change='2021-03-29 17:46:14 +09:00', queued=0ms, exec=0ms Tickets: PCSD Status: centos8-str1: Online centos8-str2: Online Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled/リソースをクリーンアップして綺麗な状態にしておきます。[root@centos8-str2 ~]# pcs resource cleanup zabbix-server
NIC障害(VirtualIP)(CentOS Stream 8)
参考URL:HAクラスタをDRBDとPacemakerで作ってみよう [Pacemaker編]
1回でもfail-countがカウントされるとフェールオーバーするように設定していない場合、migration-thresholdのデフォルト値(migration-threshold=1000000)を変更してフェールオーバーするようにします。[root@centos8-str1 ~]# pcs resource defaults migration-threshold=1
VMware Host Clientにログインし、ホスト(centos8-str1)のネットワークアダプタ(VM Network (接続済み))を切断してVirtualIPを停止します。(30秒ほど待ちます。) [root@centos8-str2 ~]# pcs status --full;dateエラーをクリーンアップします。Cluster name: bigbang Cluster Summary: * Stack: corosync * Current DC: centos8-str1 (1) (version 2.0.5-8.el8-ba59be7122) - partition with quorum * Last updated: Mon Mar 29 14:56:56 2021 * Last change: Mon Mar 29 14:42:29 2021 by hacluster via crmd on centos8-str2 * 2 nodes configured * 8 resource instances configured Node List: * Online: [ centos8-str1 (1) centos8-str2 (2) ] Full List of Resources: * Clone Set: DRBD_r0-clone [DRBD_r0] (promotable): * DRBD_r0 (ocf::linbit:drbd): Slave centos8-str1 * DRBD_r0 (ocf::linbit:drbd): Master centos8-str2 * Resource Group: zabbix-group: * FS_DRBD0 (ocf::heartbeat:Filesystem): Started centos8-str2 * MariaDB (systemd:mariadb): Started centos8-str2 * VirtualIP (ocf::heartbeat:IPaddr2): Started centos8-str2 * httpd (systemd:httpd): Started centos8-str2 * zabbix-server (systemd:zabbix-server): Started centos8-str2 * ShareDir (ocf::heartbeat:Filesystem): Started centos8-str2 Node Attributes: * Node: centos8-str1 (1): * master-DRBD_r0 : 10000 * Node: centos8-str2 (2): * master-DRBD_r0 : 10000 Migration Summary: * Node: centos8-str1 (1): * VirtualIP: migration-threshold=1 fail-count=1 last-failure='Mon Mar 29 14:55:16 2021' Failed Resource Actions: * VirtualIP_monitor_30000 on centos8-str1 'not running' (7): call=173, status='complete', exitreason='', \ last-rc-change='2021-03-29 14:55:16 +09:00', queued=0ms, exec=0ms Tickets: PCSD Status: centos8-str1: Offline centos8-str2: Online Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled[root@centos8-str2 ~]# pcs resource cleanup VirtualIPVMware Host Clientにログインし、ホスト(centos8-str1)のネットワークアダプタ(VM Network)を作成しなおします。
ホスト(centos8-str2)のネットワークアダプタ(VM Network (接続済み))を切断しフェールバックさせます。(30秒ほど待ちます。) [root@centos8-str1 ~]# pcs status --fullフェールオーバーしていることが分かります。Cluster name: bigbang Cluster Summary: * Stack: corosync * Current DC: centos8-str1 (1) (version 2.0.5-8.el8-ba59be7122) - partition with quorum * Last updated: Mon Mar 29 15:14:32 2021 * Last change: Mon Mar 29 15:07:40 2021 by hacluster via crmd on centos8-str1 * 2 nodes configured * 8 resource instances configured Node List: * Online: [ centos8-str1 (1) centos8-str2 (2) ] Full List of Resources: * Clone Set: DRBD_r0-clone [DRBD_r0] (promotable): * DRBD_r0 (ocf::linbit:drbd): Master centos8-str1 * DRBD_r0 (ocf::linbit:drbd): Slave centos8-str2 * Resource Group: zabbix-group: * FS_DRBD0 (ocf::heartbeat:Filesystem): Started centos8-str1 * MariaDB (systemd:mariadb): Started centos8-str1 * VirtualIP (ocf::heartbeat:IPaddr2): Started centos8-str1 * httpd (systemd:httpd): Started centos8-str1 * zabbix-server (systemd:zabbix-server): Started centos8-str1 * ShareDir (ocf::heartbeat:Filesystem): Started centos8-str1 Node Attributes: * Node: centos8-str1 (1): * master-DRBD_r0 : 10000 * Node: centos8-str2 (2): * master-DRBD_r0 : 10000 Migration Summary: * Node: centos8-str2 (2): * VirtualIP: migration-threshold=1 fail-count=1 last-failure='Mon Mar 29 15:14:02 2021' Failed Resource Actions: * VirtualIP_monitor_30000 on centos8-str2 'not running' (7): call=179, status='complete', exitreason='', \ last-rc-change='2021-03-29 15:14:02 +09:00', queued=0ms, exec=0ms Tickets: PCSD Status: centos8-str1: Online centos8-str2: Offline Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled
リソースをクリーンアップして綺麗な状態にしておきます。[root@centos8-str1 ~]# pcs resource cleanup VirtualIP
参考URL:HAクラスタをDRBDとPacemakerで作ってみよう [Pacemaker編]
1回でもfail-countがカウントされるとフェールオーバーするように設定していない場合、migration-thresholdのデフォルト値(migration-threshold=1000000)を変更してフェールオーバーするようにします。[root@centos8-str1 ~]# pcs resource defaults migration-threshold=1
ホスト(centos8-str1)のShareDirリソースのマウントを解除します。[root@centos8-str1 ~]# umount /mnt (30秒ほど待ちます。) [root@centos8-str1 ~]# pcs status --full全てのリソースが他方のホスト(centos8-str2)に移動していることが分かります。Cluster name: bigbang Cluster Summary: * Stack: corosync * Current DC: centos8-str1 (1) (version 2.0.5-8.el8-ba59be7122) - partition with quorum * Last updated: Mon Mar 29 16:28:17 2021 * Last change: Mon Mar 29 16:25:19 2021 by root via cibadmin on centos8-str1 * 2 nodes configured * 8 resource instances configured Node List: * Online: [ centos8-str1 (1) centos8-str2 (2) ] Full List of Resources: * Clone Set: DRBD_r0-clone [DRBD_r0] (promotable): * DRBD_r0 (ocf::linbit:drbd): Slave centos8-str1 * DRBD_r0 (ocf::linbit:drbd): Master centos8-str2 * Resource Group: zabbix-group: * FS_DRBD0 (ocf::heartbeat:Filesystem): Started centos8-str2 * MariaDB (systemd:mariadb): Started centos8-str2 * VirtualIP (ocf::heartbeat:IPaddr2): Started centos8-str2 * httpd (systemd:httpd): Started centos8-str2 * zabbix-server (systemd:zabbix-server): Started centos8-str2 * ShareDir (ocf::heartbeat:Filesystem): Started centos8-str2 Node Attributes: * Node: centos8-str1 (1): * master-DRBD_r0 : 10000 * Node: centos8-str2 (2): * master-DRBD_r0 : 10000 Migration Summary: * Node: centos8-str1 (1): * ShareDir: migration-threshold=1 fail-count=1 last-failure='Mon Mar 29 16:26:48 2021' Failed Resource Actions: * ShareDir_monitor_20000 on centos8-str1 'not running' (7): call=218, status='complete', exitreason='', \ last-rc-change='2021-03-29 16:26:48 +09:00', queued=0ms, exec=0ms Tickets: PCSD Status: centos8-str1: Online centos8-str2: Online Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled
エラーをクリーンアップします。[root@centos8-str1 ~]# pcs resource cleanup ShareDirホスト(centos8-str2)ののShareDirリソースのマウントを解除します。[root@centos8-str2 ~]# umount /mnt (30秒ほど待ちます。) [root@centos8-str2 ~]# pcs status --fullフェールオーバーしていることが分かります。Cluster name: bigbang Cluster Summary: * Stack: corosync * Current DC: centos8-str1 (1) (version 2.0.5-8.el8-ba59be7122) - partition with quorum * Last updated: Mon Mar 29 16:40:45 2021 * Last change: Mon Mar 29 16:37:13 2021 by hacluster via crmd on centos8-str1 * 2 nodes configured * 8 resource instances configured Node List: * Online: [ centos8-str1 (1) centos8-str2 (2) ] Full List of Resources: * Clone Set: DRBD_r0-clone [DRBD_r0] (promotable): * DRBD_r0 (ocf::linbit:drbd): Master centos8-str1 * DRBD_r0 (ocf::linbit:drbd): Slave centos8-str2 * Resource Group: zabbix-group: * FS_DRBD0 (ocf::heartbeat:Filesystem): Started centos8-str1 * MariaDB (systemd:mariadb): Started centos8-str1 * VirtualIP (ocf::heartbeat:IPaddr2): Started centos8-str1 * httpd (systemd:httpd): Started centos8-str1 * zabbix-server (systemd:zabbix-server): Started centos8-str1 * ShareDir (ocf::heartbeat:Filesystem): Started centos8-str1 Node Attributes: * Node: centos8-str1 (1): * master-DRBD_r0 : 10000 * Node: centos8-str2 (2): * master-DRBD_r0 : 10000 Migration Summary: * Node: centos8-str2 (2): * ShareDir: migration-threshold=1 fail-count=1 last-failure='Mon Mar 29 16:40:25 2021' Failed Resource Actions: * ShareDir_monitor_20000 on centos8-str2 'not running' (7): call=224, status='complete', exitreason='', \ last-rc-change='2021-03-29 16:40:25 +09:00', queued=0ms, exec=0ms Tickets: PCSD Status: centos8-str1: Online centos8-str2: Online Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled
リソースをクリーンアップして綺麗な状態にしておきます。[root@centos8-str1 ~]# pcs resource cleanup ShareDir
●PacemakerでZabbix-Serverを制御するための準備(MariaDBはMaster/Slave方式)(CentOS Stream 8)
参考URL:Pacemaker/Corosync の設定値について
参考URL:Pacemaker/Corosyncを用いた冗長化Zabbix Serverの構築
※この方法でPacemakerを構成した場合、シャットダウンする前に下記を実施してください。
1.スタンバイ側のクラスタ機能の停止
2.Zabbixサーバの停止
3.MariaDBの停止
4.シャットダウンの実施
または
1.Pacemakerの停止
2.シャットダウンの実施
クラスタソフトのインストールは「●Pacemaker及びCorosyncのインストール・初期設定(CentOS Stream 8)」を参照してください。
特に記載がない場合、2ホストとも同じ作業を行います。
特定のホストでのみ行う作業は、プロンプトにホスト名を記載します。
必要なソフトをインストールします(インストール済みの場合、該当作業は不要です)。# dnf install httpd php php-fpm php-mbstring # vi /etc/php.ini date.timezone ="Asia/Tokyo"Zabbix用のデータベースにMariaDBを利用します。
MariaDBのレプリケーションの設定方法については「レプリケーションの設定のバージョン10.3系」を参照してください。
SELinuxを無効化していない場合、下記のコマンドを実施し、SELinuxを無効化します。# vi /etc/selinux/config SELINUX=disabledホストを再起動します。
ファイアーウォールを動作させている場合、各ソフトで使用するポート(http用ポート:80、Zabbix用ポート:10051)を開けてください。
必要なソフトをインストールします(インストール済みの場合、該当作業は不要です)。# dnf install mariadb mariadb-server # rpm -Uvh https://repo.zabbix.com/zabbix/5.0/rhel/8/x86_64/zabbix-release-5.0-1.el8.noarch.rpm # rpm -Uvh https://repo.zabbix.com/zabbix/5.4/rhel/8/x86_64/zabbix-release-5.4-1.el8.noarch.rpm # dnf clean all # dnf install zabbix-server-mysql zabbix-web-mysql zabbix-apache-conf zabbix-agent # dnf install zabbix-server-mysql zabbix-web-service zabbix-sql-scripts zabbix-agent # dnf install zabbix-server-mysql zabbix-web-service zabbix-sql-scripts zabbix-agent zabbix-web-mysql zabbix-apache-conf zabbix-web-japanese zabbix-getcentos8-str1にてMariaDBが起動していることを確認し、Zabbix用のデータベースを作成します。[root@centos8-str3 ~]# systemctl start mariadb [root@centos8-str3 ~]# systemctl status mariadb [root@centos8-str3 ~]# mysql_secure_installationZabbix用のデータベースにMariaDBをMaster/Slaveで利用します。NOTE: RUNNING ALL PARTS OF THIS SCRIPT IS RECOMMENDED FOR ALL MariaDB SERVERS IN PRODUCTION USE! PLEASE READ EACH STEP CAREFULLY! In order to log into MariaDB to secure it, we'll need the current password for the root user. If you've just installed MariaDB, and you haven't set the root password yet, the password will be blank, so you should just press enter here. Enter current password for root (enter for none): OK, successfully used password, moving on... Setting the root password ensures that nobody can log into the MariaDB root user without the proper authorisation. Set root password? [Y/n] Y New password: Re-enter new password: Password updated successfully! Reloading privilege tables.. ... Success! By default, a MariaDB installation has an anonymous user, allowing anyone to log into MariaDB without having to have a user account created for them. This is intended only for testing, and to make the installation go a bit smoother. You should remove them before moving into a production environment. Remove anonymous users? [Y/n] Y ... Success! Normally, root should only be allowed to connect from 'localhost'. This ensures that someone cannot guess at the root password from the network. Disallow root login remotely? [Y/n] Y ... Success! By default, MariaDB comes with a database named 'test' that anyone can access. This is also intended only for testing, and should be removed before moving into a production environment. Remove test database and access to it? [Y/n] Y - Dropping test database... ... Success! - Removing privileges on test database... ... Success! Reloading the privilege tables will ensure that all changes made so far will take effect immediately. Reload privilege tables now? [Y/n] Y ... Success! Cleaning up... All done! If you've completed all of the above steps, your MariaDB installation should now be secure. Thanks for using MariaDB!
MariaDBのレプリケーションの設定方法については「レプリケーションの設定のバージョン10.3系」を参照してください。
Zabbixのデータベース設定(CentOS Stream 8)
MariaDBにログインする。[root@centos8-str3 ~]# mysql -uroot -p Enter password: MariaDB [(none)]> create database zabbix character set utf8 collate utf8_bin; MariaDB [(none)]> create user zabbix@localhost identified by 'password'; MariaDB [(none)]> grant all privileges on zabbix.* to zabbix@localhost; MariaDB [(none)]> flush privileges; MariaDB [(none)]> quit [root@centos8-str3 ~]# zcat /usr/share/doc/zabbix-server-mysql*/create.sql.gz | mysql -uzabbix -p zabbix [root@centos8-str3 ~]# zcat /usr/share/doc/zabbix-sql-scripts/mysql/create.sql.gz | mysql -uzabbix zabbix -p Enter password:
zabbix-serverとPHPの設定を編集しておきます。centos8-str3とcentos8-str4の両ホストで編集しておく必要があります。# vi /etc/zabbix/zabbix_server.conf DBHost=localhost DBName=zabbix DBUser=zabbix DBPassword=yourpassword # vi /etc/zabbix/web/zabbix.conf.php $DB['SERVER'] = 'localhost'; ← 変更前 ↓ $DB['SERVER'] = '127.0.0.1'; ← 変更後 ※このファイルをscpで他方のホストにコピーする場合、所有者に注意してください。 [root@centos8-str4 ~]# ls -la /etc/zabbix/web/zabbix.conf.php -rw------- 1 apache apache 1482 3月 26 18:55 /etc/zabbix/web/zabbix.conf.php アクセス権がapacheでない場合、webフロントエンドで configuration file error permission denied と表示されてログインできなくなります。 # vi /etc/php-fpm.d/zabbix.conf php_value[date.timezone] = "Asia/Tokyo"
firewalldの設定
Apache、Zabbix Agentの通信を許可するために下記のコマンドを実行する。# firewall-cmd --add-port=10051/tcp --permanent # firewall-cmd --add-service=http --permanent # systemctl restart firewalld
Zabbixサービス起動
centos8-str3でzabbix-server等を起動します(同様の作業を他ホストでも実施します)。[root@centos8-str3 ~]# systemctl start mariadb httpd php-fpm zabbix-serverhttp://centos8-str3のIPアドレス/zabbix/ または http://仮想IPアドレス/zabbix/ へアクセスし、Zabbixのセットアップを進めてください。
Zabbix 5.4インストール時の初期設定画面はこちらです。
Next stepを押下します。
全ての項目が「OK」となっていることを確認してください。
/etc/zabbix/zabbix_server.confで設定した値を入力します。
portは0のままで構いません。
- DBHost=localhost
- DBName=zabbix
- DBUser=zabbix
- DBPassword=yourpassword
下記ウィンドウではデフォルトのまま次に進みます。
設定情報を確認し、問題なければ次に進みます。
無事設定が完了しました。
デフォルトのユーザ名とパスワードは下記のとおりです。少なくともパスワードは変更しましょう。
- ユーザ名:Admin
- パスワード:zabbix
Zabbixのダッシュボードが表示されるところまでの動作を確認できたら、今後、MariaDB、Apache、zabbix-serverをPacemakerで制御したいので、両ホストで一時的に起動していたリソースを停止します。# systemctl stop zabbix-server php-fpm httpd mariadb # systemctl disable mariadb httpd zabbix-serverZabbixの設定が完了したら、MariaDBのレプリケーション設定を行います。
MariaDBをMaster/Slaveで構築します(レプリケーションの設定の「バージョン10.3系」を参照)。
●pacemakerでZabbix-Server及びMariaDBのMaster/Slaveを制御する
参考URL:Pacemaker/Corosyncを用いた冗長化Zabbix Serverの構築
MariaDBをMaster/Slaveで構築します(レプリケーションの設定の「バージョン10.3系」を参照)。
クラスタをセットアップするため、関係あるサービスの停止及び自動起動を停止します。[root@centos8-str3 ~]# systemctl stop zabbix-server [root@centos8-str3 ~]# systemctl stop mariadb [root@centos8-str3 ~]# systemctl stop php-fpm [root@centos8-str3 ~]# systemctl stop httpd [root@centos8-str3 ~]# systemctl disable zabbix-server [root@centos8-str3 ~]# systemctl disable mariadb [root@centos8-str3 ~]# systemctl disable php-fpm [root@centos8-str3 ~]# systemctl disable httpdZabbix用のクラスタを作成します。[root@centos8-str3 ~]# systemctl enable --now pcsd [root@centos8-str3 ~]# pcs cluster setup --start bigbang centos8-str3 addr=192.168.0.43 addr=10.0.0.43 centos8-str4 addr=192.168.0.44 addr=10.0.0.44クラスタを2台構成で設定しますので、下記を設定します。Destroying cluster on hosts: 'centos8-str3', 'centos8-str4'... centos8-str3: Successfully destroyed cluster centos8-str4: Successfully destroyed cluster Requesting remove 'pcsd settings' from 'centos8-str3', 'centos8-str4' centos8-str3: successful removal of the file 'pcsd settings' centos8-str4: successful removal of the file 'pcsd settings' Sending 'corosync authkey', 'pacemaker authkey' to 'centos8-str3', 'centos8-str4' centos8-str3: successful distribution of the file 'corosync authkey' centos8-str3: successful distribution of the file 'pacemaker authkey' centos8-str4: successful distribution of the file 'corosync authkey' centos8-str4: successful distribution of the file 'pacemaker authkey' Sending 'corosync.conf' to 'centos8-str3', 'centos8-str4' centos8-str3: successful distribution of the file 'corosync.conf' centos8-str4: successful distribution of the file 'corosync.conf' Cluster has been successfully set up. Starting cluster on hosts: 'centos8-str3', 'centos8-str4'...[root@centos8-str3 ~]# pcs property set stonith-enabled=false [root@centos8-str3 ~]# pcs property set no-quorum-policy=ignore自動フェールバックを無効とします(Warningは無視します)。[root@centos8-str3 ~]# pcs resource defaults resource-stickiness=INFINITY Warning: This command is deprecated and will be removed. Please use 'pcs resource defaults update' instead. Warning: Defaults do not apply to resources which override them with their own defined valuesエラー発生時、即時にフェールオーバするようにします。(Warningは無視します)。[root@centos8-str3 ~]# pcs resource defaults migration-threshold=1 Warning: This command is deprecated and will be removed. Please use 'pcs resource defaults update' instead. Warning: Defaults do not apply to resources which override them with their own defined valuescentos8-str4をクラスタノード状態を強制的にStandby状態にしておきます。[root@centos8-str3 ~]# pcs node standby centos8-str4pacemakerのリソースを下記のような順序で起動するように(停止はその逆)設定します。
- MariaDB
各ホストに保存されたデータベースを読み込んでMariaDBを起動。Active/Standby。Master側で稼働- Apache
httpdサービスを起動。Active/Standby。Master側で稼働- php-fpm
php-fpmサービスを起動。Master側で稼働- Zabbix-Server
zabbix-serverサービスを起動。Active/Standby。Master側で稼働- VirtualIP
仮想IPの割り当て。Master側で稼働
最終的にZabbix Server/Apache/VirtualIP のリソースをリソースグループ「zabbix-group」にまとめるようにします。
MariaDBのリソースを作成します。[root@centos8-str3 ~]# pcs resource create MariaDB ocf:heartbeat:mysql binary=/usr/bin/mysqld_safe \ datadir=/var/lib/mysql log=/var/log/mariadb/mariadb.log pid=/run/mariadb/mariadb.pid replication_user=repl \ replication_passwd=[パスワード] op monitor interval=10s timeout=10sMariaDBが起動しているかの確認。[root@centos8-str3 ~]# ps aux|grep -v grep|grep mysql追加したMariaDBのリソースをMaster/Slaveで構成します。[root@centos8-str3 ~]# pcs resource promotable MariaDB master-max=1 master-node-max=1 clone-max=2 clone-node-max=1 notify=true優先的にcentos8-str3がMasterとして起動するようにしておきます。
スコア値が高いほど優先的に起動するようです。
-INFINITY<-100<0<100<INFINITY[root@centos8-str3 ~]# pcs constraint location MariaDB-clone prefers centos8-str3=100Zabbix-Serverをリソースに追加します。[root@centos8-str3 ~]# pcs resource create zabbix-server systemd:zabbix-server op monitor interval="10s" timeout="20s"Zabbix-Serverが起動しているかの確認。[root@centos8-str3 ~]# ps aux|grep -v grep|grep zabbix_server両ホストでApacheのstatus.confファイルを作成します。# vi /etc/httpd/conf.d/status.conf ExtendedStatus On <Location /server-status> SetHandler server-status Require local </Location>Apacheをリソースに追加します。[root@centos8-str3 ~]# pcs resource create Apache ocf:heartbeat:apache configfile=/etc/httpd/conf/httpd.conf \ statusurl="http://localhost/server-status" op monitor interval=10s timeout=10s Failed Resource Actions: * Apache_start_0 on centos8-str3 'error' (1): call=35, status='Timed Out', exitreason='', \ last-rc-change='2021-04-06 16:51:57 +09:00', queued=0ms, exec=40001ms 上記記載方法だとクリーンアップしてもエラーになるので、リソースの追加方法を下記に変更します。 [root@centos8-str3 ~]# pcs resource create Apache systemd:httpd op monitor interval=10s timeout=10sApacheが起動しているかの確認。[root@centos8-str3 ~]# ps aux|grep -v grep|grep httpdphp-fpmをリソースに追加します。[root@centos8-str3 ~]# pcs resource create php-fpm systemd:php-fpm op monitor interval=10s timeout=10sphp-fpmが起動しているかの確認。[root@centos8-str3 ~]# ps aux|grep -v grep|grep php-fpm仮想IPをリソースに追加します。[root@centos8-str3 ~]# pcs resource create VirtualIP ocf:heartbeat:IPaddr2 ip=10.0.0.40 cidr_netmask=24 nic=ens192 op monitor interval=10s timeout=10s [root@centos8-str3 ~]# pcs resource create VirtualIP2 ocf:heartbeat:IPaddr2 ip=192.168.0.40 cidr_netmask=24 nic=ens224 op monitor interval=10s timeout=10s設定をしやすようにリソースをグループ(zabbix-group)としてまとめます。[root@centos8-str3 ~]# pcs resource group add zabbix-group Apache php-fpm zabbix-server VirtualIP VirtualIP2起動制約設定# MariaDB起動後にzabbix-groupリソースを起動 [root@centos8-str3 ~]# pcs constraint order promote MariaDB-clone then start zabbix-group Adding MariaDB-clone zabbix-group (kind: Mandatory) (Options: first-action=promote then-action=start) # zabbix-groupはMariaDBのMasterと同じノードで起動 [root@centos8-str3 ~]# pcs constraint colocation add zabbix-group with master MariaDB-clone INFINITY # zabbix-serverはMariaDBのMasterと同じノードで起動(異常検知で必要) [root@centos8-str3 ~]# pcs constraint colocation add master MariaDB-clone with zabbix-server INFINITY # ApacheはMariaDBのMasterと同じノードで起動(異常検知で必要) [root@centos8-str3 ~]# pcs constraint colocation add master MariaDB-clone with Apache INFINITY # php-fpmはMariaDBのMasterと同じノードで起動(異常検知で必要) [root@centos8-str3 ~]# pcs constraint colocation add master MariaDB-clone with php-fpm INFINITY # VirtualIPはMariaDBのMasterと同じノードで起動(異常検知で必要) [root@centos8-str3 ~]# pcs constraint colocation add master MariaDB-clone with VirtualIP INFINITY # VirtualIP2はMariaDBのMasterと同じノードで起動(異常検知で必要) [root@centos8-str3 ~]# pcs constraint colocation add master MariaDB-clone with VirtualIP2 INFINITYクラスタの状態を確認します。[root@centos8-str3 ~]# pcs node unstandby centos8-str4 [root@centos8-str3 ~]# pcs statusconfigの状態を確認します。Cluster name: bigbang Cluster Summary: * Stack: corosync * Current DC: centos8-str3 (version 2.0.5-9.el8-ba59be7122) - partition with quorum * Last updated: Wed Apr 7 17:19:13 2021 * Last change: Wed Apr 7 17:16:09 2021 by root via cibadmin on centos8-str3 * 2 nodes configured * 6 resource instances configured Node List: * Online: [ centos8-str3 centos8-str4 ] Full List of Resources: * Clone Set: MariaDB-clone [MariaDB] (promotable): * Masters: [ centos8-str3 ] * Slaves: [ centos8-str4 ] * Resource Group: zabbix-group: * Apache (ocf::heartbeat:apache): Started centos8-str3 * php-fpm (systemd:php-fpm): Started centos8-str3 * zabbix-server (systemd:zabbix-server): Started centos8-str3 * VirtualIP (ocf::heartbeat:IPaddr2): Started centos8-str3 * VirtualIP2 (ocf::heartbeat:IPaddr2): Started centos8-str3 Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled[root@centos8-str3 ~]# pcs config showCluster Name: bigbang Corosync Nodes: centos8-str3 centos8-str4 Pacemaker Nodes: centos8-str3 centos8-str4 Resources: Clone: MariaDB-clone Meta Attrs: clone-max=2 clone-node-max=1 master-max=1 master-node-max=1 notify=true promotable=true Resource: MariaDB (class=ocf provider=heartbeat type=mysql) Attributes: binary=/usr/bin/mysqld_safe datadir=/var/lib/mysql log=/var/log/mariadb/mariadb.log \ pid=/run/mariadb/mariadb.pid replication_passwd=[パスワード] replication_user=repl Operations: demote interval=0s timeout=120s (MariaDB-demote-interval-0s) monitor interval=10s timeout=10s (MariaDB-monitor-interval-10s) notify interval=0s timeout=90s (MariaDB-notify-interval-0s) promote interval=0s timeout=120s (MariaDB-promote-interval-0s) start interval=0s timeout=120s (MariaDB-start-interval-0s) stop interval=0s timeout=120s (MariaDB-stop-interval-0s) Group: zabbix-group Resource: Apache (class=ocf provider=heartbeat type=apache) Attributes: configfile=/etc/httpd/conf/httpd.conf statusurl=http://localhost/server-status Operations: monitor interval=10s timeout=10s (Apache-monitor-interval-10s) start interval=0s timeout=40s (Apache-start-interval-0s) stop interval=0s timeout=60s (Apache-stop-interval-0s) Resource: php-fpm (class=systemd type=php-fpm) Operations: monitor interval=10s timeout=10s (php-fpm-monitor-interval-10s) start interval=0s timeout=100 (php-fpm-start-interval-0s) stop interval=0s timeout=100 (php-fpm-stop-interval-0s) Resource: zabbix-server (class=systemd type=zabbix-server) Operations: monitor interval=10s timeout=20s (zabbix-server-monitor-interval-10s) start interval=0s timeout=100 (zabbix-server-start-interval-0s) stop interval=0s timeout=100 (zabbix-server-stop-interval-0s) Resource: VirtualIP (class=ocf provider=heartbeat type=IPaddr2) Attributes: cidr_netmask=24 ip=10.0.0.40 nic=ens192 Operations: monitor interval=10s timeout=10s (VirtualIP-monitor-interval-10s) start interval=0s timeout=20s (VirtualIP-start-interval-0s) stop interval=0s timeout=20s (VirtualIP-stop-interval-0s) Resource: VirtualIP2 (class=ocf provider=heartbeat type=IPaddr2) Attributes: cidr_netmask=24 ip=192.168.0.40 nic=ens224 Operations: monitor interval=10s timeout=10s (VirtualIP2-monitor-interval-10s) start interval=0s timeout=20s (VirtualIP2-start-interval-0s) stop interval=0s timeout=20s (VirtualIP2-stop-interval-0s) Stonith Devices: Fencing Levels: Location Constraints: Resource: MariaDB-clone Enabled on: Node: centos8-str3 (score:100) (id:location-MariaDB-clone-centos8-str3-100) Ordering Constraints: promote MariaDB-clone then start zabbix-group (kind:Mandatory) (id:order-MariaDB-clone-zabbix-group-mandatory) Colocation Constraints: zabbix-group with MariaDB-clone (score:INFINITY) (rsc-role:Started) (with-rsc-role:Master) (id:colocation-zabbix-group-MariaDB-clone-INFINITY) MariaDB-clone with zabbix-server (score:INFINITY) (rsc-role:Master) (with-rsc-role:Started) (id:colocation-MariaDB-clone-zabbix-server-INFINITY) MariaDB-clone with Apache (score:INFINITY) (rsc-role:Master) (with-rsc-role:Started) (id:colocation-MariaDB-clone-Apache-INFINITY) MariaDB-clone with php-fpm (score:INFINITY) (rsc-role:Master) (with-rsc-role:Started) (id:colocation-MariaDB-clone-php-fpm-INFINITY) MariaDB-clone with VirtualIP (score:INFINITY) (rsc-role:Master) (with-rsc-role:Started) (id:colocation-MariaDB-clone-VirtualIP-INFINITY) MariaDB-clone with VirtualIP2 (score:INFINITY) (rsc-role:Master) (with-rsc-role:Started) (id:colocation-MariaDB-clone-VirtualIP2-INFINITY) Ticket Constraints: Alerts: No alerts defined Resources Defaults: Meta Attrs: rsc_defaults-meta_attributes migration-threshold=1 resource-stickiness=INFINITY Operations Defaults: No defaults set Cluster Properties: MariaDB_REPL_INFO: centos8-str3.bigbang.mydns.jp|mysql-bin.000352|342 cluster-infrastructure: corosync cluster-name: bigbang dc-version: 2.0.5-9.el8-ba59be7122 have-watchdog: false last-lrm-refresh: 1617778306 no-quorum-policy: ignore stonith-enabled: false Tags: No tags defined Quorum: Options:
プロセスを停止した場合(Apache)(CentOS Stream 8)
1回でもfail-countがカウントされるとフェールオーバーするように設定していない場合、migration-thresholdのデフォルト値(migration-threshold=1000000)を変更してフェールオーバーするようにします。[root@centos8-str3 ~]# pcs resource defaults migration-threshold=1Apacheのサービスを停止し、リソースが他のホストに移動しているか確認します。[root@centos8-str3 ~]# kill -kill `pgrep -f httpd` [root@centos8-str3 ~]# ps axu | grep http[d] [root@centos8-str3 ~]# pcs status --full全てのリソースが他のホストに移動しています。Cluster name: bigbang Cluster Summary: * Stack: corosync * Current DC: centos8-str3 (1) (version 2.0.5-9.el8-ba59be7122) - partition with quorum * Last updated: Fri Apr 9 10:34:17 2021 * Last change: Fri Apr 9 10:32:45 2021 by root via crm_attribute on centos8-str4 * 2 nodes configured * 6 resource instances configured Node List: * Online: [ centos8-str3 (1) centos8-str4 (2) ] Full List of Resources: * Clone Set: MariaDB-clone [MariaDB] (promotable): * MariaDB (ocf::heartbeat:mysql): Slave centos8-str3 * MariaDB (ocf::heartbeat:mysql): Master centos8-str4 * Resource Group: zabbix-group: * Apache (ocf::heartbeat:apache): Started centos8-str4 * zabbix-server (systemd:zabbix-server): Started centos8-str4 * VirtualIP (ocf::heartbeat:IPaddr2): Started centos8-str4 * VirtualIP2 (ocf::heartbeat:IPaddr2): Started centos8-str4 Node Attributes: * Node: centos8-str3 (1): * master-MariaDB : 1 * readable : 1 * Node: centos8-str4 (2): * master-MariaDB : 3601 * readable : 1 Migration Summary: * Node: centos8-str3 (1): * Apache: migration-threshold=1 fail-count=1 last-failure='Fri Apr 9 10:32:42 2021' Failed Resource Actions: * Apache_monitor_10000 on centos8-str3 'not running' (7): call=29, status='complete', exitreason='', \ last-rc-change='2021-04-09 10:32:42 +09:00', queued=0ms, exec=0ms Tickets: PCSD Status: centos8-str3: Online centos8-str4: Online Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled
エラーをクリアし、再度Apacheのサービスを停止させリソースを元のホストに移動させます。[root@centos8-str4 ~]# pcs resource cleanup Apache Cleaned up Apache on centos8-str4 Cleaned up Apache on centos8-str3 Cleaned up zabbix-server on centos8-str4 Cleaned up zabbix-server on centos8-str3 Cleaned up VirtualIP on centos8-str4 Cleaned up VirtualIP on centos8-str3 Cleaned up VirtualIP2 on centos8-str4 Cleaned up VirtualIP2 on centos8-str3 Waiting for 1 reply from the controller ... got reply (done) [root@centos8-str4 ~]# kill -kill `pgrep -f httpd` [root@centos8-str4 ~]# ps axu | grep http[d] [root@centos8-str4 ~]# pcs status --full全てのリソースが元のホストに戻っています。Cluster name: bigbang Cluster Summary: * Stack: corosync * Current DC: centos8-str3 (1) (version 2.0.5-9.el8-ba59be7122) - partition with quorum * Last updated: Fri Apr 9 10:41:48 2021 * Last change: Fri Apr 9 10:41:22 2021 by root via crm_attribute on centos8-str3 * 2 nodes configured * 6 resource instances configured Node List: * Online: [ centos8-str3 (1) centos8-str4 (2) ] Full List of Resources: * Clone Set: MariaDB-clone [MariaDB] (promotable): * MariaDB (ocf::heartbeat:mysql): Master centos8-str3 * MariaDB (ocf::heartbeat:mysql): Slave centos8-str4 * Resource Group: zabbix-group: * Apache (ocf::heartbeat:apache): Started centos8-str3 * zabbix-server (systemd:zabbix-server): Started centos8-str3 * VirtualIP (ocf::heartbeat:IPaddr2): Started centos8-str3 * VirtualIP2 (ocf::heartbeat:IPaddr2): Started centos8-str3 Node Attributes: * Node: centos8-str3 (1): * master-MariaDB : 3601 * readable : 1 * Node: centos8-str4 (2): * master-MariaDB : 1 * readable : 1 Migration Summary: * Node: centos8-str4 (2): * Apache: migration-threshold=1 fail-count=1 last-failure='Fri Apr 9 10:41:18 2021' Failed Resource Actions: * Apache_monitor_10000 on centos8-str4 'not running' (7): call=35, status='complete', exitreason='', \ last-rc-change='2021-04-09 10:41:19 +09:00', queued=0ms, exec=0ms Tickets: PCSD Status: centos8-str3: Offline centos8-str4: Online Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled
エラーを消しておきます。[root@centos8-str4 ~]# pcs resource cleanup Apache
プロセスを停止した場合(Zabbix Server)(CentOS Stream 8)
1回でもfail-countがカウントされるとフェールオーバーするように設定していない場合、migration-thresholdのデフォルト値(migration-threshold=1000000)を変更してフェールオーバーするようにします。[root@centos8-str3 ~]# pcs resource defaults migration-threshold=1Zabbix Serverのサービスを停止し、リソースが他のホストに移動しているか確認します。[root@centos8-str3 ~]# kill -kill `pgrep -f zabbix_server` [root@centos8-str3 ~]# ps axu | grep -v grep | grep zabbix_server [root@centos8-str3 ~]# pcs status --full全てのリソースが他のホストに移動しています。Cluster name: bigbang Cluster Summary: * Stack: corosync * Current DC: centos8-str3 (1) (version 2.0.5-9.el8-ba59be7122) - partition with quorum * Last updated: Fri Apr 9 10:51:46 2021 * Last change: Fri Apr 9 10:50:59 2021 by root via crm_attribute on centos8-str4 * 2 nodes configured * 6 resource instances configured Node List: * Online: [ centos8-str3 (1) centos8-str4 (2) ] Full List of Resources: * Clone Set: MariaDB-clone [MariaDB] (promotable): * MariaDB (ocf::heartbeat:mysql): Slave centos8-str3 * MariaDB (ocf::heartbeat:mysql): Master centos8-str4 * Resource Group: zabbix-group: * Apache (ocf::heartbeat:apache): Started centos8-str4 * zabbix-server (systemd:zabbix-server): Started centos8-str4 * VirtualIP (ocf::heartbeat:IPaddr2): Started centos8-str4 * VirtualIP2 (ocf::heartbeat:IPaddr2): Started centos8-str4 Node Attributes: * Node: centos8-str3 (1): * master-MariaDB : 1 * readable : 1 * Node: centos8-str4 (2): * master-MariaDB : 3601 * readable : 1 Migration Summary: * Node: centos8-str3 (1): * zabbix-server: migration-threshold=1 fail-count=1 last-failure='Fri Apr 9 10:50:54 2021' Failed Resource Actions: * zabbix-server_monitor_10000 on centos8-str3 'not running' (7): call=64, status='complete', exitreason='', \ last-rc-change='2021-04-09 10:50:54 +09:00', queued=0ms, exec=0ms Tickets: PCSD Status: centos8-str3: Online centos8-str4: Online Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled
エラーをクリアし、再度Zabbix Serverのサービスを停止させリソースを元のホストに移動させます。[root@centos8-str4 ~]# pcs resource cleanup zabbix-server Cleaned up Apache on centos8-str4 Cleaned up Apache on centos8-str3 Cleaned up zabbix-server on centos8-str4 Cleaned up zabbix-server on centos8-str3 Cleaned up VirtualIP on centos8-str4 Cleaned up VirtualIP on centos8-str3 Cleaned up VirtualIP2 on centos8-str4 Cleaned up VirtualIP2 on centos8-str3 Waiting for 1 reply from the controller ... got reply (done) [root@centos8-str4 ~]# kill -kill `pgrep -f zabbix_server` [root@centos8-str4 ~]# ps axu | grep -v grep | grep zabbix_server [root@centos8-str4 ~]# pcs status --full全てのリソースが元のホストに戻っています。Cluster name: bigbang Cluster Summary: * Stack: corosync * Current DC: centos8-str3 (1) (version 2.0.5-9.el8-ba59be7122) - partition with quorum * Last updated: Fri Apr 9 10:57:12 2021 * Last change: Fri Apr 9 10:56:58 2021 by root via crm_attribute on centos8-str3 * 2 nodes configured * 6 resource instances configured Node List: * Online: [ centos8-str3 (1) centos8-str4 (2) ] Full List of Resources: * Clone Set: MariaDB-clone [MariaDB] (promotable): * MariaDB (ocf::heartbeat:mysql): Master centos8-str3 * MariaDB (ocf::heartbeat:mysql): Slave centos8-str4 * Resource Group: zabbix-group: * Apache (ocf::heartbeat:apache): Started centos8-str3 * zabbix-server (systemd:zabbix-server): Started centos8-str3 * VirtualIP (ocf::heartbeat:IPaddr2): Started centos8-str3 * VirtualIP2 (ocf::heartbeat:IPaddr2): Started centos8-str3 Node Attributes: * Node: centos8-str3 (1): * master-MariaDB : 3601 * readable : 1 * Node: centos8-str4 (2): * master-MariaDB : 1 * readable : 1 Migration Summary: * Node: centos8-str4 (2): * zabbix-server: migration-threshold=1 fail-count=1 last-failure='Fri Apr 9 10:56:52 2021' Failed Resource Actions: * zabbix-server_monitor_10000 on centos8-str4 'not running' (7): call=70, status='complete', exitreason='', \ last-rc-change='2021-04-09 10:56:52 +09:00', queued=0ms, exec=0ms Tickets: PCSD Status: centos8-str3: Offline centos8-str4: Online Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled
エラーを消しておきます。[root@centos8-str4 ~]# pcs resource cleanup zabbix-server
NIC障害(VirtualIP)(CentOS Stream 8)
仮想ホストのNICを切断する必要があります。
詳細な操作方法は「NIC障害」を参照してください。
VIPの監視にon-fail=standbyのオプションを指定しないとうまく切り替わらないので、あらかじめ設定しておきます。[root@centos8-str3 ~]# pcs resource update VirtualIP op monitor on-fail=standby [root@centos8-str3 ~]# pcs resource update VirtualIP2 op monitor on-fail=standby [root@centos8-str3 ~]# pcs resource config該当仮想ホスト(centos8-str3)のNICを削除してしまうためログインできなくなりますので、状態確認は他方のホスト(centos8-str4)で実施します。Clone: MariaDB-clone Meta Attrs: clone-max=2 clone-node-max=1 master-max=1 master-node-max=1 notify=true promotable=true Resource: MariaDB (class=ocf provider=heartbeat type=mysql) Attributes: binary=/usr/bin/mysqld_safe datadir=/var/lib/mysql log=/var/log/mariadb/mariadb.log \ pid=/run/mariadb/mariadb.pid replication_passwd=[パスワード] replication_user=repl Operations: demote interval=0s timeout=120s (MariaDB-demote-interval-0s) monitor interval=10s timeout=10s (MariaDB-monitor-interval-10s) notify interval=0s timeout=90s (MariaDB-notify-interval-0s) promote interval=0s timeout=120s (MariaDB-promote-interval-0s) start interval=0s timeout=120s (MariaDB-start-interval-0s) stop interval=0s timeout=120s (MariaDB-stop-interval-0s) Group: zabbix-group Resource: Apache (class=ocf provider=heartbeat type=apache) Attributes: configfile=/etc/httpd/conf/httpd.conf statusurl=http://localhost/server-status Operations: monitor interval=10s timeout=10s (Apache-monitor-interval-10s) start interval=0s timeout=40s (Apache-start-interval-0s) stop interval=0s timeout=60s (Apache-stop-interval-0s) Resource: zabbix-server (class=systemd type=zabbix-server) Operations: monitor interval=10s timeout=20s (zabbix-server-monitor-interval-10s) start interval=0s timeout=100 (zabbix-server-start-interval-0s) stop interval=0s timeout=100 (zabbix-server-stop-interval-0s) Resource: VirtualIP (class=ocf provider=heartbeat type=IPaddr2) Attributes: cidr_netmask=24 ip=10.0.0.40 nic=ens192 Operations: monitor interval=60s on-fail=standby (VirtualIP-monitor-interval-60s) start interval=0s timeout=20s (VirtualIP-start-interval-0s) stop interval=0s timeout=20s (VirtualIP-stop-interval-0s) Resource: VirtualIP2 (class=ocf provider=heartbeat type=IPaddr2) Attributes: cidr_netmask=24 ip=192.168.0.40 nic=ens224 Operations: monitor interval=60s on-fail=standby (VirtualIP2-monitor-interval-60s) start interval=0s timeout=20s (VirtualIP2-start-interval-0s) stop interval=0s timeout=20s (VirtualIP2-stop-interval-0s)[root@centos8-str4 ~]# pcs status --fullエラーを消し、該当仮想ホスト(centos8-str3)のNICを元の状態に戻します。Cluster name: bigbang Cluster Summary: * Stack: corosync * Current DC: centos8-str3 (1) (version 2.0.5-9.el8-ba59be7122) - partition with quorum * Last updated: Fri Apr 9 11:25:19 2021 * Last change: Fri Apr 9 11:24:46 2021 by root via crm_attribute on centos8-str4 * 2 nodes configured * 6 resource instances configured Node List: * Node centos8-str3 (1): standby (on-fail) * Online: [ centos8-str4 (2) ] Full List of Resources: * Clone Set: MariaDB-clone [MariaDB] (promotable): * MariaDB (ocf::heartbeat:mysql): Master centos8-str4 * MariaDB (ocf::heartbeat:mysql): Stopped * Resource Group: zabbix-group: * Apache (ocf::heartbeat:apache): Started centos8-str4 * zabbix-server (systemd:zabbix-server): Started centos8-str4 * VirtualIP (ocf::heartbeat:IPaddr2): Started centos8-str4 * VirtualIP2 (ocf::heartbeat:IPaddr2): Started centos8-str4 Node Attributes: * Node: centos8-str3 (1): * readable : 0 * Node: centos8-str4 (2): * master-MariaDB : 3601 * readable : 1 Migration Summary: * Node: centos8-str3 (1): * VirtualIP: migration-threshold=1 fail-count=1 last-failure='Fri Apr 9 11:24:39 2021' Failed Resource Actions: * VirtualIP_monitor_60000 on centos8-str3 'not running' (7): call=102, status='complete', exitreason='', \ last-rc-change='2021-04-09 11:24:39 +09:00', queued=0ms, exec=0ms Tickets: PCSD Status: centos8-str3: Offline centos8-str4: Online Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled[root@centos8-str4 ~]# pcs resource cleanup VirtualIP全てのリソースがcentos8-str4に移動しています。[root@centos8-str4 ~]# pcs status --fullこの状態で今度は仮想ホスト(centos8-str4)のVirtualIP2が属するNICを切断します。Cluster name: bigbang Cluster Summary: * Stack: corosync * Current DC: centos8-str3 (1) (version 2.0.5-9.el8-ba59be7122) - partition with quorum * Last updated: Fri Apr 9 11:32:53 2021 * Last change: Fri Apr 9 11:32:30 2021 by hacluster via crmd on centos8-str3 * 2 nodes configured * 6 resource instances configured Node List: * Online: [ centos8-str3 (1) centos8-str4 (2) ] Full List of Resources: * Clone Set: MariaDB-clone [MariaDB] (promotable): * MariaDB (ocf::heartbeat:mysql): Slave centos8-str3 * MariaDB (ocf::heartbeat:mysql): Master centos8-str4 * Resource Group: zabbix-group: * Apache (ocf::heartbeat:apache): Started centos8-str4 * zabbix-server (systemd:zabbix-server): Started centos8-str4 * VirtualIP (ocf::heartbeat:IPaddr2): Started centos8-str4 * VirtualIP2 (ocf::heartbeat:IPaddr2): Started centos8-str4 Node Attributes: * Node: centos8-str3 (1): * master-MariaDB : 1 * readable : 0 * Node: centos8-str4 (2): * master-MariaDB : 3601 * readable : 1 Migration Summary: Tickets: PCSD Status: centos8-str3: Offline centos8-str4: Online Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled[root@centos8-str3 ~]# pcs status --full全てのリソースが元のホストに戻っています。Cluster name: bigbang Cluster Summary: * Stack: corosync * Current DC: centos8-str3 (1) (version 2.0.5-9.el8-ba59be7122) - partition with quorum * Last updated: Fri Apr 9 11:42:17 2021 * Last change: Fri Apr 9 11:41:57 2021 by root via crm_attribute on centos8-str3 * 2 nodes configured * 6 resource instances configured Node List: * Node centos8-str4 (2): standby (on-fail) * Online: [ centos8-str3 (1) ] Full List of Resources: * Clone Set: MariaDB-clone [MariaDB] (promotable): * MariaDB (ocf::heartbeat:mysql): Master centos8-str3 * MariaDB (ocf::heartbeat:mysql): Stopped * Resource Group: zabbix-group: * Apache (ocf::heartbeat:apache): Started centos8-str3 * zabbix-server (systemd:zabbix-server): Started centos8-str3 * VirtualIP (ocf::heartbeat:IPaddr2): Started centos8-str3 * VirtualIP2 (ocf::heartbeat:IPaddr2): Started centos8-str3 Node Attributes: * Node: centos8-str3 (1): * master-MariaDB : 3601 * readable : 1 * Node: centos8-str4 (2): * readable : 0 Migration Summary: * Node: centos8-str4 (2): * VirtualIP2: migration-threshold=1 fail-count=1 last-failure='Fri Apr 9 11:41:50 2021' Failed Resource Actions: * VirtualIP2_monitor_60000 on centos8-str4 'not running' (7): call=109, status='complete', exitreason='', \ last-rc-change='2021-04-09 11:41:50 +09:00', queued=0ms, exec=0ms Tickets: PCSD Status: centos8-str3: Online centos8-str4: Online Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled
エラーを消し、該当仮想ホストのNICを元の状態に戻します。[root@centos8-str3 ~]# pcs resource cleanup VirtualIP2
●pacemakerでZabbix-Server(MariaDBのMaster/Slave)+共有ディスク(DRBD)を制御する(その3)(AlmaLinux 8)
クラスタの基本設定# pcs host auth alma8-1 alma8-2 # pcs cluster setup --start bigbang alma8-1 addr=10.0.0.151 addr=192.168.10.151 alma8-2 addr=10.0.0.152 addr=192.168.10.152
プロパティ等の設定条件
下記のとおり設定しました。
- no-quorum-policy: ignore ← 2台構成のため
- stonith-enabled: false ← 2台構成のため
- failure-timeout=300s ← 障害検知後、その後300秒間障害がない場合、障害記録(fail-count)をクリア
- migration-threshold=3 ← いずれかのリソースで(上記の場合、300秒以内に)3回障害検知時にフェールオーバー発生
- resource-stickiness=INFINITY ← 自動フェールバック無効
# pcs property set stonith-enabled=false # pcs property set no-quorum-policy=ignore # pcs resource defaults update failure-timeout=300s # pcs resource defaults migration-threshold=3 # pcs resource defaults resource-stickiness=INFINITYこのプロパティ等の設定条件を変更せずにリソースを設定し、問題なく動作するか確認します。
リソース設定(その1)
下記のとおり設定しました。
- DRBD(マスター・スレーブ方式)・・・①
- ファイルシステムマウント(DRBDマスタ側)・・・②
DRBD → マウント の順で動作するように設定- バーチャルIP(マスタのみ)・・・③
- Apache(マスタのみ)・・・④
②③④:同一リソースグループに設定し、②③④の順に起動
②③④:このリソースグループはDRBDマスタ側で必ず起動# pcs resource create DRBD_r0 ocf:linbit:drbd drbd_resource=r0 # pcs resource promotable DRBD_r0 master-max=1 master-node-max=1 clone-max=2 clone-node-max=1 notify=true # pcs constraint location DRBD_r0-clone prefers alma8-1=100 # pcs resource cleanup DRBD_r0 # pcs resource create FS_DRBD0 ocf:heartbeat:Filesystem device=/dev/drbd0 directory=/mnt fstype=xfs --group cluster-group # pcs resource create VirtualIP ocf:heartbeat:IPaddr2 ip=10.0.0.150 cidr_netmask=24 nic=ens192 op monitor interval=30s --group cluster-group # pcs resource create httpd systemd:httpd --group cluster-group # pcs constraint colocation add DRBD_r0-clone with Master FS_DRBD0 # pcs constraint order promote DRBD_r0-clone then start FS_DRBD0 # pcs constraint colocation add cluster-group with Master DRBD_r0 INFINITY --force手動による片側強制スタンバイを実行し、フェールオーバーまたはフェールバックさせましたが動作に問題ありませんでした。
特定リソース(Apache)を300秒以内に3回連続で障害(fail-count=3)にさせ、フェールオーバーまたはフェールバックさせましたが動作は問題ありませんでした。
リソース設定(その2)
上記のリソース状態に新たにZabbix Serverを下記のとおり追加設定しました。
- DRBD(マスター・スレーブ方式)・・・①
- ファイルシステムマウント(DRBDマスタ側)・・・②
DRBD → マウント の順で動作するように設定- バーチャルIP(マスタのみ)・・・③
- Apache(マスタのみ)・・・④
- MariaDB(マスター・スレーブ方式)・・・⑤
- Zabbix Server(マスタのみ)・・・⑥
②③④:同一リソースグループに設定し、②③④の順に起動
⑤:マスター・スレーブ方式(各サーバのデータベースはデフォルトフォルダに保存)
⑥:単独リソースとして追加
②③④:このリソースグループはDRBDマスタ側で必ず起動
⑤:このリソースはDRBDのマスタ側で必ず起動
⑥:このリソースはMariaDBのマスタ側で必ず起動
この設定を入れないとZabbix ServerがMariaDBのスレーブ側で起動してしまう# pcs resource create MariaDB ocf:heartbeat:mysql binary=/usr/bin/mysqld_safe datadir=/var/lib/mysql log=/var/log/mariadb/mariadb.log \ pid=/run/mariadb/mariadb.pid replication_user=repl replication_passwd=******** op monitor interval=10s timeout=10s # pcs resource promotable MariaDB master-max=1 master-node-max=1 clone-max=2 clone-node-max=1 notify=true # pcs constraint colocation add master MariaDB-clone with master DRBD_r0 INFINITY --force # pcs resource create zabbix-server systemd:zabbix-server # pcs constraint colocation add zabbix-server with master MariaDB-clone INFINITY手動による片側強制スタンバイを実行し、フェールオーバーまたはフェールバックさせましたが動作に問題ありませんでした。
特定リソース(Apache)を300秒以内に3回連続で障害(fail-count=3)にさせ、フェールオーバーまたはフェールバックさせましたが動作は問題ありませんでした。
リソース設定(その3)
上記のリソース状態に新たにZabbix Serverを下記のとおり追加設定しました。
- DRBD(マスター・スレーブ方式)・・・①
- ファイルシステムマウント(DRBDマスタ側)・・・②
DRBD → マウント の順で動作するように設定- バーチャルIP(マスタのみ)・・・③
- Apache(マスタのみ)・・・④
- MariaDB(マスター・スレーブ方式)・・・⑤
- Zabbix Server(マスタのみ)・・・⑥
②③④:同一リソースグループに設定し、②③④の順に起動
⑤:単独リソースとして追加
②③④:このリソースグループはDRBDマスタ側で必ず起動
⑤:このリソースはDRBDのマスタ側で必ず起動
⑥:このリソースはMariaDBのマスタ側で必ず起動
⑦:「リソース設定(その2)」の設定後、リソースhttpd(または、リソースcluster-group(②③④))が起動してからリソースzabbix-serverを起動する順序を設定# pcs constraint order promote cluster-group then start zabbix-server or # pcs constraint order promote httpd then start zabbix-server「リソース設定(その2)」の設定後、リソースhttpd(または、リソースcluster-group(②③④))が起動してからリソースzabbix-serverを起動する順序を設定しましたが、リソースzabbix-serverが起動しなくなりました。
●pacemakerでZabbix-Server(MariaDBのMaster/Slave)+共有ディスク(DRBD)を制御する(その2)(CentOS Stream 8)
期待通り動作せず
※この方法でPacemakerを構成した場合、シャットダウンする前に下記を実施してください。
1.スタンバイ側のクラスタ機能の停止
2.Zabbixサーバの停止
3.MariaDBの停止
4.シャットダウンの実施
または
1.Pacemakerの停止
2.シャットダウンの実施
DRBD(Primary/Secondary)とMariaDB(Master/Slave)を同時にPacemakerで設定すると、設定当初は想定通り動作するもののフェールオーバーの動作確認やノードの再起動によりDRBDのPrimary/Secondaryが正常に動作しなくなったり、MariaDBのMaster/Slaveが正常に動作しなくなったりしてしまう。設定よるものなのか原因不明。
CentOS Stream 8上で構築します。
下記についての作業は完了しているものとします。今回作成のDRBDの共有ディスク(ネットワークは192.168.111.0/24を使用してレプリケーションを実施)部分に、ApacheのDocumentRootを保存します。
- MariaDBのインストール及びMaster/Slaveの構築
「初期設定(CentOS 8)」参照
レプリケーションの設定の「バージョン10.3系」参照- Zabbix Serverのインストール及び設定
「pacemakerでZabbix-Server及びMariaDBのMaster/Slaveを制御する」参照
- DRBDによる共有ディスクの設定
「DRBDの構築について」参照
「DRBDをpacemakerの現在のリソースに追加する」参照
したがって、DRBDが起動できない場合、Apacheが起動せず異常終了します。
Apacheの異常終了はzabbix-groupの異常につながり、最終的にpacemakerが異常となります。
バーチャルIP異常試験は10.0.0.0/24側のNICを切断するようにします。
クラスタを2台構成で設定しますので、下記を設定します。[root@centos8-str3 ~]# pcs property set stonith-enabled=false [root@centos8-str3 ~]# pcs property set no-quorum-policy=ignoreDRBDは自動フェールバックを無効としておかないとDRDBでスプリットブレインが発生し、2台ともStandAlone状態となってしまう場合があります。
この対策のため、自動フェールバックを無効とします(Warningは無視します)。[root@centos8-str3 ~]# pcs resource defaults resource-stickiness=INFINITY Warning: This command is deprecated and will be removed. Please use 'pcs resource defaults update' instead. Warning: Defaults do not apply to resources which override them with their own defined valuesエラー発生時、即時にフェールオーバするようにします。(Warningは無視します)。[root@centos8-str3 ~]# pcs resource defaults migration-threshold=1 Warning: This command is deprecated and will be removed. Please use 'pcs resource defaults update' instead. Warning: Defaults do not apply to resources which override them with their own defined valuescentos8-str4をクラスタノード状態を強制的にStandby状態にしておきます。[root@centos8-str3 ~]# pcs node standby centos8-str4pacemakerのリソースを下記のような順序で起動するように(停止はその逆)設定します。
- DRBD
DRBDを設定しブロックデバイスをリアルタイムにレプリケート。
Primary/Secondaryで構築。- FS_DRBD0
DRBDのPrimary側でブロックデバイスを/mntにマウントする。- MariaDB
各ホストに保存されたデータベースを読み込んでMariaDBを起動。
Master/Slaveで構築。- VirtualIP
仮想IP(サービス側)の割り当て。MariaDBのMaster側で稼働。
zabbix-groupに追加。- VirtualIP2
仮想IP(DRDB同期用)の割り当て。MariaDBのMaster側で稼働。
zabbix-groupに追加。- Apache
httpdサービスを起動。Active/Standby。MariaDBのMaster側で稼働
zabbix-groupに追加。- php-fpm
php-fpmサービスを起動。MariaDBのMaster側で稼働。
zabbix-groupに追加。- Zabbix-Server
zabbix-serverサービスを起動。Active/Standby。MariaDBのMaster側で稼働。
zabbix-groupに追加。
最終的にVirtualIP/VirtualIP2/Apache/php-fpm/Zabbix Server のリソースをリソースグループ「zabbix-group」にまとめ、制御するようにします。
DRBDのリソースを作成します。
(DRBDのリソース定義は完了しているものとします。)[root@centos8-str3 ~]# pcs resource create DRBD_r0 ocf:linbit:drbd drbd_resource=r0 [root@centos8-str3 ~]# pcs resource promotable DRBD_r0 master-max=1 master-node-max=1 clone-max=2 clone-node-max=1 notify=true優先的にcentos8-str3がMasterとして起動するようにしておきます。[root@centos8-str3 ~]# pcs constraint location DRBD_r0-clone prefers centos8-str3=100 [root@centos8-str3 ~]# pcs resource cleanup DRBD_r0 [root@centos8-str3 ~]# pcs resource create FS_DRBD0 ocf:heartbeat:Filesystem device=/dev/drbd0 directory=/mnt fstype=xfsMariaDBのリソースを作成します。
(MariaBDのインストール、レプリケーション設定は完了しているものとします。)[root@centos8-str3 ~]# pcs resource create MariaDB ocf:heartbeat:mysql binary=/usr/bin/mysqld_safe \ datadir=/var/lib/mysql log=/var/log/mariadb/mariadb.log pid=/run/mariadb/mariadb.pid replication_user=repl \ replication_passwd=[パスワード] op monitor interval=10s timeout=10s追加したMariaDBのリソースをMaster/Slaveで構成します。[root@centos8-str3 ~]# pcs resource promotable MariaDB master-max=1 master-node-max=1 clone-max=2 clone-node-max=1 notify=true優先的にcentos8-str3がMasterとして起動するようにしておきます。
[root@centos8-str3 ~]# pcs constraint location MariaDB-clone prefers centos8-str3=100FS_DRBD0はDRBD_r0のMasterと同じノードで起動(異常検知で必要)[root@centos8-str3 ~]# pcs constraint colocation add master DRBD_r0-clone with FS_DRBD0 INFINITYMariaDBのMasterはFS_DRBD0と同じノードで起動(異常検知で必要)[root@centos8-str3 ~]# pcs constraint colocation add FS_DRBD0 with MariaDB-clone INFINITY with-rsc-role=Master仮想IPをリソースに追加します。[root@centos8-str3 ~]# pcs resource create VirtualIP ocf:heartbeat:IPaddr2 ip=10.0.0.40 cidr_netmask=24 nic=ens192 op monitor interval=10s timeout=10s [root@centos8-str3 ~]# pcs resource create VirtualIP2 ocf:heartbeat:IPaddr2 ip=192.168.0.40 cidr_netmask=24 nic=ens224 op monitor interval=10s timeout=10s両ホストでApacheのstatus.confファイルを作成します。# vi /etc/httpd/conf.d/status.conf ExtendedStatus On <Location /server-status> SetHandler server-status Require local </Location>Apacheをリソースに追加します。[root@centos8-str3 ~]# pcs resource create Apache ocf:heartbeat:apache configfile=/etc/httpd/conf/httpd.conf \ statusurl="http://localhost/server-status" op monitor interval=10s timeout=10sphp-fpmをリソースに追加します。[root@centos8-str3 ~]# pcs resource create php-fpm systemd:php-fpm op monitor interval=10s timeout=10sZabbix-Serverをリソースに追加します。[root@centos8-str3 ~]# pcs resource create zabbix-server systemd:zabbix-server op monitor interval="10s" timeout="20s"設定をしやすようにリソースをグループ(zabbix-group)としてまとめます。[root@centos8-str3 ~]# pcs resource group add zabbix-group VirtualIP VirtualIP2 Apache php-fpm zabbix-server起動制約設定# VirtualIPはDRBD_r0のMasterと同じノードで起動(異常検知で必要) [root@centos8-str3 ~]# pcs constraint colocation add master DRBD_r0-clone with VirtualIP INFINITY # VirtualIP2はDRBD_r0のMasterと同じノードで起動(異常検知で必要) [root@centos8-str3 ~]# pcs constraint colocation add master DRBD_r0-clone with VirtualIP2 INFINITY # DRBD_r0起動後にzabbix-groupリソースを起動 [root@centos8-str3 ~]# pcs constraint order promote DRBD_r0-clone then start zabbix-group Adding MariaDB-clone zabbix-group (kind: Mandatory) (Options: first-action=promote then-action=start) # zabbix-groupはDRBD_r0のMasterと同じノードで起動 [root@centos8-str3 ~]# pcs constraint colocation add zabbix-group with master DRBD_r0-clone INFINITY # zabbix-serverはDRBD_r0のMasterと同じノードで起動(異常検知で必要) [root@centos8-str3 ~]# pcs constraint colocation add master DRBD_r0-clone with zabbix-server INFINITY # ApacheはMariaDBのDRBD_r0と同じノードで起動(異常検知で必要) [root@centos8-str3 ~]# pcs constraint colocation add master DRBD_r0-clone with Apache INFINITY # php-fpmはDRBD_r0のMasterと同じノードで起動(異常検知で必要) [root@centos8-str3 ~]# pcs constraint colocation add master DRBD_r0-clone with php-fpm INFINITY # zabbix-groupはDRBD_r0のMasterと同じノードで起動(異常検知で必要) [root@centos8-str3 ~]# pcs constraint colocation add master DRBD_r0-clone with zabbix-group INFINITYクラスタの状態を確認します。[root@centos8-str3 ~]# pcs node unstandby centos8-str4 [root@centos8-str3 ~]# pcs statusconfigを確認します。Cluster name: bigbang Cluster Summary: * Stack: corosync * Current DC: centos8-str3 (version 2.0.5-9.el8-ba59be7122) - partition with quorum * Last updated: Mon Apr 26 11:04:08 2021 * Last change: Thu Apr 22 16:45:44 2021 by root via cibadmin on centos8-str3 * 2 nodes configured * 10 resource instances configured Node List: * Online: [ centos8-str3 centos8-str4 ] Full List of Resources: * Clone Set: DRBD_r0-clone [DRBD_r0] (promotable): * Masters: [ centos8-str3 ] * Slaves: [ centos8-str4 ] * Resource Group: zabbix-group: * FS_DRBD0 (ocf::heartbeat:Filesystem): Started centos8-str3 * Apache (ocf::heartbeat:apache): Started centos8-str3 * php-fpm (systemd:php-fpm): Started centos8-str3 * zabbix-server (systemd:zabbix-server): Started centos8-str3 * VirtualIP (ocf::heartbeat:IPaddr2): Started centos8-str3 * VirtualIP2 (ocf::heartbeat:IPaddr2): Started centos8-str3 * Clone Set: MariaDB-clone [MariaDB] (promotable): * Masters: [ centos8-str3 ] * Slaves: [ centos8-str4 ] Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled[root@centos8-str3 ~]# pcs config showCluster Name: bigbang Corosync Nodes: centos8-str3 centos8-str4 Pacemaker Nodes: centos8-str3 centos8-str4 Resources: Clone: DRBD_r0-clone Meta Attrs: clone-max=2 clone-node-max=1 master-max=1 master-node-max=1 notify=true promotable=true Resource: DRBD_r0 (class=ocf provider=linbit type=drbd) Attributes: drbd_resource=r0 Operations: demote interval=0s timeout=90 (DRBD_r0-demote-interval-0s) monitor interval=20 role=Slave timeout=20 (DRBD_r0-monitor-interval-20) monitor interval=10 role=Master timeout=20 (DRBD_r0-monitor-interval-10) notify interval=0s timeout=90 (DRBD_r0-notify-interval-0s) promote interval=0s timeout=90 (DRBD_r0-promote-interval-0s) reload interval=0s timeout=30 (DRBD_r0-reload-interval-0s) start interval=0s timeout=240 (DRBD_r0-start-interval-0s) stop interval=0s timeout=100 (DRBD_r0-stop-interval-0s) Group: zabbix-group Resource: FS_DRBD0 (class=ocf provider=heartbeat type=Filesystem) Attributes: device=/dev/drbd0 directory=/mnt fstype=xfs Operations: monitor interval=20s timeout=40s (FS_DRBD0-monitor-interval-20s) start interval=0s timeout=60s (FS_DRBD0-start-interval-0s) stop interval=0s timeout=60s (FS_DRBD0-stop-interval-0s) Resource: Apache (class=ocf provider=heartbeat type=apache) Attributes: configfile=/etc/httpd/conf/httpd.conf statusurl=http://localhost/server-status Operations: monitor interval=10s timeout=10s (Apache-monitor-interval-10s) start interval=0s timeout=40s (Apache-start-interval-0s) stop interval=0s timeout=60s (Apache-stop-interval-0s) Resource: php-fpm (class=systemd type=php-fpm) Operations: monitor interval=10s timeout=10s (php-fpm-monitor-interval-10s) start interval=0s timeout=100 (php-fpm-start-interval-0s) stop interval=0s timeout=100 (php-fpm-stop-interval-0s) Resource: zabbix-server (class=systemd type=zabbix-server) Operations: monitor interval=10s timeout=20s (zabbix-server-monitor-interval-10s) start interval=0s timeout=100 (zabbix-server-start-interval-0s) stop interval=0s timeout=100 (zabbix-server-stop-interval-0s) Resource: VirtualIP (class=ocf provider=heartbeat type=IPaddr2) Attributes: cidr_netmask=24 ip=10.0.0.40 nic=ens192 Operations: monitor interval=10s timeout=10s (VirtualIP-monitor-interval-10s) start interval=0s timeout=20s (VirtualIP-start-interval-0s) stop interval=0s timeout=20s (VirtualIP-stop-interval-0s) Resource: VirtualIP2 (class=ocf provider=heartbeat type=IPaddr2) Attributes: cidr_netmask=24 ip=192.168.0.40 nic=ens224 Operations: monitor interval=10s timeout=10s (VirtualIP2-monitor-interval-10s) start interval=0s timeout=20s (VirtualIP2-start-interval-0s) stop interval=0s timeout=20s (VirtualIP2-stop-interval-0s) Clone: MariaDB-clone Meta Attrs: clone-max=2 clone-node-max=1 master-max=1 master-node-max=1 notify=true promotable=true Resource: MariaDB (class=ocf provider=heartbeat type=mysql) Attributes: binary=/usr/bin/mysqld_safe datadir=/var/lib/mysql log=/var/log/mariadb/mariadb.log \ pid=/run/mariadb/mariadb.pid replication_passwd=[パスワード] replication_user=repl Operations: demote interval=0s timeout=120s (MariaDB-demote-interval-0s) monitor interval=10s timeout=10s (MariaDB-monitor-interval-10s) notify interval=0s timeout=90s (MariaDB-notify-interval-0s) promote interval=0s timeout=120s (MariaDB-promote-interval-0s) start interval=0s timeout=120s (MariaDB-start-interval-0s) stop interval=0s timeout=120s (MariaDB-stop-interval-0s) Stonith Devices: Fencing Levels: Location Constraints: Resource: DRBD_r0-clone Enabled on: Node: centos8-str3 (score:100) (id:location-DRBD_r0-clone-centos8-str3-100) Resource: MariaDB-clone Enabled on: Node: centos8-str3 (score:100) (id:location-MariaDB-clone-centos8-str3-100) Ordering Constraints: promote MariaDB-clone then start zabbix-group (kind:Mandatory) (id:order-MariaDB-clone-zabbix-group-mandatory) Colocation Constraints: zabbix-group with MariaDB-clone (score:INFINITY) (rsc-role:Started) (with-rsc-role:Master) (id:colocation-zabbix-group-MariaDB-clone-INFINITY) MariaDB-clone with zabbix-server (score:INFINITY) (rsc-role:Master) (with-rsc-role:Started) (id:colocation-MariaDB-clone-zabbix-server-INFINITY) MariaDB-clone with Apache (score:INFINITY) (rsc-role:Master) (with-rsc-role:Started) (id:colocation-MariaDB-clone-Apache-INFINITY) MariaDB-clone with php-fpm (score:INFINITY) (rsc-role:Master) (with-rsc-role:Started) (id:colocation-MariaDB-clone-php-fpm-INFINITY) MariaDB-clone with VirtualIP (score:INFINITY) (rsc-role:Master) (with-rsc-role:Started) (id:colocation-MariaDB-clone-VirtualIP-INFINITY) MariaDB-clone with VirtualIP2 (score:INFINITY) (rsc-role:Master) (with-rsc-role:Started) (id:colocation-MariaDB-clone-VirtualIP2-INFINITY) DRBD_r0-clone with zabbix-group (score:INFINITY) (rsc-role:Master) (with-rsc-role:Started) (id:colocation-DRBD_r0-clone-zabbix-group-INFINITY) Ticket Constraints: Alerts: No alerts defined Resources Defaults: Meta Attrs: rsc_defaults-meta_attributes migration-threshold=1 resource-stickiness=INFINITY Operations Defaults: No defaults set Cluster Properties: MariaDB_REPL_INFO: centos8-str3.bigbang.mydns.jp|mysql-bin.000009|342 cluster-infrastructure: corosync cluster-name: bigbang dc-version: 2.0.5-9.el8-ba59be7122 have-watchdog: false last-lrm-refresh: 1619074041 no-quorum-policy: ignore stonith-enabled: false Tags: No tags defined Quorum: Options:
プロセスを停止した場合(Apache)(CentOS Stream 8)
1回でもfail-countがカウントされるとフェールオーバーするように設定していない場合、migration-thresholdのデフォルト値(migration-threshold=1000000)を変更してフェールオーバーするようにします。[root@centos8-str3 ~]# pcs resource defaults migration-threshold=1Apacheのサービスを停止し、リソースが他のホストに移動しているか確認します。[root@centos8-str3 ~]# kill -kill `pgrep -f httpd` [root@centos8-str3 ~]# ps axu | grep http[d] [root@centos8-str3 ~]# pcs status --full全てのリソースが他のホストに移動しています。Cluster name: bigbang Cluster Summary: * Stack: corosync * Current DC: centos8-str3 (1) (version 2.0.5-9.el8-ba59be7122) - partition with quorum * Last updated: Mon Apr 26 11:37:59 2021 * Last change: Mon Apr 26 11:37:37 2021 by root via crm_attribute on centos8-str4 * 2 nodes configured * 10 resource instances configured Node List: * Online: [ centos8-str3 (1) centos8-str4 (2) ] Full List of Resources: * Clone Set: DRBD_r0-clone [DRBD_r0] (promotable): * DRBD_r0 (ocf::linbit:drbd): Master centos8-str4 * DRBD_r0 (ocf::linbit:drbd): Slave centos8-str3 * Resource Group: zabbix-group: * FS_DRBD0 (ocf::heartbeat:Filesystem): Started centos8-str4 * Apache (ocf::heartbeat:apache): Started centos8-str4 * php-fpm (systemd:php-fpm): Started centos8-str4 * zabbix-server (systemd:zabbix-server): Started centos8-str4 * VirtualIP (ocf::heartbeat:IPaddr2): Started centos8-str4 * VirtualIP2 (ocf::heartbeat:IPaddr2): Started centos8-str4 * Clone Set: MariaDB-clone [MariaDB] (promotable): * MariaDB (ocf::heartbeat:mysql): Master centos8-str4 * MariaDB (ocf::heartbeat:mysql): Slave centos8-str3 Node Attributes: * Node: centos8-str3 (1): * master-DRBD_r0 : 10000 * master-MariaDB : 1 * readable : 1 * Node: centos8-str4 (2): * master-DRBD_r0 : 10000 * master-MariaDB : 3601 * readable : 1 Migration Summary: * Node: centos8-str3 (1): * Apache: migration-threshold=1 fail-count=1 last-failure='Mon Apr 26 11:37:30 2021' Failed Resource Actions: * Apache_monitor_10000 on centos8-str3 'not running' (7): call=377, status='complete', exitreason='', \ last-rc-change='2021-04-26 11:37:30 +09:00', queued=0ms, exec=0ms Tickets: PCSD Status: centos8-str3: Online centos8-str4: Online Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled
エラーをクリアし、再度Apacheのサービスを停止させリソースを元のホストに移動させます。[root@centos8-str4 ~]# pcs resource cleanup Apacheリソース及びMasterがcentos8-str3に戻っています。Cleaned up FS_DRBD0 on centos8-str4 Cleaned up FS_DRBD0 on centos8-str3 Cleaned up Apache on centos8-str4 Cleaned up Apache on centos8-str3 Cleaned up php-fpm on centos8-str4 Cleaned up php-fpm on centos8-str3 Cleaned up zabbix-server on centos8-str4 Cleaned up zabbix-server on centos8-str3 Cleaned up VirtualIP on centos8-str4 Cleaned up VirtualIP on centos8-str3 Cleaned up VirtualIP2 on centos8-str4 Cleaned up VirtualIP2 on centos8-str3 Waiting for 1 reply from the controller ... got reply (done)[root@centos8-str4 ~]# kill -kill `pgrep -f httpd` [root@centos8-str4 ~]# ps axu | grep http[d] [root@centos8-str4 ~]# pcs status --fullCluster name: bigbang Cluster Summary: * Stack: corosync * Current DC: centos8-str3 (1) (version 2.0.5-9.el8-ba59be7122) - partition with quorum * Last updated: Mon Apr 26 11:49:00 2021 * Last change: Mon Apr 26 11:48:48 2021 by root via crm_attribute on centos8-str3 * 2 nodes configured * 10 resource instances configured Node List: * Online: [ centos8-str3 (1) centos8-str4 (2) ] Full List of Resources: * Clone Set: DRBD_r0-clone [DRBD_r0] (promotable): * DRBD_r0 (ocf::linbit:drbd): Slave centos8-str4 * DRBD_r0 (ocf::linbit:drbd): Master centos8-str3 * Resource Group: zabbix-group: * FS_DRBD0 (ocf::heartbeat:Filesystem): Started centos8-str3 * Apache (ocf::heartbeat:apache): Started centos8-str3 * php-fpm (systemd:php-fpm): Started centos8-str3 * zabbix-server (systemd:zabbix-server): Started centos8-str3 * VirtualIP (ocf::heartbeat:IPaddr2): Started centos8-str3 * VirtualIP2 (ocf::heartbeat:IPaddr2): Started centos8-str3 * Clone Set: MariaDB-clone [MariaDB] (promotable): * MariaDB (ocf::heartbeat:mysql): Slave centos8-str4 * MariaDB (ocf::heartbeat:mysql): Master centos8-str3 Node Attributes: * Node: centos8-str3 (1): * master-DRBD_r0 : 10000 * master-MariaDB : 3601 * readable : 1 * Node: centos8-str4 (2): * master-DRBD_r0 : 10000 * master-MariaDB : 1 * readable : 1 Migration Summary: * Node: centos8-str4 (2): * Apache: migration-threshold=1 fail-count=1 last-failure='Mon Apr 26 11:48:41 2021' Failed Resource Actions: * Apache_monitor_10000 on centos8-str4 'not running' (7): call=375, status='complete', exitreason='', \ last-rc-change='2021-04-26 11:48:42 +09:00', queued=0ms, exec=0ms Tickets: PCSD Status: centos8-str3: Online centos8-str4: Online Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled
リソースのエラー表示をクリーンアップして終了です。[root@centos8-str4 ~]# pcs resource cleanup ApacheCleaned up FS_DRBD0 on centos8-str4 Cleaned up FS_DRBD0 on centos8-str3 Cleaned up Apache on centos8-str4 Cleaned up Apache on centos8-str3 Cleaned up php-fpm on centos8-str4 Cleaned up php-fpm on centos8-str3 Cleaned up zabbix-server on centos8-str4 Cleaned up zabbix-server on centos8-str3 Cleaned up VirtualIP on centos8-str4 Cleaned up VirtualIP on centos8-str3 Cleaned up VirtualIP2 on centos8-str4 Cleaned up VirtualIP2 on centos8-str3 Waiting for 1 reply from the controller ... got reply (done)
●pacemakerでZabbix-Server(DRBDのMaster/Slave)+FileSystem・MariaDB・VirtualIP(2つ)・Apache・PHP-FPM・Zabix-Serverを制御する(CentOS Stream 8)
こちらの設定を参考にすることを推奨
クラスタの構成は下記のとおりです。
- DRBDの起動(リソース「DRBD_r0」)
IPアドレスが小さい方で優先的にMasterとして起動するように設定- FileSystem(DRBDをマウント)の設定(リソース「FS_DRBD0」)
DRBDのMaster側が有効化されてからマウントするように設定- MariaDBの設定(リソース「MariaDB」を)及び当該リソースをリソースグループ「zabbix-group」に追加
DRBDのMaster側で起動- VirtualIP(2つ)の設定(リソース「VirtualIP」、「VirtualIP2」)及び当該リソースをリソースグループ「zabbix-group」に追加
DRBDのMaster側で起動- Apacheの設定(リソース「httpd」)及び当該リソースをリソースグループ「zabbix-group」に追加
DRBDのMaster側で起動- PHP-FPMの設定(リソース「php-fpm」)及び当該リソースをリソースグループ「zabbix-group」に追加
DRBDのMaster側で起動- Zabix-Serverの設定(リソース「zabbix-server」)及び当該リソースをリソースグループ「zabbix-group」に追加
DRBDのMaster側で起動- リソースグループ「zabbix-group」に追加はFS_DRBD0リソース起動してから起動
クラスタ構成(2台:centos8-str3、centos8-str4)の一方(centos8-str4)のカーネルを間違ってアップデートしてしまい、その際、pcsのバージョンもアップデート(pcs-0.10.12-2.el8.x86_64)してしまいました。
※結果的にpcs-0.10.12-2.el8.x86_6のバグだったようです。(1月25日時点で、pcs-0.10.12-3.el8.x86_64にアップデートしていました)
一度、クラスタ構成を破棄し、再度、クラスタを構成するために実施した時の作業記録です。
ちなみに、kernel、corosync、pacemaker、pcsを元に戻し、クラスタに再追加しても動作しませんでした(単純なクラスタ構成であればクラスタに追加することで正常に動作するかどうかは検証が必要かもしれません。検証結果は「クラスタ削除・追加による動作確認」を参照)。
カーネルをアップデートしてしまったクラスタ構成(アップデートしたノードはクラスタから削除済み)の状態を確認します。※centos8-str4はクラスタ構成から削除済です。 [root@centos8-str3 ~]# pcs statusconfigの内容は下記のとおりです。Cluster name: bigbang Cluster Summary: * Stack: corosync * Current DC: centos8-str3 (version 2.0.5-9.el8_4.1-ba59be7122) - partition with quorum * Last updated: Mon Jan 24 22:18:57 2022 * Last change: Mon Jan 24 18:28:42 2022 by root via cibadmin on centos8-str3 * 1 node configured * 9 resource instances configured Node List: * Online: [ centos8-str3 ] Full List of Resources: * Clone Set: DRBD_r0-clone [DRBD_r0] (promotable): * Masters: [ centos8-str3 ] * FS_DRBD0 (ocf::heartbeat:Filesystem): Started centos8-str3 * Resource Group: zabbix-group: * MariaDB (systemd:mariadb): Started centos8-str3 * VirtualIP (ocf::heartbeat:IPaddr2): Started centos8-str3 * VirtualIP2 (ocf::heartbeat:IPaddr2): Started centos8-str3 * httpd (systemd:httpd): Started centos8-str3 * php-fpm (systemd:httpd): Started centos8-str3 * zabbix-server (systemd:zabbix-server): Started centos8-str3 Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled※centos8-str4はクラスタ構成から削除済です。 [root@centos8-str3 ~]# pcs config show以降の作業は、コピーした仮想マシンを利用します。Cluster Name: bigbang Corosync Nodes: centos8-str3 Pacemaker Nodes: centos8-str3 Resources: Clone: DRBD_r0-clone Meta Attrs: clone-max=2 clone-node-max=1 master-max=1 master-node-max=1 notify=true promotable=true Resource: DRBD_r0 (class=ocf provider=linbit type=drbd) Attributes: drbd_resource=r0 Operations: demote interval=0s timeout=90 (DRBD_r0-demote-interval-0s) monitor interval=20 role=Slave timeout=20 (DRBD_r0-monitor-interval-20) monitor interval=10 role=Master timeout=20 (DRBD_r0-monitor-interval-10) notify interval=0s timeout=90 (DRBD_r0-notify-interval-0s) promote interval=0s timeout=90 (DRBD_r0-promote-interval-0s) reload interval=0s timeout=30 (DRBD_r0-reload-interval-0s) start interval=0s timeout=240 (DRBD_r0-start-interval-0s) stop interval=0s timeout=100 (DRBD_r0-stop-interval-0s) Resource: FS_DRBD0 (class=ocf provider=heartbeat type=Filesystem) Attributes: device=/dev/drbd0 directory=/mnt fstype=xfs Operations: monitor interval=20s timeout=40s (FS_DRBD0-monitor-interval-20s) start interval=0s timeout=60s (FS_DRBD0-start-interval-0s) stop interval=0s timeout=60s (FS_DRBD0-stop-interval-0s) Group: zabbix-group Resource: MariaDB (class=systemd type=mariadb) Operations: monitor interval=60 timeout=100 (MariaDB-monitor-interval-60) start interval=0s timeout=100 (MariaDB-start-interval-0s) stop interval=0s timeout=100 (MariaDB-stop-interval-0s) Resource: VirtualIP (class=ocf provider=heartbeat type=IPaddr2) Attributes: cidr_netmask=24 ip=1.0.0.40 nic=ens192 Operations: monitor interval=30s (VirtualIP-monitor-interval-30s) start interval=0s timeout=20s (VirtualIP-start-interval-0s) stop interval=0s timeout=20s (VirtualIP-stop-interval-0s) Resource: VirtualIP2 (class=ocf provider=heartbeat type=IPaddr2) Attributes: cidr_netmask=24 ip=192.168.111.40 nic=ens224 Operations: monitor interval=10s timeout=10s (VirtualIP2-monitor-interval-10s) start interval=0s timeout=20s (VirtualIP2-start-interval-0s) stop interval=0s timeout=20s (VirtualIP2-stop-interval-0s) Resource: httpd (class=systemd type=httpd) Operations: monitor interval=60 timeout=100 (httpd-monitor-interval-60) start interval=0s timeout=100 (httpd-start-interval-0s) stop interval=0s timeout=100 (httpd-stop-interval-0s) Resource: php-fpm (class=systemd type=httpd) Operations: monitor interval=60 timeout=100 (php-fpm-monitor-interval-60) start interval=0s timeout=100 (php-fpm-start-interval-0s) stop interval=0s timeout=100 (php-fpm-stop-interval-0s) Resource: zabbix-server (class=systemd type=zabbix-server) Operations: monitor interval=60 timeout=100 (zabbix-server-monitor-interval-60) start interval=0s timeout=100 (zabbix-server-start-interval-0s) stop interval=0s timeout=100 (zabbix-server-stop-interval-0s) Stonith Devices: Fencing Levels: Location Constraints: Resource: DRBD_r0-clone Enabled on: Node: centos8-str3 (score:100) (id:location-DRBD_r0-clone-centos8-str3-100) Disabled on: Node: centos8-str4 (score:-INFINITY) (role:Started) (id:cli-ban-DRBD_r0-clone-on-centos8-str4) Ordering Constraints: promote DRBD_r0-clone then start zabbix-group (kind:Mandatory) (id:order-DRBD_r0-clone-zabbix-group-mandatory) Colocation Constraints: DRBD_r0-clone with FS_DRBD0 (score:INFINITY) (rsc-role:Started) (with-rsc-role:Master) (id:colocation-DRBD_r0-clone-FS_DRBD0-INFINITY) DRBD_r0-clone with MariaDB (score:INFINITY) (rsc-role:Master) (with-rsc-role:Started) (id:colocation-DRBD_r0-clone-MariaDB-INFINITY) DRBD_r0-clone with VirtualIP (score:INFINITY) (rsc-role:Master) (with-rsc-role:Started) (id:colocation-DRBD_r0-clone-VirtualIP-INFINITY) DRBD_r0-clone with VirtualIP2 (score:INFINITY) (rsc-role:Master) (with-rsc-role:Started) (id:colocation-DRBD_r0-clone-VirtualIP2-INFINITY) DRBD_r0-clone with httpd (score:INFINITY) (rsc-role:Master) (with-rsc-role:Started) (id:colocation-DRBD_r0-clone-httpd-INFINITY) DRBD_r0-clone with zabbix-server (score:INFINITY) (rsc-role:Master) (with-rsc-role:Started) (id:colocation-DRBD_r0-clone-zabbix-server-INFINITY) DRBD_r0-clone with php-fpm (score:INFINITY) (rsc-role:Master) (with-rsc-role:Started) (id:colocation-DRBD_r0-clone-php-fpm-INFINITY) Ticket Constraints: Alerts: No alerts defined Resources Defaults: Meta Attrs: rsc_defaults-meta_attributes failure-timeout=180s migration-threshold=3 resource-stickiness=INFINITY Operations Defaults: No defaults set Cluster Properties: MariaDB_REPL_INFO: centos8-str4.bigbang.dyndns.org|mysql-bin.000058|342 cluster-infrastructure: corosync cluster-name: bigbang dc-version: 2.0.5-9.el8_4.1-ba59be7122 have-watchdog: false last-lrm-refresh: 1643016370 no-quorum-policy: ignore stonith-enabled: false Tags: No tags defined Quorum: Options:
DRDBの動作確認
カーネルをアップデートするとしばしばDRBDが動作しなくなります。そのため、まず、現在の状態でDRBDの同期・プライマリ・セカンダリについて動作確認をしておきます。DRBDの動作確認は正常に終了しました。※centos8-str7、centos8-str8での作業です。 ※両ノードで実行 # vi /etc/drbd.d/r0.res resource r0 { on centos8-str7 { device /dev/drbd0; disk /dev/mapper/pool-data0; address 192.168.111.48:7789; meta-disk internal; } on centos8-str8 { device /dev/drbd0; disk /dev/mapper/pool-data0; address 192.168.111.49:7789; meta-disk internal; } } ※両ノードで実行 DRDBのメタデータを両ノードで初期化 # drbdadm create-md r0 You want me to create a v09 style flexible-size internal meta data block. There appears to be a v09 flexible-size internal meta data block already in place on /dev/mapper/pool-data0 at byte offset 53682892800 Do you really want to overwrite the existing meta-data? [need to type 'yes' to confirm] yes md_offset 53682892800 al_offset 53682860032 bm_offset 53681221632 Found xfs filesystem 52423068 kB data area apparently used 52423068 kB left usable by current configuration Even though it looks like this would place the new meta data into unused space, you still need to confirm, as this is only a guess. Do you want to proceed? [need to type 'yes' to confirm] yes initializing activity log initializing bitmap (1600 KB) to all zero Writing meta data... New drbd meta data block successfully created. ※両ノードで実行 # drbdadm up r0 [root@centos8-str7 ~]# drbdadm status r0 r0 role:Secondary disk:Inconsistent centos8-str8 role:Secondary peer-disk:Inconsistent centos8-str7をプライマリにし同期させます。 [root@centos8-str7 ~]# drbdadm primary --force r0 [root@centos8-str7 ~]# drbdadm status r0 r0 role:Primary disk:UpToDate centos8-str8 role:Secondary replication:SyncSource peer-disk:Inconsistent done:0.88 [root@centos8-str7 ~]# drbdadm status r0 r0 role:Primary disk:UpToDate centos8-str8 role:Secondary replication:SyncSource peer-disk:Inconsistent done:82.69 [root@centos8-str7 ~]# drbdadm status r0 r0 role:Primary disk:UpToDate centos8-str8 role:Secondary peer-disk:UpToDate 同期が完了しました。 DRBDを停止します。 [root@centos8-str8 ~]# drbdadm down r0 [root@centos8-str7 ~]# drbdadm down r0
kernel、corosync、pacemaker、pcsのバージョン確認
両ノードのkernel、corosync、pacemaker、pcsのバージョンを確認します。カーネルのバージョン以外は同じバージョンとなっています。※centos8-str7、centos8-str8での作業です。 root@centos8-str7 ~]# uname -r;rpm -qa|grep corosync|sort;rpm -qa|grep pacemaker|sort;rpm -qa|grep pcs|sort 4.18.0-305.3.1.el8.x86_64 corosync-3.1.0-5.el8.x86_64 corosynclib-3.1.0-5.el8.x86_64 pacemaker-2.0.5-9.el8_4.1.x86_64 pacemaker-cli-2.0.5-9.el8_4.1.x86_64 pacemaker-cluster-libs-2.0.5-9.el8_4.1.x86_64 pacemaker-libs-2.0.5-9.el8_4.1.x86_64 pacemaker-schemas-2.0.5-9.el8_4.1.noarch pcs-0.10.12-3.el8.x86_64 [root@centos8-str8 ~]# uname -r;rpm -qa|grep corosync|sort;rpm -qa|grep pacemaker|sort;rpm -qa|grep pcs|sort 4.18.0-358.el8.x86_64 corosync-3.1.0-5.el8.x86_64 corosynclib-3.1.0-5.el8.x86_64 pacemaker-2.0.5-9.el8_4.1.x86_64 pacemaker-cli-2.0.5-9.el8_4.1.x86_64 pacemaker-cluster-libs-2.0.5-9.el8_4.1.x86_64 pacemaker-libs-2.0.5-9.el8_4.1.x86_64 pacemaker-schemas-2.0.5-9.el8_4.1.noarch pcs-0.10.12-3.el8.x86_64
corosync、pacemakerのバージョンが同一でない場合、アップデートまたはダウングレードして同一バージョンにする必要があります。
一致していない場合、下記のようなエラーが表示されます。※centos8-str7、centos8-str8での作業です。 [root@centos8-str7 ~]# pcs cluster setup --start bigbang centos8-str7 addr=10.0.0.48 addr=192.168.111.48 centos8-str8 addr=10.0.0.49 addr=192.168.111.49 Error: Hosts do not have the same version of 'pacemaker'; host 'centos8-str8' has version 2.1.2; host 'centos8-str7' has version 2.0.5 Error: Hosts do not have the same version of 'corosync'; host 'centos8-str8' has version 3.1.5; host 'centos8-str7' has version 3.1.0 Error: Errors have occurred, therefore pcs is unable to continue [root@centos8-str8 ~]# dnf downgrade pacemaker-2.0.5 corosync-3.1.0
クラスタの構築
クラスタを構築します。
ただし、クラスタ用ユーザ・/etc/hosts・ファイアーウォール・クラスタ認証設定は完了しているものとします。
centos8-str3、centos8-str4でのクラスタ設定時とは環境が異なるためか同じ動作をさせようとしても設定方法が異なるようです。kernelバージョンが異なっていても、corosync・pacemaker・pcsの各バージョンが同一であれば、クラスタが正常に動作することが確認できました。下記コマンドをコピペして実行することで、障害等により問題が発生(単純なノード追加で想定しているクラスタ構成が戻らない等)した
クラスタの再設定を短時間で設定することが可能です。 現在のクラスタ設定を破棄します。 ※両ノードで実行 # pcs cluster stop --all # pcs cluster destroy ※両ノードで実行 # systemctl enable --now pcsd ※片方のノードで実行 [root@centos8-str7 ~]# pcs cluster setup --start bigbang centos8-str7 addr=10.0.0.48 addr=192.168.111.48 \ centos8-str8 addr=10.0.0.49 addr=192.168.111.49 [root@centos8-str7 ~]# pcs property set stonith-enabled=false [root@centos8-str7 ~]# pcs property set no-quorum-policy=ignore [root@centos8-str7 ~]# pcs resource defaults failure-timeout=180s Warning: This command is deprecated and will be removed. Please use 'pcs resource defaults update' instead. Warning: Defaults do not apply to resources which override them with their own defined values ※Warningは無視してください。 [root@centos8-str7 ~]# pcs resource defaults migration-threshold=3 Warning: This command is deprecated and will be removed. Please use 'pcs resource defaults update' instead. Warning: Defaults do not apply to resources which override them with their own defined values ※Warningは無視してください。 [root@centos8-str7 ~]# pcs resource defaults resource-stickiness=INFINITY Warning: This command is deprecated and will be removed. Please use 'pcs resource defaults update' instead. Warning: Defaults do not apply to resources which override them with their own defined values ※Warningは無視してください。 [root@centos8-str7 ~]# pcs resource create DRBD_r0 ocf:linbit:drbd drbd_resource=r0 [root@centos8-str7 ~]# pcs resource promotable DRBD_r0 master-max=1 master-node-max=1 clone-max=2 clone-node-max=1 notify=true [root@centos8-str7 ~]# pcs resource cleanup DRBD_r0 [root@centos8-str7 ~]# pcs resource create FS_DRBD0 ocf:heartbeat:Filesystem device=/dev/drbd0 directory=/mnt fstype=xfs [root@centos8-str7 ~]# pcs resource create MariaDB systemd:mariadb --group zabbix-group [root@centos8-str7 ~]# pcs resource cleanup [root@centos8-str7 ~]# pcs resource create VirtualIP ocf:heartbeat:IPaddr2 ip=10.0.0.39 cidr_netmask=24 nic=ens192 op \ monitor interval=30s --group zabbix-group [root@centos8-str7 ~]# pcs resource create VirtualIP2 ocf:heartbeat:IPaddr2 ip=192.168.111.39 cidr_netmask=24 nic=ens224 op \ monitor interval=30s --group zabbix-group [root@centos8-str7 ~]# pcs resource create httpd systemd:httpd --group zabbix-group [root@centos8-str7 ~]# pcs resource create php-fpm systemd:php-fpm --group zabbix-group [root@centos8-str7 ~]# pcs resource create zabbix-server systemd:zabbix-server --group zabbix-group ## DRBD_r0は優先的にcentos8-str7がMasterとして起動するように設定 [root@centos8-str7 ~]# pcs constraint location DRBD_r0-clone prefers centos8-str7=100 ## DRBD_r0がMaster側のノードでFS_DRBD0リソースを起動するように設定 [root@centos8-str7 ~]# pcs constraint order promote DRBD_r0-clone then start FS_DRBD0 ## FS_DRBD0はDRBD_r0のMasterと同じノードで起動(異常検知で必要) [root@centos8-str7 ~]# pcs constraint colocation add master DRBD_r0-clone with FS_DRBD0 INFINITY ## MariaDBはDRBD_r0のMasterと同じノードで起動(異常検知で必要) [root@centos8-str7 ~]# pcs constraint colocation add master DRBD_r0-clone with MariaDB INFINITY ## VirtualIPはDRBD_r0のMasterと同じノードで起動(異常検知で必要) [root@centos8-str7 ~]# pcs constraint colocation add master DRBD_r0-clone with VirtualIP INFINITY ## VirtualIP2はDRBD_r0のMasterと同じノードで起動(異常検知で必要) [root@centos8-str7 ~]# pcs constraint colocation add master DRBD_r0-clone with VirtualIP2 INFINITY ## httpdはDRBD_r0のMasterと同じノードで起動(異常検知で必要) [root@centos8-str7 ~]# pcs constraint colocation add master DRBD_r0-clone with httpd INFINITY ## php-fpmはDRBD_r0のMasterと同じノードで起動(異常検知で必要) [root@centos8-str7 ~]# pcs constraint colocation add master DRBD_r0-clone with php-fpm INFINITY ## zabbix-serverはDRBD_r0のMasterと同じノードで起動(異常検知で必要) [root@centos8-str7 ~]# pcs constraint colocation add master DRBD_r0-clone with zabbix-server INFINITY ## FS_DRBD0が起動してからzabbix-groupを起動するように設定 [root@centos8-str7 ~]# pcs constraint order FS_DRBD0 then start zabbix-group
ーーーーーーーーーー
centos8-str3、centos8-str4のクラスタの設定は2022年1月28日時点で下記のバージョンで設定することとします。[root@centos8-str3 ~]# uname -r;rpm -qa|grep corosync|sort;rpm -qa|grep pacemaker|sort;rpm -qa|grep pcs|sort 4.18.0-358.el8.x86_64 corosync-3.1.5-2.el8.x86_64 corosynclib-3.1.5-2.el8.x86_64 pacemaker-2.1.2-2.el8.x86_64 pacemaker-cli-2.1.2-2.el8.x86_64 pacemaker-cluster-libs-2.1.2-2.el8.x86_64 pacemaker-libs-2.1.2-2.el8.x86_64 pacemaker-schemas-2.1.2-2.el8.noarch pcs-0.10.12-3.el8.x86_64
結果は元の状態の時と同じようにクラスタが動作するようになりました。
ーーーーーーーーーー
上記(centos8-str7、centos8-str8)で設定したconfigの内容は下記のとおりです。[root@centos8-str8 ~]# pcs config show下記はcentos8-str7、centos8-str8でクラスタ設定方法を確定するに至るまでに実施した作業記録です。Cluster Name: bigbang Corosync Nodes: centos8-str7 centos8-str8 Pacemaker Nodes: centos8-str7 centos8-str8 Resources: Clone: DRBD_r0-clone Meta Attrs: clone-max=2 clone-node-max=1 master-max=1 master-node-max=1 notify=true promotable=true Resource: DRBD_r0 (class=ocf provider=linbit type=drbd) Attributes: drbd_resource=r0 Operations: demote interval=0s timeout=90 (DRBD_r0-demote-interval-0s) monitor interval=20 role=Slave timeout=20 (DRBD_r0-monitor-interval-20) monitor interval=10 role=Master timeout=20 (DRBD_r0-monitor-interval-10) notify interval=0s timeout=90 (DRBD_r0-notify-interval-0s) promote interval=0s timeout=90 (DRBD_r0-promote-interval-0s) reload interval=0s timeout=30 (DRBD_r0-reload-interval-0s) start interval=0s timeout=240 (DRBD_r0-start-interval-0s) stop interval=0s timeout=100 (DRBD_r0-stop-interval-0s) Resource: FS_DRBD0 (class=ocf provider=heartbeat type=Filesystem) Attributes: device=/dev/drbd0 directory=/mnt fstype=xfs Operations: monitor interval=20s timeout=40s (FS_DRBD0-monitor-interval-20s) start interval=0s timeout=60s (FS_DRBD0-start-interval-0s) stop interval=0s timeout=60s (FS_DRBD0-stop-interval-0s) Group: zabbix-group Resource: MariaDB (class=systemd type=mariadb) Operations: monitor interval=60 timeout=100 (MariaDB-monitor-interval-60) start interval=0s timeout=100 (MariaDB-start-interval-0s) stop interval=0s timeout=100 (MariaDB-stop-interval-0s) Resource: VirtualIP (class=ocf provider=heartbeat type=IPaddr2) Attributes: cidr_netmask=24 ip=10.0.0.39 nic=ens192 Operations: monitor interval=30s (VirtualIP-monitor-interval-30s) start interval=0s timeout=20s (VirtualIP-start-interval-0s) stop interval=0s timeout=20s (VirtualIP-stop-interval-0s) Resource: VirtualIP2 (class=ocf provider=heartbeat type=IPaddr2) Attributes: cidr_netmask=24 ip=192.168.111.39 nic=ens224 Operations: monitor interval=30s (VirtualIP2-monitor-interval-30s) start interval=0s timeout=20s (VirtualIP2-start-interval-0s) stop interval=0s timeout=20s (VirtualIP2-stop-interval-0s) Resource: httpd (class=systemd type=httpd) Operations: monitor interval=60 timeout=100 (httpd-monitor-interval-60) start interval=0s timeout=100 (httpd-start-interval-0s) stop interval=0s timeout=100 (httpd-stop-interval-0s) Resource: php-fpm (class=systemd type=php-fpm) Operations: monitor interval=60 timeout=100 (php-fpm-monitor-interval-60) start interval=0s timeout=100 (php-fpm-start-interval-0s) stop interval=0s timeout=100 (php-fpm-stop-interval-0s) Resource: zabbix-server (class=systemd type=zabbix-server) Operations: monitor interval=60 timeout=100 (zabbix-server-monitor-interval-60) start interval=0s timeout=100 (zabbix-server-start-interval-0s) stop interval=0s timeout=100 (zabbix-server-stop-interval-0s) Stonith Devices: Fencing Levels: Location Constraints: Resource: DRBD_r0-clone Enabled on: Node: centos8-str7 (score:100) (id:location-DRBD_r0-clone-centos8-str7-100) Ordering Constraints: promote DRBD_r0-clone then start FS_DRBD0 (kind:Mandatory) (id:order-DRBD_r0-clone-FS_DRBD0-mandatory) start FS_DRBD0 then start zabbix-group (kind:Mandatory) (id:order-FS_DRBD0-zabbix-group-mandatory) Colocation Constraints: DRBD_r0-clone with FS_DRBD0 (score:INFINITY) (rsc-role:Master) (with-rsc-role:Started) (id:colocation-DRBD_r0-clone-FS_DRBD0-INFINITY) DRBD_r0-clone with MariaDB (score:INFINITY) (rsc-role:Master) (with-rsc-role:Started) (id:colocation-DRBD_r0-clone-MariaDB-INFINITY) DRBD_r0-clone with VirtualIP (score:INFINITY) (rsc-role:Master) (with-rsc-role:Started) (id:colocation-DRBD_r0-clone-VirtualIP-INFINITY) DRBD_r0-clone with VirtualIP2 (score:INFINITY) (rsc-role:Master) (with-rsc-role:Started) (id:colocation-DRBD_r0-clone-VirtualIP2-INFINITY) DRBD_r0-clone with httpd (score:INFINITY) (rsc-role:Master) (with-rsc-role:Started) (id:colocation-DRBD_r0-clone-httpd-INFINITY) DRBD_r0-clone with php-fpm (score:INFINITY) (rsc-role:Master) (with-rsc-role:Started) (id:colocation-DRBD_r0-clone-php-fpm-INFINITY) DRBD_r0-clone with zabbix-server (score:INFINITY) (rsc-role:Master) (with-rsc-role:Started) (id:colocation-DRBD_r0-clone-zabbix-server-INFINITY) Ticket Constraints: Alerts: No alerts defined Resources Defaults: Meta Attrs: rsc_defaults-meta_attributes failure-timeout=180s migration-threshold=3 resource-stickiness=INFINITY Operations Defaults: No defaults set Cluster Properties: cluster-infrastructure: corosync cluster-name: bigbang dc-version: 2.0.5-9.el8_4.1-ba59be7122 have-watchdog: false last-lrm-refresh: 1643265079 no-quorum-policy: ignore stonith-enabled: false Tags: No tags defined Quorum: Options:
動作確認のためリソースを1つずつ設定し、そのたびにクラスタのフェールオーバー・フェールセーフを実施して正常に動作するか確認しました。
切替時の動作が正常とならない場合、起動制約(pcs constraint colocation)及び順序制約(pcs constraint order)を追加設定して確認しました。
このように、リソース追加・起動制約追加のセットを繰り返しながら作業するのですが、複雑な設定の場合、全ての作業終了後に最終チェック(フェールオーバー・フェールセーフ・再起動等)すると想定通り動作しないことがありました。
その場合、クラスタの設定方法が確定後、一度、クラスタ設定(両ノードとも)を破棄し、再度全リソースを設定、全起動制約を設定することで想定通り動作するようになりました。
そのため、単純な「●クラスタノードの追加と削除」でクラスタ機能が復帰しない場合でも、設定手順を残しておくことで障害から復帰させる時に作業時間が短くなると思い、今回はそのようにしました。ーーーーー 動作確認のための作業記録 ーーーーー ※片方のノードで実行 [root@centos8-str7 ~]# pcs cluster setup --start bigbang centos8-str7 addr=10.0.0.48 addr=192.168.111.48 \ centos8-str8 addr=10.0.0.49 addr=192.168.111.49 [root@centos8-str7 ~]# pcs node standby centos8-str8 [root@centos8-str7 ~]# pcs property set stonith-enabled=false [root@centos8-str7 ~]# pcs property set no-quorum-policy=ignore [root@centos8-str7 ~]# pcs resource defaults failure-timeout=300s [root@centos8-str7 ~]# pcs resource defaults migration-threshold=3 [root@centos8-str7 ~]# pcs resource defaults migration-threshold=1 Warning: This command is deprecated and will be removed. Please use 'pcs resource defaults update' instead. Warning: Defaults do not apply to resources which override them with their own defined values ※Warningは無視してください。 [root@centos8-str7 ~]# pcs resource defaults resource-stickiness=INFINITY Warning: This command is deprecated and will be removed. Please use 'pcs resource defaults update' instead. Warning: Defaults do not apply to resources which override them with their own defined values ※Warningは無視してください。 [root@centos8-str7 ~]# pcs resource create DRBD_r0 ocf:linbit:drbd drbd_resource=r0 [root@centos8-str7 ~]# pcs resource promotable DRBD_r0 master-max=1 master-node-max=1 clone-max=2 clone-node-max=1 notify=true [root@centos8-str7 ~]# pcs constraint location DRBD_r0-clone prefers centos8-str7=100 ← ① ↑ これを設定するとcentos8-str7が復帰した場合、必ずcentos8-str7がMasterとなってしまう。 ↑ centos8-str3・4では設定したが環境が違うためなのか、設定する必要がないようだ。 [root@centos8-str7 ~]# pcs constraint location DRBD_r0-clone prefers centos8-str7=100 ↑ (何回か試験したのだけれど・・・)クラスタをdestroyして、再設定したらcentos8-str3・4と同様の動作をするようになった [root@centos8-str7 ~]# pcs resource cleanup DRBD_r0 [root@centos8-str7 ~]# pcs resource create FS_DRBD0 ocf:heartbeat:Filesystem device=/dev/drbd0 directory=/mnt fstype=xfs ## DRBD_r0がMaster側のノードでFS_DRBD0リソースを起動するように設定 [root@centos8-str7 ~]# pcs constraint colocation add DRBD_r0-clone with Master FS_DRBD0 [root@centos8-str7 ~]# pcs constraint colocation add master DRBD_r0-clone with FS_DRBD0 INFINITY ## DRBD_r0起動後にFS_DRBD0リソースを起動 [root@centos8-str7 ~]# pcs constraint order promote DRBD_r0-clone then start FS_DRBD0 ← ② ↑ これを設定するとDRBD_r0-clone及びFS_DRBD0がStartしない。 ↑ centos8-str3・4では設定したが環境が違うためなのか、設定する必要がないようだ。 [root@centos8-str7 ~]# pcs constraint order promote DRBD_r0-clone then start FS_DRBD0 ↑ (何回か試験したのだけれど・・・)クラスタをdestroyして、再設定したらcentos8-str3・4と同様の動作をするようになった ①及び②を設定していない場合、クラスタを再起動(pcs cluster stop --all;pcs cluster start --all)するとエラーが発生し、 \ 必ず起動しなくなってしまう。 ①及び②を設定していない場合、クラスタを確実に起動するにはいずれか一方のノードを先に起動し、全サービス起動後、 \ 他方のノードを起動すると正常にクラスタとして機能する。 [root@centos8-str7 ~]# pcs resource create MariaDB systemd:mariadb --group zabbix-group [root@centos8-str7 ~]# pcs resource cleanup ## MariaDBはDRBD_r0のMasterと同じノードで起動(異常検知で必要) [root@centos8-str7 ~]# pcs constraint colocation add master DRBD_r0-clone with MariaDB INFINITY ## DRBD_r0がMaster側のノードでzabbix-groupを起動するように設定 [root@centos8-str7 ~]# pcs constraint order promote DRBD_r0-clone then start zabbix-group ## FS_DRBD0が起動してからzabbix-groupを起動するように設定 [root@centos8-str7 ~]# pcs constraint order FS_DRBD0 then start zabbix-group [root@centos8-str7 ~]# pcs resource create VirtualIP ocf:heartbeat:IPaddr2 ip=10.0.0.39 cidr_netmask=24 nic=ens192 \ op monitor interval=30s --group zabbix-group ## VirtualIPはDRBD_r0のMasterと同じノードで起動(異常検知で必要) [root@centos8-str7 ~]# pcs constraint colocation add master DRBD_r0-clone with VirtualIP INFINITY [root@centos8-str7 ~]# pcs resource create VirtualIP2 ocf:heartbeat:IPaddr2 ip=192.168.111.39 cidr_netmask=24 nic=ens224 \ op monitor interval=30s --group zabbix-group ## VirtualIP2はDRBD_r0のMasterと同じノードで起動(異常検知で必要) [root@centos8-str7 ~]# pcs constraint colocation add master DRBD_r0-clone with VirtualIP2 INFINITY [root@centos8-str7 ~]# pcs resource create httpd systemd:httpd --group zabbix-group ## httpdはDRBD_r0のMasterと同じノードで起動(異常検知で必要) [root@centos8-str7 ~]# pcs constraint colocation add master DRBD_r0-clone with httpd INFINITY [root@centos8-str7 ~]# pcs resource create php-fpm systemd:php-fpm --group zabbix-group ## php-fpmはDRBD_r0のMasterと同じノードで起動(異常検知で必要) [root@centos8-str7 ~]# pcs constraint colocation add master DRBD_r0-clone with php-fpm INFINITY [root@centos8-str7 ~]# pcs resource create zabbix-server systemd:zabbix-server --group zabbix-group ## zabbix-serverはDRBD_r0のMasterと同じノードで起動(異常検知で必要) [root@centos8-str7 ~]# pcs constraint colocation add master DRBD_r0-clone with zabbix-server INFINITY ## zabbix-groupはDRBD_r0のMasterと同じノードで起動 [root@centos8-str1 ~]# pcs constraint colocation add zabbix-group with Master DRBD_r0-clone INFINITY ↑ この設定をしなくても正常にMaster/Slaveが切り替わります。 [root@centos8-str7 ~]# pcs resource cleanup Cleaned up all resources on all nodes ※クラスタの状態を確認します。 [root@centos8-str7 ~]# pcs status Cluster name: bigbang Cluster Summary: * Stack: corosync * Current DC: centos8-str8 (version 2.0.5-9.el8_4.1-ba59be7122) - partition with quorum * Last updated: Tue Jan 25 17:11:00 2022 * Last change: Tue Jan 25 17:10:10 2022 by root via crm_resource on centos8-str7 * 2 nodes configured * 9 resource instances configured Node List: * Online: [ centos8-str7 centos8-str8 ] Full List of Resources: * Clone Set: DRBD_r0-clone [DRBD_r0] (promotable): * Masters: [ centos8-str7 ] * Slaves: [ centos8-str8 ] * FS_DRBD0 (ocf::heartbeat:Filesystem): Started centos8-str7 * Resource Group: zabbix-group: * MariaDB (systemd:mariadb): Started centos8-str7 * VirtualIP (ocf::heartbeat:IPaddr2): Started centos8-str7 * VirtualIP2 (ocf::heartbeat:IPaddr2): Started centos8-str7 * httpd (systemd:httpd): Started centos8-str7 * php-fpm (systemd:php-fpm): Started centos8-str7 * zabbix-server (systemd:zabbix-server): Started centos8-str7 Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled
クラスタ設定の再構築
centos8-str3、centos8-str4のクラスタを再構築します。下記コマンドをコピペして実行することで、障害等により問題が発生(単純なノード追加で想定しているクラスタ構成が戻らない等)した クラスタの再設定を短時間で設定することが可能です。 現在のクラスタ設定を破棄します。 ※両ノードで実行 # pcs cluster stop --all # pcs cluster destroy ※両ノードで実行 # systemctl enable --now pcsd ※片方のノードで実行 [root@centos8-str3 ~]# pcs cluster setup --start bigbang centos8-str3 addr=10.0.0.43 addr=192.168.111.43 \ centos8-str4 addr=10.0.0.44 addr=192.168.111.44 [root@centos8-str3 ~]# pcs property set stonith-enabled=false [root@centos8-str3 ~]# pcs property set no-quorum-policy=ignore [root@centos8-str3 ~]# pcs resource defaults failure-timeout=180s Warning: This command is deprecated and will be removed. Please use 'pcs resource defaults update' instead. Warning: Defaults do not apply to resources which override them with their own defined values ※Warningは無視してください。 [root@centos8-str3 ~]# pcs resource defaults migration-threshold=3 Warning: This command is deprecated and will be removed. Please use 'pcs resource defaults update' instead. Warning: Defaults do not apply to resources which override them with their own defined values ※Warningは無視してください。 [root@centos8-str3 ~]# pcs resource defaults resource-stickiness=INFINITY Warning: This command is deprecated and will be removed. Please use 'pcs resource defaults update' instead. Warning: Defaults do not apply to resources which override them with their own defined values ※Warningは無視してください。 [root@centos8-str3 ~]# pcs resource create DRBD_r0 ocf:linbit:drbd drbd_resource=r0 [root@centos8-str3 ~]# pcs resource promotable DRBD_r0 master-max=1 master-node-max=1 clone-max=2 clone-node-max=1 notify=true [root@centos8-str3 ~]# pcs resource cleanup DRBD_r0 [root@centos8-str3 ~]# pcs resource create FS_DRBD0 ocf:heartbeat:Filesystem device=/dev/drbd0 directory=/mnt fstype=xfs [root@centos8-str3 ~]# pcs resource create MariaDB systemd:mariadb --group zabbix-group [root@centos8-str3 ~]# pcs resource cleanup [root@centos8-str3 ~]# pcs resource create VirtualIP ocf:heartbeat:IPaddr2 ip=1.0.0.40 cidr_netmask=24 nic=ens192 \ op monitor interval=30s --group zabbix-group [root@centos8-str3 ~]# pcs resource create VirtualIP2 ocf:heartbeat:IPaddr2 ip=192.168.111.40 cidr_netmask=24 nic=ens224 \ op monitor interval=30s --group zabbix-group [root@centos8-str3 ~]# pcs resource create httpd systemd:httpd --group zabbix-group [root@centos8-str3 ~]# pcs resource create php-fpm systemd:php-fpm --group zabbix-group [root@centos8-str3 ~]# pcs resource create zabbix-server systemd:zabbix-server --group zabbix-group ## DRBD_r0は優先的にcentos8-str3がMasterとして起動するように設定 [root@centos8-str3 ~]# pcs constraint location DRBD_r0-clone prefers centos8-str3=100 ## DRBD_r0がMaster側のノードでFS_DRBD0リソースを起動するように設定 [root@centos8-str3 ~]# pcs constraint order promote DRBD_r0-clone then start FS_DRBD0 ## FS_DRBD0はDRBD_r0のMasterと同じノードで起動(異常検知で必要) [root@centos8-str3 ~]# pcs constraint colocation add master DRBD_r0-clone with FS_DRBD0 INFINITY ## MariaDBはDRBD_r0のMasterと同じノードで起動(異常検知で必要) [root@centos8-str3 ~]# pcs constraint colocation add master DRBD_r0-clone with MariaDB INFINITY ## VirtualIPはDRBD_r0のMasterと同じノードで起動(異常検知で必要) [root@centos8-str3 ~]# pcs constraint colocation add master DRBD_r0-clone with VirtualIP INFINITY ## VirtualIP2はDRBD_r0のMasterと同じノードで起動(異常検知で必要) [root@centos8-str3 ~]# pcs constraint colocation add master DRBD_r0-clone with VirtualIP2 INFINITY ## httpdはDRBD_r0のMasterと同じノードで起動(異常検知で必要) [root@centos8-str3 ~]# pcs constraint colocation add master DRBD_r0-clone with httpd INFINITY ## php-fpmはDRBD_r0のMasterと同じノードで起動(異常検知で必要) [root@centos8-str3 ~]# pcs constraint colocation add master DRBD_r0-clone with php-fpm INFINITY ## zabbix-serverはDRBD_r0のMasterと同じノードで起動(異常検知で必要) [root@centos8-str3 ~]# pcs constraint colocation add master DRBD_r0-clone with zabbix-server INFINITY ## FS_DRBD0が起動してからzabbix-groupを起動するように設定 [root@centos8-str3 ~]# pcs constraint order FS_DRBD0 then start zabbix-group
クラスタ削除・追加による動作確認
centos8-str7、centos8-str8のクラスタ環境を利用してクラスタ削除・追加により、容易にクラスタに復帰できるか確認してみます。単純な作業であるクラスタからのノード削除、ノード追加で問題なくクラスタが動作することが確認できました。クラスタの停止 [root@centos8-str7 ~]# pcs cluster stop --all centos8-str8側でクラスタ設定の破棄 [root@centos8-str8 ~]# pcs cluster destroy Shutting down pacemaker/corosync services... Killing any remaining services... Removing all cluster configuration files... centos8-str7側でクラスタを起動(centos8-str8の設定が破棄されているため起動しない) [root@centos8-str7 ~]# pcs cluster start --all centos8-str8: Error connecting to centos8-str8 - (HTTP error: 400) centos8-str7: Starting Cluster... Error: unable to start all nodes centos8-str8をクラスタから削除 [root@centos8-str7 ~]# pcs cluster node remove centos8-str8 Destroying cluster on hosts: 'centos8-str8'... centos8-str8: Successfully destroyed cluster Sending updated corosync.conf to nodes... centos8-str7: Succeeded centos8-str7: Corosync configuration reloaded クラスタの状態を確認 centos8-str7単体で起動している [root@centos8-str7 ~]# pcs status Cluster name: bigbang Cluster Summary: * Stack: corosync * Current DC: centos8-str7 (version 2.0.5-9.el8_4.1-ba59be7122) - partition with quorum * Last updated: Sat Jan 29 20:44:21 2022 * Last change: Sat Jan 29 20:41:09 2022 by hacluster via crm_node on centos8-str7 * 1 node configured * 9 resource instances configured Node List: * Online: [ centos8-str7 ] Full List of Resources: * Clone Set: DRBD_r0-clone [DRBD_r0] (promotable): * Masters: [ centos8-str7 ] * FS_DRBD0 (ocf::heartbeat:Filesystem): Started centos8-str7 * Resource Group: zabbix-group: * MariaDB (systemd:mariadb): Started centos8-str7 * VirtualIP (ocf::heartbeat:IPaddr2): Started centos8-str7 * VirtualIP2 (ocf::heartbeat:IPaddr2): Started centos8-str7 * httpd (systemd:httpd): Started centos8-str7 * php-fpm (systemd:php-fpm): Started centos8-str7 * zabbix-server (systemd:zabbix-server): Started centos8-str7 Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled centos8-str8をクラスタに追加 [root@centos8-str7 ~]# pcs cluster node add centos8-str8 addr=10.0.0.49 addr=192.168.111.49 Disabling sbd... centos8-str8: sbd disabled Sending 'corosync authkey', 'pacemaker authkey' to 'centos8-str8' centos8-str8: successful distribution of the file 'corosync authkey' centos8-str8: successful distribution of the file 'pacemaker authkey' Sending updated corosync.conf to nodes... centos8-str8: Succeeded centos8-str7: Succeeded centos8-str7: Corosync configuration reloaded centos8-str8のクラスタを起動 [root@centos8-str7 ~]# pcs cluster start centos8-str8 centos8-str8: Starting Cluster... クラスタの状態を確認 centos8-str8が正常に動作しているように見える [root@centos8-str7 ~]# pcs status Cluster name: bigbang Cluster Summary: * Stack: corosync * Current DC: centos8-str7 (version 2.0.5-9.el8_4.1-ba59be7122) - partition with quorum * Last updated: Sat Jan 29 20:52:00 2022 * Last change: Sat Jan 29 20:51:27 2022 by hacluster via crmd on centos8-str7 * 2 nodes configured * 9 resource instances configured Node List: * Online: [ centos8-str7 centos8-str8 ] Full List of Resources: * Clone Set: DRBD_r0-clone [DRBD_r0] (promotable): * Masters: [ centos8-str7 ] * Slaves: [ centos8-str8 ] * FS_DRBD0 (ocf::heartbeat:Filesystem): Started centos8-str7 * Resource Group: zabbix-group: * MariaDB (systemd:mariadb): Started centos8-str7 * VirtualIP (ocf::heartbeat:IPaddr2): Started centos8-str7 * VirtualIP2 (ocf::heartbeat:IPaddr2): Started centos8-str7 * httpd (systemd:httpd): Started centos8-str7 * php-fpm (systemd:php-fpm): Started centos8-str7 * zabbix-server (systemd:zabbix-server): Started centos8-str7 Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled centos8-str7をスタンバイにして、centos8-str8にフェールオーバーするか確認します。 [root@centos8-str7 ~]# pcs node standby centos8-str7 正常にフェールオーバーし、centos8-str8でクラスタが動作しています。 [root@centos8-str8 ~]# pcs status Cluster name: bigbang Cluster Summary: * Stack: corosync * Current DC: centos8-str7 (version 2.0.5-9.el8_4.1-ba59be7122) - partition with quorum * Last updated: Sat Jan 29 20:54:57 2022 * Last change: Sat Jan 29 20:54:32 2022 by root via cibadmin on centos8-str7 * 2 nodes configured * 9 resource instances configured Node List: * Node centos8-str7: standby * Online: [ centos8-str8 ] Full List of Resources: * Clone Set: DRBD_r0-clone [DRBD_r0] (promotable): * Masters: [ centos8-str8 ] * Stopped: [ centos8-str7 ] * FS_DRBD0 (ocf::heartbeat:Filesystem): Started centos8-str8 * Resource Group: zabbix-group: * MariaDB (systemd:mariadb): Started centos8-str8 * VirtualIP (ocf::heartbeat:IPaddr2): Started centos8-str8 * VirtualIP2 (ocf::heartbeat:IPaddr2): Started centos8-str8 * httpd (systemd:httpd): Started centos8-str8 * php-fpm (systemd:php-fpm): Started centos8-str8 * zabbix-server (systemd:zabbix-server): Started centos8-str8 Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled centos8-str8をスタンバイにして、centos8-str7にフェールバックするか確認します。 [root@centos8-str7 ~]# pcs node unstandby centos8-str7 正常にフェールバックしています。 [root@centos8-str8 ~]# pcs status Cluster name: bigbang Cluster Summary: * Stack: corosync * Current DC: centos8-str7 (version 2.0.5-9.el8_4.1-ba59be7122) - partition with quorum * Last updated: Sat Jan 29 20:58:33 2022 * Last change: Sat Jan 29 20:58:00 2022 by root via cibadmin on centos8-str7 * 2 nodes configured * 9 resource instances configured Node List: * Node centos8-str8: standby * Online: [ centos8-str7 ] Full List of Resources: * Clone Set: DRBD_r0-clone [DRBD_r0] (promotable): * Masters: [ centos8-str7 ] * Stopped: [ centos8-str8 ] * FS_DRBD0 (ocf::heartbeat:Filesystem): Started centos8-str7 * Resource Group: zabbix-group: * MariaDB (systemd:mariadb): Started centos8-str7 * VirtualIP (ocf::heartbeat:IPaddr2): Started centos8-str7 * VirtualIP2 (ocf::heartbeat:IPaddr2): Started centos8-str7 * httpd (systemd:httpd): Started centos8-str7 * php-fpm (systemd:php-fpm): Started centos8-str7 * zabbix-server (systemd:zabbix-server): Started centos8-str7 Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled centos8-str8をアンスタンバイにし、クラスタに組み込みます。 [root@centos8-str7 ~]# pcs node unstandby centos8-str8 centos8-str8が再度、組み込まれました。 [root@centos8-str8 ~]# pcs status Cluster name: bigbang Cluster Summary: * Stack: corosync * Current DC: centos8-str7 (version 2.0.5-9.el8_4.1-ba59be7122) - partition with quorum * Last updated: Sat Jan 29 21:03:26 2022 * Last change: Sat Jan 29 21:02:31 2022 by root via cibadmin on centos8-str7 * 2 nodes configured * 9 resource instances configured Node List: * Online: [ centos8-str7 centos8-str8 ] Full List of Resources: * Clone Set: DRBD_r0-clone [DRBD_r0] (promotable): * Masters: [ centos8-str7 ] * Slaves: [ centos8-str8 ] * FS_DRBD0 (ocf::heartbeat:Filesystem): Started centos8-str7 * Resource Group: zabbix-group: * MariaDB (systemd:mariadb): Started centos8-str7 * VirtualIP (ocf::heartbeat:IPaddr2): Started centos8-str7 * VirtualIP2 (ocf::heartbeat:IPaddr2): Started centos8-str7 * httpd (systemd:httpd): Started centos8-str7 * php-fpm (systemd:php-fpm): Started centos8-str7 * zabbix-server (systemd:zabbix-server): Started centos8-str7 Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled
centos8-str3、centos8-str4の時に同様の作業を実施し、クラスタ構成に追加することができなかったのは、クラスタ追加前にcentos8-str4側でいろいろ作業をしてしまった影響のためなのかもしれません。
●pacemakerでZabbix-Server(MariaDBのMaster/Slave)+共有ディスク(DRBD)を制御する(CentOS Stream 8)
参考URL:Pacemaker/Corosync の設定値について
※この方法でPacemakerを構成した場合、シャットダウンする前に下記を実施してください。
1.スタンバイ側のクラスタ機能の停止
2.Zabbixサーバの停止
3.MariaDBの停止
4.シャットダウンの実施
または
1.Pacemakerの停止
2.シャットダウンの実施
カーネルアップデート後、下記の設定手順では正常にクラスタが動作しなくなってしまいました(2021.06.10現在)。
原因は不明ですが、DRBDとMariaDBをMaster/Slaveの構築後、リソースFS_DRBD0の設定を追加するとそこでクラスタ動作が止まってしまうような状態になりました。
そのためクラスタの設定方法または設定追加手順の再構成をすることにしました。
原因が判明しました。
kmod-drbd90-9.0.29-1.el8.elrepo.x86_64にはkernel-devel-4.18.0-305.3.1.el8.x86_64が必要ということでした。
「●カーネルアップデート後DRBDが起動しない」を参照してください。
CentOS Stream 8上で構築します。
下記についての作業は完了しているものとします。今回作成のDRBDの共有ディスク(ネットワークは192.168.111.0/24を使用してレプリケーションを実施)部分に、ApacheのDocumentRootを保存します。
- MariaDBのインストール及びMaster/Slaveの構築
「初期設定(CentOS 8)」参照
レプリケーションの設定の「バージョン10.3系」参照- Zabbix Serverのインストール及び設定
「pacemakerでZabbix-Server及びMariaDBのMaster/Slaveを制御する」参照
- DRBDによる共有ディスクの設定
「DRBDの構築について」参照
「DRBDをpacemakerの現在のリソースに追加する」参照
したがって、DRBDが起動できない場合、Apacheが起動せず異常終了します。
Apacheの異常終了はzabbix-groupの異常につながり、最終的にpacemakerが異常となります。
バーチャルIP異常試験は10.0.0.0/24側のNICを切断するようにします。
クラスタを2台構成で設定しますので、下記を設定します。[root@centos8-str3 ~]# pcs property set stonith-enabled=false [root@centos8-str3 ~]# pcs property set no-quorum-policy=ignoreDRBDは自動フェールバックを無効としておかないとDRDBでスプリットブレインが発生し、2台ともStandAlone状態となってしまう場合があります。
この対策のため、自動フェールバックを無効とします(Warningは無視します)。[root@centos8-str3 ~]# pcs resource defaults resource-stickiness=INFINITY Warning: This command is deprecated and will be removed. Please use 'pcs resource defaults update' instead. Warning: Defaults do not apply to resources which override them with their own defined valuesエラー発生時、即時にフェールオーバするようにします。(Warningは無視します)。[root@centos8-str3 ~]# pcs resource defaults migration-threshold=1 Warning: This command is deprecated and will be removed. Please use 'pcs resource defaults update' instead. Warning: Defaults do not apply to resources which override them with their own defined valuescentos8-str4をクラスタノード状態を強制的にStandby状態にしておきます。[root@centos8-str3 ~]# pcs node standby centos8-str4pacemakerのリソースを下記のような順序で起動するように(停止はその逆)設定します。
- DRBD
DRBDを設定しブロックデバイスをリアルタイムにレプリケート。Primary/Secondary。MariaDBのMaster側で稼働- MariaDB
各ホストに保存されたデータベースを読み込んでMariaDBを起動。Master/Slave。- Apache
httpdサービスを起動。Active/Standby。MariaDBのMaster側で稼働- php-fpm
php-fpmサービスを起動。MariaDBのMaster側で稼働- Zabbix-Server
zabbix-serverサービスを起動。Active/Standby。MariaDBのMaster側で稼働- VirtualIP
仮想IP(サービス側)の割り当て。MariaDBのMaster側で稼働- VirtualIP2
仮想IP(DRDB同期用)の割り当て。MariaDBのMaster側で稼働
最終的にDRBD/Apache/php-fpm/Zabbix Server/VirtualIP/VirtualIP2 のリソースをリソースグループ「zabbix-group」にまとめ、制御するようにします。
DRBDのリソースを作成します。
(DRBDのリソース定義は完了しているものとします。)[root@centos8-str3 ~]# pcs resource create DRBD_r0 ocf:linbit:drbd drbd_resource=r0 [root@centos8-str3 ~]# pcs resource promotable DRBD_r0 master-max=1 master-node-max=1 clone-max=2 clone-node-max=1 notify=true優先的にcentos8-str3がMasterとして起動するようにしておきます。[root@centos8-str3 ~]# pcs constraint location DRBD_r0-clone prefers centos8-str3=100 [root@centos8-str3 ~]# pcs resource cleanup DRBD_r0 [root@centos8-str3 ~]# pcs resource create FS_DRBD0 ocf:heartbeat:Filesystem device=/dev/drbd0 directory=/mnt fstype=xfs --group zabbix-groupMariaDBのリソースを作成します。
(MariaBDのインストール、レプリケーション設定は完了しているものとします。)[root@centos8-str3 ~]# pcs resource create MariaDB ocf:heartbeat:mysql binary=/usr/bin/mysqld_safe \ datadir=/var/lib/mysql log=/var/log/mariadb/mariadb.log pid=/run/mariadb/mariadb.pid replication_user=repl \ replication_passwd=[パスワード] op monitor interval=10s timeout=10s追加したMariaDBのリソースをMaster/Slaveで構成します。[root@centos8-str3 ~]# pcs resource promotable MariaDB master-max=1 master-node-max=1 clone-max=2 clone-node-max=1 notify=true優先的にcentos8-str3がMasterとして起動するようにしておきます。
[root@centos8-str3 ~]# pcs constraint location MariaDB-clone prefers centos8-str3=100Zabbix-Serverをリソースに追加します。[root@centos8-str3 ~]# pcs resource create zabbix-server systemd:zabbix-server op monitor interval="10s" timeout="20s"両ホストでApacheのstatus.confファイルを作成します。# vi /etc/httpd/conf.d/status.conf ExtendedStatus On <Location /server-status> SetHandler server-status Require local </Location>Apacheをリソースに追加します。[root@centos8-str3 ~]# pcs resource create Apache ocf:heartbeat:apache configfile=/etc/httpd/conf/httpd.conf \ statusurl="http://localhost/server-status" op monitor interval=10s timeout=10sphp-fpmをリソースに追加します。[root@centos8-str3 ~]# pcs resource create php-fpm systemd:php-fpm op monitor interval=10s timeout=10s仮想IPをリソースに追加します。[root@centos8-str3 ~]# pcs resource create VirtualIP ocf:heartbeat:IPaddr2 ip=10.0.0.40 \ cidr_netmask=24 nic=ens192 op monitor interval=10s timeout=10s [root@centos8-str3 ~]# pcs resource create VirtualIP2 ocf:heartbeat:IPaddr2 ip=192.168.0.40 \ cidr_netmask=24 nic=ens224 op monitor interval=10s timeout=10s設定をしやすようにリソースをグループ(zabbix-group)としてまとめます。
(FS_DRBD0は既にzabbix-groupに登録済)[root@centos8-str3 ~]# pcs resource group add zabbix-group Apache php-fpm zabbix-server VirtualIP VirtualIP2起動制約設定# MariaDBのcloneにはFS_DRBD0が [root@centos8-str3 ~]# pcs constraint colocation add FS_DRBD0 with MariaDB-clone INFINITY with-rsc-role=Master # MariaDB起動後にzabbix-groupリソースを起動 [root@centos8-str3 ~]# pcs constraint order promote MariaDB-clone then start zabbix-group Adding MariaDB-clone zabbix-group (kind: Mandatory) (Options: first-action=promote then-action=start) # zabbix-groupはMariaDBのMasterと同じノードで起動 [root@centos8-str3 ~]# pcs constraint colocation add zabbix-group with master MariaDB-clone INFINITY # zabbix-serverはMariaDBのMasterと同じノードで起動(異常検知で必要) [root@centos8-str3 ~]# pcs constraint colocation add master MariaDB-clone with zabbix-server INFINITY # ApacheはMariaDBのMasterと同じノードで起動(異常検知で必要) [root@centos8-str3 ~]# pcs constraint colocation add master MariaDB-clone with Apache INFINITY # php-fpmはMariaDBのMasterと同じノードで起動(異常検知で必要) [root@centos8-str3 ~]# pcs constraint colocation add master MariaDB-clone with php-fpm INFINITY # VirtualIPはMariaDBのMasterと同じノードで起動(異常検知で必要) [root@centos8-str3 ~]# pcs constraint colocation add master MariaDB-clone with VirtualIP INFINITY # VirtualIP2はMariaDBのMasterと同じノードで起動(異常検知で必要) [root@centos8-str3 ~]# pcs constraint colocation add master MariaDB-clone with VirtualIP2 INFINITY # zabbix-groupはDRBD_r0のMasterと同じノードで起動(異常検知で必要) [root@centos8-str3 ~]# pcs constraint colocation add master DRBD_r0-clone with zabbix-group INFINITYクラスタの状態を確認します。[root@centos8-str3 ~]# pcs node unstandby centos8-str4 [root@centos8-str3 ~]# pcs statusconfigを確認します。Cluster name: bigbang Cluster Summary: * Stack: corosync * Current DC: centos8-str3 (version 2.0.5-9.el8-ba59be7122) - partition with quorum * Last updated: Mon Apr 26 11:04:08 2021 * Last change: Thu Apr 22 16:45:44 2021 by root via cibadmin on centos8-str3 * 2 nodes configured * 10 resource instances configured Node List: * Online: [ centos8-str3 centos8-str4 ] Full List of Resources: * Clone Set: DRBD_r0-clone [DRBD_r0] (promotable): * Masters: [ centos8-str3 ] * Slaves: [ centos8-str4 ] * Resource Group: zabbix-group: * FS_DRBD0 (ocf::heartbeat:Filesystem): Started centos8-str3 * Apache (ocf::heartbeat:apache): Started centos8-str3 * php-fpm (systemd:php-fpm): Started centos8-str3 * zabbix-server (systemd:zabbix-server): Started centos8-str3 * VirtualIP (ocf::heartbeat:IPaddr2): Started centos8-str3 * VirtualIP2 (ocf::heartbeat:IPaddr2): Started centos8-str3 * Clone Set: MariaDB-clone [MariaDB] (promotable): * Masters: [ centos8-str3 ] * Slaves: [ centos8-str4 ] Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled[root@centos8-str3 ~]# pcs config showCluster Name: bigbang Corosync Nodes: centos8-str3 centos8-str4 Pacemaker Nodes: centos8-str3 centos8-str4 Resources: Clone: DRBD_r0-clone Meta Attrs: clone-max=2 clone-node-max=1 master-max=1 master-node-max=1 notify=true promotable=true Resource: DRBD_r0 (class=ocf provider=linbit type=drbd) Attributes: drbd_resource=r0 Operations: demote interval=0s timeout=90 (DRBD_r0-demote-interval-0s) monitor interval=20 role=Slave timeout=20 (DRBD_r0-monitor-interval-20) monitor interval=10 role=Master timeout=20 (DRBD_r0-monitor-interval-10) notify interval=0s timeout=90 (DRBD_r0-notify-interval-0s) promote interval=0s timeout=90 (DRBD_r0-promote-interval-0s) reload interval=0s timeout=30 (DRBD_r0-reload-interval-0s) start interval=0s timeout=240 (DRBD_r0-start-interval-0s) stop interval=0s timeout=100 (DRBD_r0-stop-interval-0s) Group: zabbix-group Resource: FS_DRBD0 (class=ocf provider=heartbeat type=Filesystem) Attributes: device=/dev/drbd0 directory=/mnt fstype=xfs Operations: monitor interval=20s timeout=40s (FS_DRBD0-monitor-interval-20s) start interval=0s timeout=60s (FS_DRBD0-start-interval-0s) stop interval=0s timeout=60s (FS_DRBD0-stop-interval-0s) Resource: Apache (class=ocf provider=heartbeat type=apache) Attributes: configfile=/etc/httpd/conf/httpd.conf statusurl=http://localhost/server-status Operations: monitor interval=10s timeout=10s (Apache-monitor-interval-10s) start interval=0s timeout=40s (Apache-start-interval-0s) stop interval=0s timeout=60s (Apache-stop-interval-0s) Resource: php-fpm (class=systemd type=php-fpm) Operations: monitor interval=10s timeout=10s (php-fpm-monitor-interval-10s) start interval=0s timeout=100 (php-fpm-start-interval-0s) stop interval=0s timeout=100 (php-fpm-stop-interval-0s) Resource: zabbix-server (class=systemd type=zabbix-server) Operations: monitor interval=10s timeout=20s (zabbix-server-monitor-interval-10s) start interval=0s timeout=100 (zabbix-server-start-interval-0s) stop interval=0s timeout=100 (zabbix-server-stop-interval-0s) Resource: VirtualIP (class=ocf provider=heartbeat type=IPaddr2) Attributes: cidr_netmask=24 ip=10.0.0.40 nic=ens192 Operations: monitor interval=10s timeout=10s (VirtualIP-monitor-interval-10s) start interval=0s timeout=20s (VirtualIP-start-interval-0s) stop interval=0s timeout=20s (VirtualIP-stop-interval-0s) Resource: VirtualIP2 (class=ocf provider=heartbeat type=IPaddr2) Attributes: cidr_netmask=24 ip=192.168.0.40 nic=ens224 Operations: monitor interval=10s timeout=10s (VirtualIP2-monitor-interval-10s) start interval=0s timeout=20s (VirtualIP2-start-interval-0s) stop interval=0s timeout=20s (VirtualIP2-stop-interval-0s) Clone: MariaDB-clone Meta Attrs: clone-max=2 clone-node-max=1 master-max=1 master-node-max=1 notify=true promotable=true Resource: MariaDB (class=ocf provider=heartbeat type=mysql) Attributes: binary=/usr/bin/mysqld_safe datadir=/var/lib/mysql log=/var/log/mariadb/mariadb.log \ pid=/run/mariadb/mariadb.pid replication_passwd=[パスワード] replication_user=repl Operations: demote interval=0s timeout=120s (MariaDB-demote-interval-0s) monitor interval=10s timeout=10s (MariaDB-monitor-interval-10s) notify interval=0s timeout=90s (MariaDB-notify-interval-0s) promote interval=0s timeout=120s (MariaDB-promote-interval-0s) start interval=0s timeout=120s (MariaDB-start-interval-0s) stop interval=0s timeout=120s (MariaDB-stop-interval-0s) Stonith Devices: Fencing Levels: Location Constraints: Resource: DRBD_r0-clone Enabled on: Node: centos8-str3 (score:100) (id:location-DRBD_r0-clone-centos8-str3-100) Resource: MariaDB-clone Enabled on: Node: centos8-str3 (score:100) (id:location-MariaDB-clone-centos8-str3-100) Ordering Constraints: promote MariaDB-clone then start zabbix-group (kind:Mandatory) (id:order-MariaDB-clone-zabbix-group-mandatory) Colocation Constraints: zabbix-group with MariaDB-clone (score:INFINITY) (rsc-role:Started) (with-rsc-role:Master) (id:colocation-zabbix-group-MariaDB-clone-INFINITY) MariaDB-clone with zabbix-server (score:INFINITY) (rsc-role:Master) (with-rsc-role:Started) (id:colocation-MariaDB-clone-zabbix-server-INFINITY) MariaDB-clone with Apache (score:INFINITY) (rsc-role:Master) (with-rsc-role:Started) (id:colocation-MariaDB-clone-Apache-INFINITY) MariaDB-clone with php-fpm (score:INFINITY) (rsc-role:Master) (with-rsc-role:Started) (id:colocation-MariaDB-clone-php-fpm-INFINITY) MariaDB-clone with VirtualIP (score:INFINITY) (rsc-role:Master) (with-rsc-role:Started) (id:colocation-MariaDB-clone-VirtualIP-INFINITY) MariaDB-clone with VirtualIP2 (score:INFINITY) (rsc-role:Master) (with-rsc-role:Started) (id:colocation-MariaDB-clone-VirtualIP2-INFINITY) DRBD_r0-clone with zabbix-group (score:INFINITY) (rsc-role:Master) (with-rsc-role:Started) (id:colocation-DRBD_r0-clone-zabbix-group-INFINITY) Ticket Constraints: Alerts: No alerts defined Resources Defaults: Meta Attrs: rsc_defaults-meta_attributes migration-threshold=1 resource-stickiness=INFINITY Operations Defaults: No defaults set Cluster Properties: MariaDB_REPL_INFO: centos8-str3.bigbang.mydns.jp|mysql-bin.000009|342 cluster-infrastructure: corosync cluster-name: bigbang dc-version: 2.0.5-9.el8-ba59be7122 have-watchdog: false last-lrm-refresh: 1619074041 no-quorum-policy: ignore stonith-enabled: false Tags: No tags defined Quorum: Options:
プロセスを停止した場合(Apache)(CentOS Stream 8)
1回でもfail-countがカウントされるとフェールオーバーするように設定していない場合、migration-thresholdのデフォルト値(migration-threshold=1000000)を変更してフェールオーバーするようにします。[root@centos8-str3 ~]# pcs resource defaults migration-threshold=1Apacheのサービスを停止し、リソースが他のホストに移動しているか確認します。[root@centos8-str3 ~]# kill -kill `pgrep -f httpd` [root@centos8-str3 ~]# ps axu | grep http[d] [root@centos8-str3 ~]# pcs status --full全てのリソースが他のホストに移動しています。Cluster name: bigbang Cluster Summary: * Stack: corosync * Current DC: centos8-str3 (1) (version 2.0.5-9.el8-ba59be7122) - partition with quorum * Last updated: Mon Apr 26 11:37:59 2021 * Last change: Mon Apr 26 11:37:37 2021 by root via crm_attribute on centos8-str4 * 2 nodes configured * 10 resource instances configured Node List: * Online: [ centos8-str3 (1) centos8-str4 (2) ] Full List of Resources: * Clone Set: DRBD_r0-clone [DRBD_r0] (promotable): * DRBD_r0 (ocf::linbit:drbd): Master centos8-str4 * DRBD_r0 (ocf::linbit:drbd): Slave centos8-str3 * Resource Group: zabbix-group: * FS_DRBD0 (ocf::heartbeat:Filesystem): Started centos8-str4 * Apache (ocf::heartbeat:apache): Started centos8-str4 * php-fpm (systemd:php-fpm): Started centos8-str4 * zabbix-server (systemd:zabbix-server): Started centos8-str4 * VirtualIP (ocf::heartbeat:IPaddr2): Started centos8-str4 * VirtualIP2 (ocf::heartbeat:IPaddr2): Started centos8-str4 * Clone Set: MariaDB-clone [MariaDB] (promotable): * MariaDB (ocf::heartbeat:mysql): Master centos8-str4 * MariaDB (ocf::heartbeat:mysql): Slave centos8-str3 Node Attributes: * Node: centos8-str3 (1): * master-DRBD_r0 : 10000 * master-MariaDB : 1 * readable : 1 * Node: centos8-str4 (2): * master-DRBD_r0 : 10000 * master-MariaDB : 3601 * readable : 1 Migration Summary: * Node: centos8-str3 (1): * Apache: migration-threshold=1 fail-count=1 last-failure='Mon Apr 26 11:37:30 2021' Failed Resource Actions: * Apache_monitor_10000 on centos8-str3 'not running' (7): call=377, status='complete', exitreason='', \ last-rc-change='2021-04-26 11:37:30 +09:00', queued=0ms, exec=0ms Tickets: PCSD Status: centos8-str3: Online centos8-str4: Online Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled
エラーをクリアし、再度Apacheのサービスを停止させリソースを元のホストに移動させます。[root@centos8-str4 ~]# pcs resource cleanup Apacheリソース及びMasterがcentos8-str3に戻っています。Cleaned up FS_DRBD0 on centos8-str4 Cleaned up FS_DRBD0 on centos8-str3 Cleaned up Apache on centos8-str4 Cleaned up Apache on centos8-str3 Cleaned up php-fpm on centos8-str4 Cleaned up php-fpm on centos8-str3 Cleaned up zabbix-server on centos8-str4 Cleaned up zabbix-server on centos8-str3 Cleaned up VirtualIP on centos8-str4 Cleaned up VirtualIP on centos8-str3 Cleaned up VirtualIP2 on centos8-str4 Cleaned up VirtualIP2 on centos8-str3 Waiting for 1 reply from the controller ... got reply (done)[root@centos8-str4 ~]# kill -kill `pgrep -f httpd` [root@centos8-str4 ~]# ps axu | grep http[d] [root@centos8-str4 ~]# pcs status --fullCluster name: bigbang Cluster Summary: * Stack: corosync * Current DC: centos8-str3 (1) (version 2.0.5-9.el8-ba59be7122) - partition with quorum * Last updated: Mon Apr 26 11:49:00 2021 * Last change: Mon Apr 26 11:48:48 2021 by root via crm_attribute on centos8-str3 * 2 nodes configured * 10 resource instances configured Node List: * Online: [ centos8-str3 (1) centos8-str4 (2) ] Full List of Resources: * Clone Set: DRBD_r0-clone [DRBD_r0] (promotable): * DRBD_r0 (ocf::linbit:drbd): Slave centos8-str4 * DRBD_r0 (ocf::linbit:drbd): Master centos8-str3 * Resource Group: zabbix-group: * FS_DRBD0 (ocf::heartbeat:Filesystem): Started centos8-str3 * Apache (ocf::heartbeat:apache): Started centos8-str3 * php-fpm (systemd:php-fpm): Started centos8-str3 * zabbix-server (systemd:zabbix-server): Started centos8-str3 * VirtualIP (ocf::heartbeat:IPaddr2): Started centos8-str3 * VirtualIP2 (ocf::heartbeat:IPaddr2): Started centos8-str3 * Clone Set: MariaDB-clone [MariaDB] (promotable): * MariaDB (ocf::heartbeat:mysql): Slave centos8-str4 * MariaDB (ocf::heartbeat:mysql): Master centos8-str3 Node Attributes: * Node: centos8-str3 (1): * master-DRBD_r0 : 10000 * master-MariaDB : 3601 * readable : 1 * Node: centos8-str4 (2): * master-DRBD_r0 : 10000 * master-MariaDB : 1 * readable : 1 Migration Summary: * Node: centos8-str4 (2): * Apache: migration-threshold=1 fail-count=1 last-failure='Mon Apr 26 11:48:41 2021' Failed Resource Actions: * Apache_monitor_10000 on centos8-str4 'not running' (7): call=375, status='complete', exitreason='', \ last-rc-change='2021-04-26 11:48:42 +09:00', queued=0ms, exec=0ms Tickets: PCSD Status: centos8-str3: Online centos8-str4: Online Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled
リソースのエラー表示をクリーンアップして終了です。[root@centos8-str4 ~]# pcs resource cleanup ApacheCleaned up FS_DRBD0 on centos8-str4 Cleaned up FS_DRBD0 on centos8-str3 Cleaned up Apache on centos8-str4 Cleaned up Apache on centos8-str3 Cleaned up php-fpm on centos8-str4 Cleaned up php-fpm on centos8-str3 Cleaned up zabbix-server on centos8-str4 Cleaned up zabbix-server on centos8-str3 Cleaned up VirtualIP on centos8-str4 Cleaned up VirtualIP on centos8-str3 Cleaned up VirtualIP2 on centos8-str4 Cleaned up VirtualIP2 on centos8-str3 Waiting for 1 reply from the controller ... got reply (done)
プロセスを停止した場合(php-fpm)
php-fpmのサービスを停止し、リソースが他のホストに移動しているか確認します。[root@centos8-str3 ~]# kill -kill `pgrep -f php-fpm` [root@centos8-str3 ~]# ps axu | grep -v grep | grep php-fpm [root@centos8-str3 ~]# pcs status --fullエラーをクリアし、再度php-fpmのサービスを停止させリソースを元のホストに移動させます。Cluster name: bigbang Cluster Summary: * Stack: corosync * Current DC: centos8-str4 (2) (version 2.0.5-9.el8-ba59be7122) - partition with quorum * Last updated: Tue Apr 27 08:25:01 2021 * Last change: Tue Apr 27 08:24:54 2021 by root via crm_attribute on centos8-str4 * 2 nodes configured * 10 resource instances configured Node List: * Online: [ centos8-str3 (1) centos8-str4 (2) ] Full List of Resources: * Clone Set: DRBD_r0-clone [DRBD_r0] (promotable): * DRBD_r0 (ocf::linbit:drbd): Master centos8-str4 * DRBD_r0 (ocf::linbit:drbd): Slave centos8-str3 * Resource Group: zabbix-group: * FS_DRBD0 (ocf::heartbeat:Filesystem): Started centos8-str4 * Apache (ocf::heartbeat:apache): Started centos8-str4 * php-fpm (systemd:php-fpm): Started centos8-str4 * zabbix-server (systemd:zabbix-server): Started centos8-str4 * VirtualIP (ocf::heartbeat:IPaddr2): Started centos8-str4 * VirtualIP2 (ocf::heartbeat:IPaddr2): Started centos8-str4 * Clone Set: MariaDB-clone [MariaDB] (promotable): * MariaDB (ocf::heartbeat:mysql): Master centos8-str4 * MariaDB (ocf::heartbeat:mysql): Slave centos8-str3 Node Attributes: * Node: centos8-str3 (1): * master-DRBD_r0 : 10000 * master-MariaDB : 1 * readable : 1 * Node: centos8-str4 (2): * master-DRBD_r0 : 10000 * master-MariaDB : 3601 * readable : 1 Migration Summary: * Node: centos8-str3 (1): * php-fpm: migration-threshold=1 fail-count=1 last-failure='Tue Apr 27 08:24:44 2021' Failed Resource Actions: * php-fpm_monitor_10000 on centos8-str3 'not running' (7): call=112, status='complete', exitreason='', \ last-rc-change='2021-04-27 08:24:45 +09:00', queued=0ms, exec=0ms Tickets: PCSD Status: centos8-str3: Online centos8-str4: Online Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled[root@centos8-str4 ~]# pcs resource cleanup php-fpmリソース及びMasterがcentos8-str3に戻っています。Cleaned up FS_DRBD0 on centos8-str4 Cleaned up FS_DRBD0 on centos8-str3 Cleaned up Apache on centos8-str4 Cleaned up Apache on centos8-str3 Cleaned up php-fpm on centos8-str4 Cleaned up php-fpm on centos8-str3 Cleaned up zabbix-server on centos8-str4 Cleaned up zabbix-server on centos8-str3 Cleaned up VirtualIP on centos8-str4 Cleaned up VirtualIP on centos8-str3 Cleaned up VirtualIP2 on centos8-str4 Cleaned up VirtualIP2 on centos8-str3 Waiting for 1 reply from the controller ... got reply (done)[root@centos8-str4 ~]# kill -kill `pgrep -f php-fpm` [root@centos8-str4 ~]# ps axu | grep -v grep | grep php-fpm [root@centos8-str4 ~]# pcs status --fullCluster name: bigbang Cluster Summary: * Stack: corosync * Current DC: centos8-str4 (2) (version 2.0.5-9.el8-ba59be7122) - partition with quorum * Last updated: Tue Apr 27 08:32:50 2021 * Last change: Tue Apr 27 08:32:36 2021 by root via crm_attribute on centos8-str3 * 2 nodes configured * 10 resource instances configured Node List: * Online: [ centos8-str3 (1) centos8-str4 (2) ] Full List of Resources: * Clone Set: DRBD_r0-clone [DRBD_r0] (promotable): * DRBD_r0 (ocf::linbit:drbd): Slave centos8-str4 * DRBD_r0 (ocf::linbit:drbd): Master centos8-str3 * Resource Group: zabbix-group: * FS_DRBD0 (ocf::heartbeat:Filesystem): Started centos8-str3 * Apache (ocf::heartbeat:apache): Started centos8-str3 * php-fpm (systemd:php-fpm): Started centos8-str3 * zabbix-server (systemd:zabbix-server): Started centos8-str3 * VirtualIP (ocf::heartbeat:IPaddr2): Started centos8-str3 * VirtualIP2 (ocf::heartbeat:IPaddr2): Started centos8-str3 * Clone Set: MariaDB-clone [MariaDB] (promotable): * MariaDB (ocf::heartbeat:mysql): Slave centos8-str4 * MariaDB (ocf::heartbeat:mysql): Master centos8-str3 Node Attributes: * Node: centos8-str3 (1): * master-DRBD_r0 : 10000 * master-MariaDB : 3601 * readable : 1 * Node: centos8-str4 (2): * master-DRBD_r0 : 10000 * master-MariaDB : 1 * readable : 1 Migration Summary: * Node: centos8-str4 (2): * php-fpm: migration-threshold=1 fail-count=1 last-failure='Tue Apr 27 08:32:27 2021' Failed Resource Actions: * php-fpm_monitor_10000 on centos8-str4 'not running' (7): call=129, status='complete', exitreason='', \ last-rc-change='2021-04-27 08:32:27 +09:00', queued=0ms, exec=0ms Tickets: PCSD Status: centos8-str3: Online centos8-str4: Online Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled
リソースのエラー表示をクリーンアップして終了です。[root@centos8-str4 ~]# pcs resource cleanup php-fpmCleaned up FS_DRBD0 on centos8-str4 Cleaned up FS_DRBD0 on centos8-str3 Cleaned up Apache on centos8-str4 Cleaned up Apache on centos8-str3 Cleaned up php-fpm on centos8-str4 Cleaned up php-fpm on centos8-str3 Cleaned up zabbix-server on centos8-str4 Cleaned up zabbix-server on centos8-str3 Cleaned up VirtualIP on centos8-str4 Cleaned up VirtualIP on centos8-str3 Cleaned up VirtualIP2 on centos8-str4 Cleaned up VirtualIP2 on centos8-str3 Waiting for 1 reply from the controller ... got reply (done)
プロセスを停止した場合(Zabbix Server)(CentOS Stream 8)
Zabbix Serverのサービスを停止し、リソースが他のホストに移動しているか確認します。[root@centos8-str3 ~]# kill -kill `pgrep -f zabbix_server` [root@centos8-str3 ~]# ps axu | grep -v grep | grep zabbix_server [root@centos8-str3 ~]# pcs status --fullエラーをクリアし、再度Zabbix Serverのサービスを停止させリソースを元のホストに移動させます。Cluster name: bigbang Cluster Summary: * Stack: corosync * Current DC: centos8-str3 (1) (version 2.0.5-9.el8-ba59be7122) - partition with quorum * Last updated: Mon Apr 26 15:50:07 2021 * Last change: Mon Apr 26 15:49:55 2021 by root via crm_attribute on centos8-str4 * 2 nodes configured * 10 resource instances configured Node List: * Online: [ centos8-str3 (1) centos8-str4 (2) ] Full List of Resources: * Clone Set: DRBD_r0-clone [DRBD_r0] (promotable): * DRBD_r0 (ocf::linbit:drbd): Master centos8-str4 * DRBD_r0 (ocf::linbit:drbd): Slave centos8-str3 * Resource Group: zabbix-group: * FS_DRBD0 (ocf::heartbeat:Filesystem): Started centos8-str4 * Apache (ocf::heartbeat:apache): Started centos8-str4 * php-fpm (systemd:php-fpm): Started centos8-str4 * zabbix-server (systemd:zabbix-server): Started centos8-str4 * VirtualIP (ocf::heartbeat:IPaddr2): Started centos8-str4 * VirtualIP2 (ocf::heartbeat:IPaddr2): Started centos8-str4 * Clone Set: MariaDB-clone [MariaDB] (promotable): * MariaDB (ocf::heartbeat:mysql): Master centos8-str4 * MariaDB (ocf::heartbeat:mysql): Slave centos8-str3 Node Attributes: * Node: centos8-str3 (1): * master-DRBD_r0 : 10000 * master-MariaDB : 1 * readable : 1 * Node: centos8-str4 (2): * master-DRBD_r0 : 10000 * master-MariaDB : 3601 * readable : 1 Migration Summary: * Node: centos8-str3 (1): * zabbix-server: migration-threshold=1 fail-count=1 last-failure='Mon Apr 26 15:49:46 2021' Failed Resource Actions: * zabbix-server_monitor_10000 on centos8-str3 'not running' (7): call=440, status='complete', exitreason='', \ last-rc-change='2021-04-26 15:49:46 +09:00', queued=0ms, exec=0ms Tickets: PCSD Status: centos8-str3: Online centos8-str4: Online Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled[ root@centos8-str4 ~]# pcs resource cleanup zabbix-serverリソース及びMasterがcentos8-str3に戻っています。Cleaned up FS_DRBD0 on centos8-str4 Cleaned up FS_DRBD0 on centos8-str3 Cleaned up Apache on centos8-str4 Cleaned up Apache on centos8-str3 Cleaned up php-fpm on centos8-str4 Cleaned up php-fpm on centos8-str3 Cleaned up zabbix-server on centos8-str4 Cleaned up zabbix-server on centos8-str3 Cleaned up VirtualIP on centos8-str4 Cleaned up VirtualIP on centos8-str3 Cleaned up VirtualIP2 on centos8-str4 Cleaned up VirtualIP2 on centos8-str3 Waiting for 1 reply from the controller ... got reply (done)[root@centos8-str4 ~]# kill -kill `pgrep -f zabbix_server` [root@centos8-str4 ~]# ps axu | grep -v grep | grep zabbix_server [root@centos8-str4 ~]# pcs status --fullCluster name: bigbang Cluster Summary: * Stack: corosync * Current DC: centos8-str3 (1) (version 2.0.5-9.el8-ba59be7122) - partition with quorum * Last updated: Mon Apr 26 15:59:14 2021 * Last change: Mon Apr 26 15:58:50 2021 by root via crm_attribute on centos8-str3 * 2 nodes configured * 10 resource instances configured Node List: * Online: [ centos8-str3 (1) centos8-str4 (2) ] Full List of Resources: * Clone Set: DRBD_r0-clone [DRBD_r0] (promotable): * DRBD_r0 (ocf::linbit:drbd): Slave centos8-str4 * DRBD_r0 (ocf::linbit:drbd): Master centos8-str3 * Resource Group: zabbix-group: * FS_DRBD0 (ocf::heartbeat:Filesystem): Started centos8-str3 * Apache (ocf::heartbeat:apache): Started centos8-str3 * php-fpm (systemd:php-fpm): Started centos8-str3 * zabbix-server (systemd:zabbix-server): Started centos8-str3 * VirtualIP (ocf::heartbeat:IPaddr2): Started centos8-str3 * VirtualIP2 (ocf::heartbeat:IPaddr2): Started centos8-str3 * Clone Set: MariaDB-clone [MariaDB] (promotable): * MariaDB (ocf::heartbeat:mysql): Slave centos8-str4 * MariaDB (ocf::heartbeat:mysql): Master centos8-str3 Node Attributes: * Node: centos8-str3 (1): * master-DRBD_r0 : 10000 * master-MariaDB : 3601 * readable : 1 * Node: centos8-str4 (2): * master-DRBD_r0 : 10000 * master-MariaDB : 1 * readable : 1 Migration Summary: * Node: centos8-str4 (2): * zabbix-server: migration-threshold=1 fail-count=1 last-failure='Mon Apr 26 15:58:41 2021' Failed Resource Actions: * zabbix-server_monitor_10000 on centos8-str4 'not running' (7): call=434, status='complete', exitreason='', \ last-rc-change='2021-04-26 15:58:41 +09:00', queued=0ms, exec=0ms Tickets: PCSD Status: centos8-str3: Online centos8-str4: Online Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled
リソースのエラー表示をクリーンアップして終了です。[root@centos8-str4 ~]# pcs resource cleanup zabbix-serverCleaned up FS_DRBD0 on centos8-str4 Cleaned up FS_DRBD0 on centos8-str3 Cleaned up Apache on centos8-str4 Cleaned up Apache on centos8-str3 Cleaned up php-fpm on centos8-str4 Cleaned up php-fpm on centos8-str3 Cleaned up zabbix-server on centos8-str4 Cleaned up zabbix-server on centos8-str3 Cleaned up VirtualIP on centos8-str4 Cleaned up VirtualIP on centos8-str3 Cleaned up VirtualIP2 on centos8-str4 Cleaned up VirtualIP2 on centos8-str3 Waiting for 1 reply from the controller ... got reply (done)
NIC障害(VirtualIP)(CentOS Stream 8)
今回作成のDRBDの共有ディスク(ネットワークは192.168.0.0/24を使用してレプリケーションを実施)部分に、ApacheのDocumentRootを保存します。
したがって、DRBDが起動できない場合、Apacheが起動せず異常終了します。
Apacheの異常終了はzabbix-groupの異常につながり、最終的にpacemakerが異常となります。
バーチャルIP異常試験は10.0.0.0/24側のNICを切断するようにします。
[root@centos8-str3 ~]# pcs resource update VirtualIP op monitor on-fail=standby [root@centos8-str3 ~]# pcs resource update VirtualIP2 op monitor on-fail=standby [root@centos8-str3 ~]# pcs resource config該当仮想ホスト(centos8-str3)のNICを削除してしまうためログインできなくなりますので、状態確認は他方のホスト(centos8-str4)で実施します。Clone: DRBD_r0-clone Meta Attrs: clone-max=2 clone-node-max=1 master-max=1 master-node-max=1 notify=true promotable=true Resource: DRBD_r0 (class=ocf provider=linbit type=drbd) Attributes: drbd_resource=r0 Operations: demote interval=0s timeout=90 (DRBD_r0-demote-interval-0s) monitor interval=20 role=Slave timeout=20 (DRBD_r0-monitor-interval-20) monitor interval=10 role=Master timeout=20 (DRBD_r0-monitor-interval-10) notify interval=0s timeout=90 (DRBD_r0-notify-interval-0s) promote interval=0s timeout=90 (DRBD_r0-promote-interval-0s) reload interval=0s timeout=30 (DRBD_r0-reload-interval-0s) start interval=0s timeout=240 (DRBD_r0-start-interval-0s) stop interval=0s timeout=100 (DRBD_r0-stop-interval-0s) Group: zabbix-group Resource: FS_DRBD0 (class=ocf provider=heartbeat type=Filesystem) Attributes: device=/dev/drbd0 directory=/mnt fstype=xfs Operations: monitor interval=20s timeout=40s (FS_DRBD0-monitor-interval-20s) start interval=0s timeout=60s (FS_DRBD0-start-interval-0s) stop interval=0s timeout=60s (FS_DRBD0-stop-interval-0s) Resource: Apache (class=ocf provider=heartbeat type=apache) Attributes: configfile=/etc/httpd/conf/httpd.conf statusurl=http://localhost/server-status Operations: monitor interval=10s timeout=10s (Apache-monitor-interval-10s) start interval=0s timeout=40s (Apache-start-interval-0s) stop interval=0s timeout=60s (Apache-stop-interval-0s) Resource: php-fpm (class=systemd type=php-fpm) Operations: monitor interval=10s timeout=10s (php-fpm-monitor-interval-10s) start interval=0s timeout=100 (php-fpm-start-interval-0s) stop interval=0s timeout=100 (php-fpm-stop-interval-0s) Resource: zabbix-server (class=systemd type=zabbix-server) Operations: monitor interval=10s timeout=20s (zabbix-server-monitor-interval-10s) start interval=0s timeout=100 (zabbix-server-start-interval-0s) stop interval=0s timeout=100 (zabbix-server-stop-interval-0s) Resource: VirtualIP (class=ocf provider=heartbeat type=IPaddr2) Attributes: cidr_netmask=24 ip=10.0.0.40 nic=ens192 Operations: monitor interval=60s on-fail=standby (VirtualIP-monitor-interval-60s) start interval=0s timeout=20s (VirtualIP-start-interval-0s) stop interval=0s timeout=20s (VirtualIP-stop-interval-0s) Resource: VirtualIP2 (class=ocf provider=heartbeat type=IPaddr2) Attributes: cidr_netmask=24 ip=192.168.0.40 nic=ens224 Operations: monitor interval=60s on-fail=standby (VirtualIP2-monitor-interval-60s) start interval=0s timeout=20s (VirtualIP2-start-interval-0s) stop interval=0s timeout=20s (VirtualIP2-stop-interval-0s) Clone: MariaDB-clone Meta Attrs: clone-max=2 clone-node-max=1 master-max=1 master-node-max=1 notify=true promotable=true Resource: MariaDB (class=ocf provider=heartbeat type=mysql) Attributes: binary=/usr/bin/mysqld_safe datadir=/var/lib/mysql log=/var/log/mariadb/mariadb.log \ pid=/run/mariadb/mariadb.pid replication_passwd=[パスワード] replication_user=repl Operations: demote interval=0s timeout=120s (MariaDB-demote-interval-0s) monitor interval=10s timeout=10s (MariaDB-monitor-interval-10s) notify interval=0s timeout=90s (MariaDB-notify-interval-0s) promote interval=0s timeout=120s (MariaDB-promote-interval-0s) start interval=0s timeout=120s (MariaDB-start-interval-0s) stop interval=0s timeout=120s (MariaDB-stop-interval-0s)[root@centos8-str4 ~]# pcs status --full該当仮想ホスト(centos8-str3)のNICを元の状態に戻し、エラーをクリアします。Cluster name: bigbang Cluster Summary: * Stack: corosync * Current DC: centos8-str3 (1) (version 2.0.5-9.el8-ba59be7122) - partition with quorum * Last updated: Mon Apr 26 16:34:57 2021 * Last change: Mon Apr 26 16:34:36 2021 by root via crm_attribute on centos8-str4 * 2 nodes configured * 10 resource instances configured Node List: * Node centos8-str3 (1): standby (on-fail) * Online: [ centos8-str4 (2) ] Full List of Resources: * Clone Set: DRBD_r0-clone [DRBD_r0] (promotable): * DRBD_r0 (ocf::linbit:drbd): Master centos8-str4 * DRBD_r0 (ocf::linbit:drbd): Stopped * Resource Group: zabbix-group: * FS_DRBD0 (ocf::heartbeat:Filesystem): Started centos8-str4 * Apache (ocf::heartbeat:apache): Started centos8-str4 * php-fpm (systemd:php-fpm): Started centos8-str4 * zabbix-server (systemd:zabbix-server): Started centos8-str4 * VirtualIP (ocf::heartbeat:IPaddr2): Started centos8-str4 * VirtualIP2 (ocf::heartbeat:IPaddr2): Started centos8-str4 * Clone Set: MariaDB-clone [MariaDB] (promotable): * MariaDB (ocf::heartbeat:mysql): Master centos8-str4 * MariaDB (ocf::heartbeat:mysql): Stopped Node Attributes: * Node: centos8-str3 (1): * readable : 0 * Node: centos8-str4 (2): * master-DRBD_r0 : 10000 * master-MariaDB : 3601 * readable : 1 Migration Summary: * Node: centos8-str3 (1): * VirtualIP: migration-threshold=1 fail-count=1 last-failure='Mon Apr 26 16:34:24 2021' Failed Resource Actions: * VirtualIP_monitor_60000 on centos8-str3 'not running' (7): call=500, status='complete', exitreason='', \ last-rc-change='2021-04-26 16:34:24 +09:00', queued=0ms, exec=0ms Tickets: PCSD Status: centos8-str3: Offline centos8-str4: Online Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled[root@centos8-str4 ~]# pcs resource cleanup VirtualIP今度はcetnso8-str4側のNICを故意に障害にします。Cleaned up FS_DRBD0 on centos8-str4 Cleaned up FS_DRBD0 on centos8-str3 Cleaned up Apache on centos8-str4 Cleaned up Apache on centos8-str3 Cleaned up php-fpm on centos8-str4 Cleaned up php-fpm on centos8-str3 Cleaned up zabbix-server on centos8-str4 Cleaned up zabbix-server on centos8-str3 Cleaned up VirtualIP on centos8-str4 Cleaned up VirtualIP on centos8-str3 Cleaned up VirtualIP2 on centos8-str4 Cleaned up VirtualIP2 on centos8-str3 Waiting for 1 reply from the controller ... got reply (done)[root@centos8-str4 ~]# pcs status --fullCluster name: bigbang Cluster Summary: * Stack: corosync * Current DC: centos8-str3 (1) (version 2.0.5-9.el8-ba59be7122) - partition with quorum * Last updated: Mon Apr 26 16:44:15 2021 * Last change: Mon Apr 26 16:43:06 2021 by hacluster via crmd on centos8-str3 * 2 nodes configured * 10 resource instances configured Node List: * Online: [ centos8-str3 (1) centos8-str4 (2) ] Full List of Resources: * Clone Set: DRBD_r0-clone [DRBD_r0] (promotable): * DRBD_r0 (ocf::linbit:drbd): Master centos8-str4 * DRBD_r0 (ocf::linbit:drbd): Slave centos8-str3 * Resource Group: zabbix-group: * FS_DRBD0 (ocf::heartbeat:Filesystem): Started centos8-str4 * Apache (ocf::heartbeat:apache): Started centos8-str4 * php-fpm (systemd:php-fpm): Started centos8-str4 * zabbix-server (systemd:zabbix-server): Started centos8-str4 * VirtualIP (ocf::heartbeat:IPaddr2): Started centos8-str4 * VirtualIP2 (ocf::heartbeat:IPaddr2): Started centos8-str4 * Clone Set: MariaDB-clone [MariaDB] (promotable): * MariaDB (ocf::heartbeat:mysql): Master centos8-str4 * MariaDB (ocf::heartbeat:mysql): Slave centos8-str3 Node Attributes: * Node: centos8-str3 (1): * master-DRBD_r0 : 10000 * master-MariaDB : 1 * readable : 0 * Node: centos8-str4 (2): * master-DRBD_r0 : 10000 * master-MariaDB : 3601 * readable : 1 Migration Summary: Tickets: PCSD Status: centos8-str3: Online centos8-str4: Online Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled[root@centos8-str3 ~]# pcs status --fullcentos8-str4のNICを元の状態に戻し、エラーをクリアします。Cluster name: bigbang Cluster Summary: * Stack: corosync * Current DC: centos8-str4 (2) (version 2.0.5-9.el8-ba59be7122) - partition with quorum * Last updated: Mon Apr 26 17:51:47 2021 * Last change: Mon Apr 26 17:49:22 2021 by root via crm_attribute on centos8-str3 * 2 nodes configured * 10 resource instances configured Node List: * Node centos8-str4 (2): standby (on-fail) * Online: [ centos8-str3 (1) ] Full List of Resources: * Clone Set: DRBD_r0-clone [DRBD_r0] (promotable): * DRBD_r0 (ocf::linbit:drbd): Master centos8-str3 * DRBD_r0 (ocf::linbit:drbd): Stopped * Resource Group: zabbix-group: * FS_DRBD0 (ocf::heartbeat:Filesystem): Started centos8-str3 * Apache (ocf::heartbeat:apache): Started centos8-str3 * php-fpm (systemd:php-fpm): Started centos8-str3 * zabbix-server (systemd:zabbix-server): Started centos8-str3 * VirtualIP (ocf::heartbeat:IPaddr2): Started centos8-str3 * VirtualIP2 (ocf::heartbeat:IPaddr2): Started centos8-str3 * Clone Set: MariaDB-clone [MariaDB] (promotable): * MariaDB (ocf::heartbeat:mysql): Master centos8-str3 * MariaDB (ocf::heartbeat:mysql): Stopped Node Attributes: * Node: centos8-str3 (1): * master-DRBD_r0 : 10000 * master-MariaDB : 3601 * readable : 1 * Node: centos8-str4 (2): * readable : 0 Migration Summary: * Node: centos8-str4 (2): * VirtualIP: migration-threshold=1 fail-count=1 last-failure='Mon Apr 26 17:49:11 2021' Failed Resource Actions: * VirtualIP_monitor_60000 on centos8-str4 'not running' (7): call=70, status='complete', exitreason='', \ last-rc-change='2021-04-26 17:49:11 +09:00', queued=0ms, exec=0ms Tickets: PCSD Status: centos8-str3: Online centos8-str4: Offline Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled
[root@centos8-str3 ~]# pcs resource cleanup VirtualIP元の状態に戻っています。Cleaned up FS_DRBD0 on centos8-str4 Cleaned up FS_DRBD0 on centos8-str3 Cleaned up Apache on centos8-str4 Cleaned up Apache on centos8-str3 Cleaned up php-fpm on centos8-str4 Cleaned up php-fpm on centos8-str3 Cleaned up zabbix-server on centos8-str4 Cleaned up zabbix-server on centos8-str3 Cleaned up VirtualIP on centos8-str4 Cleaned up VirtualIP on centos8-str3 Cleaned up VirtualIP2 on centos8-str4 Cleaned up VirtualIP2 on centos8-str3 Waiting for 1 reply from the controller ... got reply (done)[root@centos8-str3 ~]# pcs status --fullCluster name: bigbang Cluster Summary: * Stack: corosync * Current DC: centos8-str4 (2) (version 2.0.5-9.el8-ba59be7122) - partition with quorum * Last updated: Mon Apr 26 17:55:55 2021 * Last change: Mon Apr 26 17:55:17 2021 by hacluster via crmd on centos8-str4 * 2 nodes configured * 10 resource instances configured Node List: * Online: [ centos8-str3 (1) centos8-str4 (2) ] Full List of Resources: * Clone Set: DRBD_r0-clone [DRBD_r0] (promotable): * DRBD_r0 (ocf::linbit:drbd): Slave centos8-str4 * DRBD_r0 (ocf::linbit:drbd): Master centos8-str3 * Resource Group: zabbix-group: * FS_DRBD0 (ocf::heartbeat:Filesystem): Started centos8-str3 * Apache (ocf::heartbeat:apache): Started centos8-str3 * php-fpm (systemd:php-fpm): Started centos8-str3 * zabbix-server (systemd:zabbix-server): Started centos8-str3 * VirtualIP (ocf::heartbeat:IPaddr2): Started centos8-str3 * VirtualIP2 (ocf::heartbeat:IPaddr2): Started centos8-str3 * Clone Set: MariaDB-clone [MariaDB] (promotable): * MariaDB (ocf::heartbeat:mysql): Slave centos8-str4 * MariaDB (ocf::heartbeat:mysql): Master centos8-str3 Node Attributes: * Node: centos8-str3 (1): * master-DRBD_r0 : 10000 * master-MariaDB : 3601 * readable : 1 * Node: centos8-str4 (2): * master-DRBD_r0 : 10000 * master-MariaDB : 1 * readable : 0 Migration Summary: Tickets: PCSD Status: centos8-str3: Online centos8-str4: Online Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled
●Pacemaker及びCorosyncのインストール・初期設定(CentOS 7向け)
Pacemaker及びCorosyncをインストールします。※両ノードで実施 # yum install pacemaker # yum install pcs # yum install fence-agents-alクラスタ用ユーザを設定する。yumでインストールすると、「hacluster」ユーザが作成されているはずなので確認します。※両ノードで実施 [root@centos7-1 ~]# cat /etc/passwd | grep hacluster hacluster:x:189:189:cluster user:/home/hacluster:/sbin/nologin [root@centos7-2 ~]# cat /etc/passwd | grep hacluster hacluster:x:189:189:cluster user:/home/hacluster:/sbin/nologinパスワードを設定します。両ノードで同一のパスワードです。※両ノードで実施 # passwd hacluster ユーザ hacluster のパスワードを変更。 新しいパスワード: 新しいパスワードを再入力してください: passwd: すべての認証トークンが正しく更新できました。Pacemakerのサービスを起動させます。※両ノードで実施 # systemctl start pcsd.service # systemctl enable pcsd.service起動後の状態を確認し、エラーが発生しておらず、acitive / enabledとなっていればOK。※両ノードで実施 # systemctl status pcsd.service ● pcsd.service - PCS GUI and remote configuration interface Loaded: loaded (/usr/lib/systemd/system/pcsd.service; enabled; vendor preset: disabled) Active: active (running) since 火 2019-07-02 14:56:38 JST; 35s ago Docs: man:pcsd(8) man:pcs(8) Main PID: 11533 (pcsd) CGroup: /system.slice/pcsd.service └─11533 /usr/bin/ruby /usr/lib/pcsd/pcsd 7月 02 14:56:36 centos7-1.bigbang.mydns.jp systemd[1]: Starting PCS GUI and remote configur..... 7月 02 14:56:38 centos7-1.bigbang.mydns.jp systemd[1]: Started PCS GUI and remote configura...e. Hint: Some lines were ellipsized, use -l to show in full.クラスタを組む際にインターコネクトでも名前解決できるように、/etc/hostsにお互いのIPアドレスを登録します。※両ノードで実施 # vi /etc/hosts ------------------------------ 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.0.11 centos7-1c centos7-1c.bigbang.mydns.jp ← 追加 192.168.0.12 centos7-2c centos7-2c.bigbang.mydns.jp ← 追加 192.168.10.11 centos7-1 centos7-1.bigbang.mydns.jp ← 追加 192.168.10.12 centos7-2 centos7-2.bigbang.mydns.jp ← 追加192.168.0と192.168.10の2つのネットワークのホスト名を登録するのは、スプリットブレインが発生するのを防止するためです(設定は後述)。
クラスタで使用するポートを利用できるよう、firewallに穴を開けます。※両ノードで実施 # firewall-cmd --add-service=high-availability --permanent success # firewall-cmd --reload success # firewall-cmd --list-service ssh dhcpv6-client https http high-availabilityクラスタに参加するノードの認証を行う。※片方のノードで実施 ※この場合、pcs cluster setup --start・・・で、認証を実施していないノードが含まれていると失敗します。 [root@centos7-1 ~]# pcs cluster auth centos7-1c centos7-2c Username: hacluster Password: centos7-1c: Authorized centos7-2c: Authorized
Pacemaker・Corosyncのクラスタを作成(CentOS 7向け)
スプリットブレイン発生を防止する観点から、クラスタ間のハートビートをやり取りするネットワークは2本以上の冗長構成とすることが望ましい。
クラスタ作成の際に、ホスト名をIPアドレスごとにカンマ区切りで指定することで、複数のIPアドレスでクラスタに登録がされます。※片方のノードで実施 ※今回はスプリットブレインのことは考えず、centos7-1c及びcentos7-2cで設定します。 [root@centos7-1 ~]# pcs cluster setup --start --name bigbang-cluster1 centos7-1,centos7-1c centos7-2,centos7-2c Error: centos7-1: unable to authenticate to node Error: centos7-2: unable to authenticate to node Error: nodes availability check failed, use --force to override. WARNING: This will destroy existing cluster on the nodes. pcs cluster auth実行時、centos7-1及びcentos7-2を含めていなかったのが原因です。 [root@centos7-1 ~]# pcs cluster setup --start --name bigbang-cluster1 centos7-1c centos7-2cDestroying cluster on nodes: centos7-1c, centos7-2c... centos7-1c: Stopping Cluster (pacemaker)... centos7-2c: Stopping Cluster (pacemaker)... centos7-1c: Successfully destroyed cluster centos7-2c: Successfully destroyed cluster Sending 'pacemaker_remote authkey' to 'centos7-1c', 'centos7-2c' centos7-1c: successful distribution of the file 'pacemaker_remote authkey' centos7-2c: successful distribution of the file 'pacemaker_remote authkey' Sending cluster config files to the nodes... centos7-1c: Succeeded centos7-2c: Succeeded Starting cluster on nodes: centos7-1c, centos7-2c... centos7-1c: Starting Cluster (corosync)... centos7-2c: Starting Cluster (corosync)... centos7-2c: Starting Cluster (pacemaker)... centos7-1c: Starting Cluster (pacemaker)... Synchronizing pcsd certificates on nodes centos7-1c, centos7-2c... centos7-1c: Success centos7-2c: Success Restarting pcsd on the nodes in order to reload the certificates... centos7-1c: Success centos7-2c: Success設定確認は以下コマンドで実施します。RING ID 0で1つのIPアドレスが設定されていることがわかります。 # corosync-cfgtool -s Printing ring status. Local node ID 1 RING ID 0 id = 192.168.0.11 status = ring 0 active with no faults ※今回はスプリットブレイン防止を考慮する方法では、pcs cluster authコマンドで先にcentos7-1,centos7-1c centos7-2,centos7-2cの 設定をしておく必要があります。設定していない場合、下記のようにエラーとなります。 # pcs cluster setup --start --name bigbang-cluster1 centos7-1,centos7-1c centos7-2,centos7-2c Error: centos7-1: unable to authenticate to node Error: centos7-2: unable to authenticate to node Error: nodes availability check failed, use --force to override. WARNING: This will destroy existing cluster on the nodes. 4台のノードを設定する場合は、下記のとおりとなります。 ※片方のノードで実施 [root@centos7-1 ~]# pcs cluster auth centos7-1c centos7-2c centos7-1 centos7-2 Username: hacluster Password: centos7-1: Authorized centos7-1c: Authorized centos7-2: Authorized centos7-2c: Authorized ※片方のノードで実施 [root@centos7-1 ~]# pcs cluster setup --start --name bigbang-cluster1 centos7-1,centos7-1c centos7-2,centos7-2c --forceDestroying cluster on nodes: centos7-1, centos7-2... centos7-1: Stopping Cluster (pacemaker)... centos7-2: Stopping Cluster (pacemaker)... centos7-1: Successfully destroyed cluster centos7-2: Successfully destroyed cluster Sending 'pacemaker_remote authkey' to 'centos7-1', 'centos7-2' centos7-1: successful distribution of the file 'pacemaker_remote authkey' centos7-2: successful distribution of the file 'pacemaker_remote authkey' Sending cluster config files to the nodes... centos7-1: Succeeded centos7-2: Succeeded Starting cluster on nodes: centos7-1, centos7-2... centos7-1: Starting Cluster (corosync)... centos7-2: Starting Cluster (corosync)... centos7-2: Starting Cluster (pacemaker)... centos7-1: Starting Cluster (pacemaker)... Synchronizing pcsd certificates on nodes centos7-1, centos7-2... centos7-1: Success centos7-2: Success Restarting pcsd on the nodes in order to reload the certificates... centos7-1: Success centos7-2: Success※「--force」オプションを使用時、これまでの設定が上書きされ、クォーラムやstonishの設定等が消えますので再度設定が必要です。 ※片方のノードで実施 設定確認は以下コマンドで実施します。RING ID 0とRING ID 0の2つのIPアドレスが設定されていることがわかります。 [root@centos7-1 ~]# corosync-cfgtool -s Printing ring status. Local node ID 1 RING ID 0 id = 192.168.10.11 status = ring 0 active with no faults RING ID 1 id = 192.168.0.11 status = ring 1 active with no faults
クラスタのプロパティを設定(CentOS 7向け)
参考URL:Pacemaker/Corosync の設定値について
今回はあくまでも検証目的ですので、STONITHは無効化します。クラスタの設定として、STONITHの無効化を行い、no-quorum-policyをignoreに設定します。
本来、スプリットブレイン発生時の対策として、STONITHは有効化するべきです。
no-quorum-policyについて、通常クォーラムは多数決の原理でアクティブなノードを決定する仕組みですが、2台構成のクラスタの場合は多数決による決定ができません。
この場合、クォーラム設定は「ignore」に設定するのがセオリーのようです。
この時、スプリットブレインが発生したとしても、各ノードのリソースは特に何も制御されないという設定となるため、STONITHによって片方のノードを強制的に電源を落として対応することになります。
それでは設定するために、まず、現状のプロパティを確認します。[root@centos7-1 ~]# pcs property Cluster Properties: cluster-infrastructure: corosync cluster-name: bigbang-cluster1 dc-version: 1.1.19-8.el7_6.4-c3c624ea3d have-watchdog: false設定を変更します。※片方のノードで実施 # pcs property set stonith-enabled=false # pcs property set no-quorum-policy=ignore # pcs property Cluster Properties: cluster-infrastructure: corosync cluster-name: bigbang-cluster1 dc-version: 1.1.19-8.el7_6.4-c3c624ea3d have-watchdog: false no-quorum-policy: ignore stonith-enabled: false
リソースエージェントを使ってリソースを構成する(CentOS 7向け)
参考URL:動かして理解するPacemaker ~CRM設定編~ その2
リソースを制御するために、リソースエージェントを利用します。リソースエージェントとは、クラスタソフトで用意されているリソースの起動・監視・停止を制御するためのスクリプトとなります。
今回の構成では、以下のリソースエージェントを利用します。各リソースエージェントの使用方法は、以下コマンドで確認できます。
- ocf:heartbeat:IPaddr2 : 仮想IPアドレスを制御
- ocf:heartbeat:Filesystem : ファイルシステムのマウントを制御
- systemd:mariadb : MariaDBを制御
# pcs resource describe <リソースエージェント>まず、仮想IPアドレスの設定を行います。付与するIPアドレス・サブネットマスク・NICを指定します。また、interval=30sとして監視間隔を30秒に変更します。※片方のノードで実施 # pcs resource create VirtualIP ocf:heartbeat:IPaddr2 ip=192.168.10.1 cidr_netmask=24 nic=ens192 op monitor interval=30s次に共有ディスクとして作成したファイルシステム「/dev/sdb1」のマウントの設定を行います。マウントするデバイス・マウントポイント・ファイルシステムタイプを指定します。※片方のノードで実施 # pcs resource create ShareDir ocf:heartbeat:Filesystem device=/dev/sdb1 directory=/mnt fstype=ext4最後にMariaDBの設定です。こちらはシンプルに以下コマンドで設定するだけです。※片方のノードで実施 # pcs resource create MariaDB systemd:mariadb上記3つのリソースは起動・停止の順番を考慮する必要があります。
起動:「仮想IPアドレス」→「ファイルシステム」→「MariaDB」
停止:「MariaDB」→「ファイルシステム」→「仮想IPアドレス」
この順序を制御するために、リソースの順序を付けてグループ化した「リソースグループ」を作成します。※片方のノードで実施 # pcs resource group add rg01 VirtualIP ShareDir MariaDB以上でリソース設定が完了となりますので、クラスタの設定を確認します。※片方のノードで実施 [root@centos7-1 ~]# pcs statusリソース設定の詳細内容を確認したい場合、下記コマンドを利用します。Cluster name: bigbang-cluster1 Stack: corosync Current DC: centos7-1c (version 1.1.19-8.el7_6.4-c3c624ea3d) - partition with quorum Last updated: Tue Jul 2 18:19:34 2019 Last change: Tue Jul 2 18:19:17 2019 by root via cibadmin on centos7-1c 2 nodes configured 3 resources configured Online: [ centos7-1c centos7-2c ] Full list of resources: Resource Group: rg01 VirtualIP (ocf::heartbeat:IPaddr2): Started centos7-1c ShareDir (ocf::heartbeat:Filesystem): Started centos7-1c MariaDB (systemd:mariadb): Started centos7-1c Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled[root@centos7-1 ~]# pcs resource show --full
クラスタの起動(CentOS 7向け)
設定が完了しましたので、クラスタを起動します。各リソースが「Started」となっていれば問題ありません。※片方のノードで実施 [root@centos7-1 ~]# pcs cluster start --all centos7-1c: Starting Cluster (corosync)... centos7-2c: Starting Cluster (corosync)... centos7-2c: Starting Cluster (pacemaker)... centos7-1c: Starting Cluster (pacemaker)...起動後のステータスを確認。※片方のノードで実施 [root@centos7-1 ~]# pcs statusCluster name: bigbang-cluster1 Stack: corosync Current DC: centos7-1c (version 1.1.19-8.el7_6.4-c3c624ea3d) - partition with quorum Last updated: Tue Jul 2 18:19:34 2019 Last change: Tue Jul 2 18:19:17 2019 by root via cibadmin on centos7-1c 2 nodes configured 3 resources configured Online: [ centos7-1c centos7-2c ] Full list of resources: Resource Group: rg01 VirtualIP (ocf::heartbeat:IPaddr2): Started centos7-1c ShareDir (ocf::heartbeat:Filesystem): Started centos7-1c MariaDB (systemd:mariadb): Started centos7-1c Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled [root@centos7-1 ~]# pcs status Cluster name: bigbang-cluster1 Stack: corosync Current DC: centos7-2 (version 1.1.19-8.el7_6.4-c3c624ea3d) - partition with quorum Last updated: Wed Jul 3 10:50:41 2019 Last change: Wed Jul 3 10:50:24 2019 by root via cibadmin on centos7-1 2 nodes configured 3 resources configured Online: [ centos7-1 centos7-2 ] Full list of resources: Resource Group: rg01 VirtualIP (ocf::heartbeat:IPaddr2): Started centos7-1 ShareDir (ocf::heartbeat:Filesystem): Started centos7-1 MariaDB (systemd:mariadb): Started centos7-1 Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled
手動フェールオーバーその1
手動でフェールオーバーさせるために、わざわざサーバーを再起動させるのは面倒なので、コマンドでリソースグループをフェールオーバーさせます。[root@centos7-1 ~]# pcs resource show Resource Group: rg01 VirtualIP (ocf::heartbeat:IPaddr2): Started centos7-1 ShareDir (ocf::heartbeat:Filesystem): Started centos7-1 MariaDB (systemd:mariadb): Started centos7-1コマンドでリソースグループrg01をノードcentos7-2に移動させます。[root@centos7-1 ~]# pcs resource move rg01 centos7-2リソースグループがcentos7-2に移動していることが分かります。[root@centos7-1 ~]# pcs resource show Resource Group: rg01 VirtualIP (ocf::heartbeat:IPaddr2): Started centos7-2 ShareDir (ocf::heartbeat:Filesystem): Started centos7-2 MariaDB (systemd:mariadb): Started centos7-2リソースグループをフェイルバックさせます。[root@centos7-1 ~]# pcs resource move rg01 centos7-1元の状態に戻っていることが分かります。[root@centos7-1 ~]# pcs resource show Resource Group: rg01 VirtualIP (ocf::heartbeat:IPaddr2): Started centos7-1 ShareDir (ocf::heartbeat:Filesystem): Started centos7-1 MariaDB (systemd:mariadb): Started centos7-1
手動フェールオーバーその2
コマンドでフェールオーバーさせる手順以外にも、ノードをスタンバイにすることで強制的にリソースグループを移動させることもできます。[root@centos7-1 ~]# pcs status現在リソースグループが起動しているentos7-1をスタンバイにします。Cluster name: bigbang-cluster1 Stack: corosync Current DC: centos7-1 (version 1.1.19-8.el7_6.4-c3c624ea3d) - partition with quorum Last updated: Wed Jul 3 16:32:53 2019 Last change: Wed Jul 3 16:30:07 2019 by root via crm_resource on centos7-1 2 nodes configured 3 resources configured Online: [ centos7-1 centos7-2 ] Full list of resources: Resource Group: rg01 VirtualIP (ocf::heartbeat:IPaddr2): Started centos7-1 ShareDir (ocf::heartbeat:Filesystem): Started centos7-1 MariaDB (systemd:mariadb): Started centos7-1 Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled[root@centos7-1 ~]# pcs cluster standby centos7-1リソースグループrg01が移動していることが分かります。[root@centos7-1 ~]# pcs statusリソースグループrg01をフェイルバックさせるには下記のようにします。Cluster name: bigbang-cluster1 Stack: corosync Current DC: centos7-1 (version 1.1.19-8.el7_6.4-c3c624ea3d) - partition with quorum Last updated: Wed Jul 3 16:33:31 2019 Last change: Wed Jul 3 16:33:26 2019 by root via cibadmin on centos7-1 2 nodes configured 3 resources configured Node centos7-1: standby Online: [ centos7-2 ] Full list of resources: Resource Group: rg01 VirtualIP (ocf::heartbeat:IPaddr2): Started centos7-2 ShareDir (ocf::heartbeat:Filesystem): Started centos7-2 MariaDB (systemd:mariadb): Starting centos7-2 Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled[root@centos7-1 ~]# pcs cluster unstandby centos7-1 [root@centos7-1 ~]# pcs cluster standby centos7-2 [root@centos7-1 ~]# pcs cluster unstandby centos7-2元に戻っていることが確認できます。[root@centos7-1 ~]# pcs statusCluster name: bigbang-cluster1 Stack: corosync Current DC: centos7-1 (version 1.1.19-8.el7_6.4-c3c624ea3d) - partition with quorum Last updated: Wed Jul 3 16:33:59 2019 Last change: Wed Jul 3 16:33:48 2019 by root via cibadmin on centos7-1 2 nodes configured 3 resources configured Online: [ centos7-1 centos7-2 ] Full list of resources: Resource Group: rg01 VirtualIP (ocf::heartbeat:IPaddr2): Started centos7-1 ShareDir (ocf::heartbeat:Filesystem): Started centos7-1 MariaDB (systemd:mariadb): Started centos7-1 Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled
サーバーダウン障害
VMware Host Clientにて、仮想マシンの再起動を実施します。
リソースグループrg01が移動していることが分かります。[root@centos7-2 ~]# pcs status障害になったノードは起動後、クラスタに組み込まれていない状態となります。Cluster name: bigbang-cluster1 Stack: corosync Current DC: centos7-2 (version 1.1.19-8.el7_6.4-c3c624ea3d) - partition with quorum Last updated: Wed Jul 3 16:38:06 2019 Last change: Wed Jul 3 16:33:48 2019 by root via cibadmin on centos7-1 2 nodes configured 3 resources configured Online: [ centos7-2 ] OFFLINE: [ centos7-1 ] Full list of resources: Resource Group: rg01 VirtualIP (ocf::heartbeat:IPaddr2): Started centos7-2 ShareDir (ocf::heartbeat:Filesystem): Started centos7-2 MariaDB (systemd:mariadb): Started centos7-2 Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled[root@centos7-2 ~]# pcs status Error: cluster is not currently running on this nodeこのままではクラスタとして稼働しませんので、元の状態にするためにクラスタに組み込みます。[root@centos7-2 ~]# pcs cluster start centos7-1 centos7-1: Starting Cluster (corosync)... centos7-1: Starting Cluster (pacemaker)...状態を確認すると、元の状態に戻っていることが分かります。[root@centos7-2 ~]# pcs statusCluster name: bigbang-cluster1 Stack: corosync Current DC: centos7-2 (version 1.1.19-8.el7_6.4-c3c624ea3d) - partition with quorum Last updated: Wed Jul 3 16:42:50 2019 Last change: Wed Jul 3 16:33:48 2019 by root via cibadmin on centos7-1 2 nodes configured 3 resources configured Online: [ centos7-1 centos7-2 ] Full list of resources: Resource Group: rg01 VirtualIP (ocf::heartbeat:IPaddr2): Started centos7-1 ShareDir (ocf::heartbeat:Filesystem): Started centos7-1 MariaDB (systemd:mariadb): Starting centos7-1 Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled
NIC障害
参考URL:6.6. リソースの動作
VIPの監視にon-fail=standbyのオプションを指定しないとうまく切り替わらないので、あらかじめ設定しておきます。[root@centos7-1 ~]# pcs resource update VirtualIP op monitor on-fail=standby [root@centos7-1 ~]# pcs resource show --full疑似NIC障害を起こすため、仮想マシンのNICを切断します。Group: rg01 Resource: VirtualIP (class=ocf provider=heartbeat type=IPaddr2) Attributes: cidr_netmask=24 ip=192.168.10.1 nic=ens192 Operations: monitor interval=60s on-fail=standby (VirtualIP-monitor-interval-60s) start interval=0s timeout=20s (VirtualIP-start-interval-0s) stop interval=0s timeout=20s (VirtualIP-stop-interval-0s) Resource: ShareDir (class=ocf provider=heartbeat type=Filesystem) Attributes: device=/dev/sdb1 directory=/mnt fstype=ext4 Operations: monitor interval=20s timeout=40s (ShareDir-monitor-interval-20s) notify interval=0s timeout=60s (ShareDir-notify-interval-0s) start interval=0s timeout=60s (ShareDir-start-interval-0s) stop interval=0s timeout=60s (ShareDir-stop-interval-0s) Resource: MariaDB (class=systemd type=mariadb) Operations: monitor interval=60 timeout=100 (MariaDB-monitor-interval-60) start interval=0s timeout=100 (MariaDB-start-interval-0s) stop interval=0s timeout=100 (MariaDB-stop-interval-0s)
切断するNICは仮想IPアドレスが割り当てられるネットワークに属するNICアダプタです。
1分程度でリソースVirtualIPがFAILEDステータスになり、リソースグループがフェールオーバーされます。root@centos7-2 ~]# pcs status障害ノードを復旧させ、クラスタの状態を戻す場合は、以下コマンドを実行します。Cluster name: bigbang-cluster1 Stack: corosync Current DC: centos7-1 (version 1.1.19-8.el7_6.4-c3c624ea3d) - partition with quorum Last updated: Thu Jul 4 13:36:38 2019 Last change: Thu Jul 4 13:29:54 2019 by root via cibadmin on centos7-1 2 nodes configured 3 resources configured Node centos7-1: standby (on-fail) Online: [ centos7-2 ] Full list of resources: Resource Group: rg01 VirtualIP (ocf::heartbeat:IPaddr2): Started centos7-2 ShareDir (ocf::heartbeat:Filesystem): Started centos7-2 MariaDB (systemd:mariadb): Started centos7-2 Failed Actions: * VirtualIP_monitor_60000 on centos7-1 'not running' (7): call=20, status=complete, exitreason='', last-rc-change='Thu Jul 4 13:35:55 2019', queued=0ms, exec=0ms Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled[root@centos7-1 ~]# pcs resource cleanup Cleaned up all resources on all nodes Waiting for 1 replies from the CRMd. OK [root@centos7-1 ~]# pcs status;date上記コマンドでクラスタを復旧させると、リソースグループが元のノードにフェイルバックするので注意が必要です。Cluster name: bigbang-cluster1 Stack: corosync Current DC: centos7-1 (version 1.1.19-8.el7_6.4-c3c624ea3d) - partition with quorum Last updated: Thu Jul 4 13:43:31 2019 Last change: Thu Jul 4 13:43:13 2019 by hacluster via crmd on centos7-1 2 nodes configured 3 resources configured Online: [ centos7-1 centos7-2 ] Full list of resources: Resource Group: rg01 VirtualIP (ocf::heartbeat:IPaddr2): Started centos7-1 ShareDir (ocf::heartbeat:Filesystem): Started centos7-1 MariaDB (systemd:mariadb): Started centos7-1 Daemon Status: corosync: active/enabled pacemaker: active/enabled pcsd: active/enabled
どうやらもともと稼働していたノードのスコアがINFINITYのままになるため、フェイルバックするようです。
この辺りをきちんと制御する意味でも、STONITHの設定を有効にし、障害が発生したノードは強制停止する設定をした方がよいかもしれません。
●クラスタノードの追加と削除
参考URL:
3台目のノード(centos7-3、centos7-3c)を追加します。
事前に仮想マシンの作成、インストール、ネットワーク設定、共有ディスク接続のための準備等は完了しているものとします。
追加するノード上でpcsdが動作しているか確認します。[root@centos7-3 ~]# systemctl status pcsd ● pcsd.service - PCS GUI and remote configuration interface Loaded: loaded (/usr/lib/systemd/system/pcsd.service; enabled; vendor preset: disabled) Active: active (running) since 木 2019-07-04 15:03:14 JST; 1h 36min ago Docs: man:pcsd(8) man:pcs(8) Main PID: 23964 (pcsd) Tasks: 6 CGroup: /system.slice/pcsd.service └─23964 /usr/bin/ruby /usr/lib/pcsd/pcsd 7月 04 15:03:14 centos7-3.bigbang.mydns.jp systemd[1]: Starting PCS GUI and remote configur..... 7月 04 15:03:14 centos7-3.bigbang.mydns.jp systemd[1]: Started PCS GUI and remote configura...e. Hint: Some lines were ellipsized, use -l to show in full.動作中のノードを含め、再認証を実施します。[root@centos7-1 ~]# pcs cluster auth centos7-1c centos7-2c centos7-3c centos7-1 centos7-2 centos7-3 Username: hacluster Password: centos7-1: Authorized centos7-3: Authorized centos7-2: Authorized centos7-3c: Authorized centos7-1c: Authorized centos7-2c: Authorized既に認証済みの場合、下記のようになります。[root@centos7-1 ~]# pcs cluster auth centos7-1c centos7-2c centos7-3c centos7-1 centos7-2 centos7-3 centos7-1: Already authorized centos7-3: Already authorized centos7-2: Already authorized centos7-3c: Already authorized centos7-1c: Already authorized centos7-2c: Already authorized
クラスタに新たなノードの追加
現在動作中のクラスタグループに該当ノードを参加させます。[root@centos7-1 ~]# pcs cluster node add centos7-3 Disabling SBD service... centos7-3: sbd disabled Sending remote node configuration files to 'centos7-3' centos7-3: successful distribution of the file 'pacemaker_remote authkey' centos7-1c: Corosync updated centos7-2c: Corosync updated Setting up corosync... centos7-3: Succeeded Synchronizing pcsd certificates on nodes centos7-3... centos7-3: Success Restarting pcsd on the nodes in order to reload the certificates... centos7-3: Success ※CentOS Stream 8でVirtualIP、VirtualIP2を設定していた場合、下記のように実行する必要があった [root@centos8-1 ~]# pcs cluster node add centos8-str4 addr=10.0.0.4 addr=192.168.10.4 ※失敗例 [root@centos8-1 ~]# pcs cluster node add centos8-1 No addresses specified for host 'centos8-1', using 'centos8-1' Error: 2 addresses must be specified for a node, 1 address specified for node 'centos8-1' Error: Errors have occurred, therefore pcs is unable to continue centos7-3またはcentos7-3cのいずれかのノード名で実施すればよい。 [root@centos7-1 ~]# pcs cluster node add centos7-3c Error: Unable to add 'centos7-3c' to cluster: node is already in a cluster追加したノードのクラスタを起動します。
追加したノードでコマンドを実行するのではなく、既にクラスタが起動しているノード(下記では、centos7-1)で実行することがポイントです。[root@centos7-1 ~]# pcs cluster start centos7-3 centos7-3: Starting Cluster (corosync)... centos7-3: Starting Cluster (pacemaker)...新たなノードが追加されています。[root@centos7-1 ~]# pcs status Cluster name: bigbang-cluster1 Stack: corosync Current DC: centos7-2c (version 1.1.19-8.el7_6.4-c3c624ea3d) - partition with quorum Last updated: Fri Jul 5 11:09:15 2019 Last change: Fri Jul 5 11:09:04 2019 by hacluster via crmd on centos7-2c 3 nodes configured 3 resources configured Online: [ centos7-1c centos7-2c centos7-3c ] Full list of resources: Resource Group: rg01 VirtualIP (ocf::heartbeat:IPaddr2): Started centos7-1c ShareDir (ocf::heartbeat:Filesystem): Started centos7-1c MariaDB (systemd:mariadb): Started centos7-1c Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled
クラスタからノードの削除
追加したノードを削除します。[root@centos7-1 ~]# pcs cluster node remove centos7-3c centos7-3c: Stopping Cluster (pacemaker)... centos7-3c: Successfully destroyed cluster centos7-1c: Corosync updated centos7-2c: Corosync updated削除されていることが分かります。[root@centos7-1 ~]# pcs status Cluster name: bigbang-cluster1 Stack: corosync Current DC: centos7-2c (version 1.1.19-8.el7_6.4-c3c624ea3d) - partition with quorum Last updated: Fri Jul 5 11:31:54 2019 Last change: Fri Jul 5 11:31:48 2019 by root via crm_node on centos7-1c 2 nodes configured 3 resources configured Online: [ centos7-1c centos7-2c ] ← centos7-3cが消えている Full list of resources: Resource Group: rg01 VirtualIP (ocf::heartbeat:IPaddr2): Started centos7-1c ShareDir (ocf::heartbeat:Filesystem): Started centos7-1c MariaDB (systemd:mariadb): Started centos7-1c Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled
●インストール
双方のサーバに Pacemaker 等をインストールします。# yum -y install pacemaker corosync pcs
●ディレクティブについて
※この設定方法は古いので注意してください(20160630現在)。
各ディレクティブ等はCorosync.conf(5)マニュアルやcorosync.conf の設定メモを参照してください。
●Corosyncの設定
※この設定方法は古いので注意してください(20160630現在)。
pcsコマンドを使用して設定していく●カーネルアップデートに伴う再設定を参照してください。
クラスタ制御部のCorosyncの設定です。corosyncを動作させる全てのサーバで同じように設定する必要があります。# cp /etc/corosync/corosync.conf.example /etc/corosync/corosync.conf # vi /etc/corosync/corosync.conf compatibility: whitetank # 以下追記 aisexec { user: root group: root } service { name: pacemaker ver: 0 use_mgmtd: yes } totem { version: 2 secauth: off threads: 0 interface { ringnumber: 0 # インターコネクト用インターフェースのネットワークアドレスを指定 bindnetaddr: 192.168.20.0 # Fedora 20では、下記のアドレスに変更した amcastaddr: 226.94.1.1 ← 不要と判断し削除 mcastport: 5405 } } logging { fileline: off to_stderr: no to_logfile: yes to_syslog: yes logfile: /var/log/cluster/corosync.log debug: off timestamp: on logger_subsys { # Fedora 20では、下記に変更した subsys: AMF debug: off } } # Fedora 20では、下記を追記 amf { mode: disabled } nodelist { node { ring0_addr: 192.168.20.1 nodeid: 1 } node { ring0_addr: 192.168.20.2 nodeid: 2 } node { ring0_addr: 192.168.20.3 nodeid: 3 } } quorum { # Enable and configure quorum subsystem (default: off) # see also corosync.conf.5 and votequorum.5 provider: corosync_votequorum expected_votes: 3 } # chown -R hacluster. /var/log/cluster # /etc/rc.d/init.d/pacemaker start または systemctl start pacemaker # /etc/rc.d/init.d/corosync start または systemctl start corosync ↑ pacemakerが起動すると連動するので削除 # chkconfig pacemaker on または systemctl enable pacemaker # chkconfig corosync on または systemctl enable corosync ↑ pacemakerが起動すると連動するので削除
●カーネルアップデートに伴う再設定
参考URL:Blue21 - [CentOS7] Pacemaker + corosync のインストール
CentOS 8 Streamでカーネルをアップデートしたところpacemakerが起動しなくなりました。
下記のCentOS 7の時と同じような感じです。
一度クラスタの設定を削除し、関連するソフトを再インストールしました。
CentOS 8 Streamで再インストールしたソフトは pacemaker pcs fence-agents-all drbd90-utils kmod-drbd90 です。
再インストール後、pacemekerをイチから設定し直し対処しました。
CentOS 7でカーネルをアップデートしたところpacemakerが起動しなくなりました。pacemakeやcorosyncに関連するモジュールをreinstallしましたが状況は代わりませんでした。
# systemctl start corosync
Job for corosync.service failed because the control process exited with error code. See "systemctl status corosync.service" and "journalctl -xe" for details.
# systemctl status -l corosync
● corosync.service - Corosync Cluster Engine
Loaded: loaded (/usr/lib/systemd/system/corosync.service; enabled; vendor preset: disabled)
Active: failed (Result: exit-code) since 水 2016-06-29 11:20:24 JST; 30s ago
Process: 18358 ExecStart=/usr/share/corosync/corosync start (code=exited, status=1/FAILURE)
6月 29 11:20:24 serverA.bigbang.mydns.jp systemd[1]: Starting Corosync Cluster Engine...
6月 29 11:20:24 serverA.bigbang.mydns.jp corosync[18373]: [MAIN ] Corosync Cluster Engine ('2.3.4'): started and ready to provide service.
6月 29 11:20:24 serverA.bigbang.mydns.jp corosync[18373]: [MAIN ] Corosync built-in features: dbus systemd xmlconf snmp pie relro bindnow
6月 29 11:20:24 serverA.bigbang.mydns.jp corosync[18373]: [MAIN ] Can't autogenerate multicast address
6月 29 11:20:24 serverA.bigbang.mydns.jp corosync[18373]: [MAIN ] Corosync Cluster Engine exiting with status 8 at main.c:1250.
6月 29 11:20:24 serverA.bigbang.mydns.jp systemd[1]: corosync.service: control process exited, code=exited status=1
6月 29 11:20:24 serverA.bigbang.mydns.jp systemd[1]: Failed to start Corosync Cluster Engine.
6月 29 11:20:24 serverA.bigbang.mydns.jp systemd[1]: Unit corosync.service entered failed state.
6月 29 11:20:24 serverA.bigbang.mydns.jp systemd[1]: corosync.service failed.
6月 29 11:20:24 serverA.bigbang.mydns.jp corosync[18358]: Starting Corosync Cluster Engine (corosync): [失敗]
仕方がないので仕切り直して一から設定し直します。
サーバ環境
サーバ1
OS:CentOS 7
ホスト名:server01
IPアドレス:192.168.20.1
サーバ2
OS:CentOS 7
ホスト名:server02
IPアドレス:192.168.20.2
必要であればpacemakeやcorosync等をインストールします。# yum -y install pacemaker corosync pcspcs はクラスタ管理用のCLIツールです。pcsを使用したクラスタ操作は、クラスタのメンバサーバであれば、いずれか1台のサーバで実行すれば設定が反映されます。ここでは、基本的に「server01」でpcsコマンドを実行しています。
firewalldでクラスタで使用するポートを開けるように設定します。各サーバ個別に実施します。
# firewall-cmd --permanent --add-service=high-availability
success
# firewall-cmd --reload
success
# firewall-cmd --list-service
・・・ high-availability ・・・
サーバ環境で記載しているホスト名が名前解決できるようにDNSまたは/etc/hostsに追加してください。その後、疎通確認します。# vi /etc/hosts 192.168.20.1 server01 192.168.20.2 server02pcsでクラスタの設定を行います。pcsdを起動し、自動起動を有効にします。# systemctl start pcsd # systemctl enable pcsdpcsでコマンドを実行するときにhaclusterユーザを使用します。初期状態ではパスワードが設定されていませんので、パスワードを設定します。各サーバ個別に実施します。# passwd hacluster ユーザ hacluster のパスワードを変更。 新しいパスワード: 新しいパスワードを再入力してください: passwd: すべての認証トークンが正しく更新できました。server01とserver02の信頼関係を設定します。# pcs host auth server01 server02 Username: hacluster Password: server02: Authorized server01: Authorizedそれぞれのサーバに/etc/corosync/corosync.confが存在していることから「--force」を付加してクラスタを設定します。# pcs cluster setup --name mycluster server01 server02 --force Destroying cluster on nodes: server01, server02... server01: Stopping Cluster (pacemaker)... server02: Stopping Cluster (pacemaker)... server02: Successfully destroyed cluster server01: Successfully destroyed cluster Sending cluster config files to the nodes... server01: Succeeded server02: Succeeded Synchronizing pcsd certificates on nodes server01, server02... server02: Success server01: Success Restarting pcsd on the nodes in order to reload the certificates... server02: Success server01: Successこのコマンドの実行によりserver01とserver02に/etc/corosync/corosync.confが新たに作成されます。内容は以下のとおりです。
# cat /etc/corosync/corosync.conf
totem {
version: 2
secauth: off
cluster_name: mycluster
transport: udpu
}
nodelist {
node {
ring0_addr: server01
nodeid: 1
}
node {
ring0_addr: server02
nodeid: 2
}
}
quorum {
provider: corosync_votequorum
two_node: 1
}
logging {
to_logfile: yes
logfile: /var/log/cluster/corosync.log
to_syslog: yes
}
上記の設定の場合、ログは/var/log/cluster/corosync.logに作成されます。ログの出力先を変更したい場合、直接このファイルを編集しクラスタを再起動してください。# pcs cluster stop --all && pcs cluster start --allserver01とserver02のクラスタ(pacemakerとcorosync)は起動しています。pacemakerとcorosyncを自動起動するように設定します。# systemctl enable pacemaker # systemctl enable corosyncpacemakerの状態を確認します。下記はserver01の内容です。
# systemctl status pacemaker
● pacemaker.service - Pacemaker High Availability Cluster Manager
Loaded: loaded (/usr/lib/systemd/system/pacemaker.service; enabled; vendor preset: disabled)
Active: active (running) since 水 2016-06-29 16:16:06 JST; 2h 33min ago
Main PID: 2075 (pacemakerd)
CGroup: /system.slice/pacemaker.service
├─2075 /usr/sbin/pacemakerd -f
├─2078 /usr/libexec/pacemaker/cib
├─2079 /usr/libexec/pacemaker/stonithd
├─2080 /usr/libexec/pacemaker/lrmd
├─2081 /usr/libexec/pacemaker/attrd
├─2082 /usr/libexec/pacemaker/pengine
└─2083 /usr/libexec/pacemaker/crmd
6月 29 18:22:49 server01.bigbang.mydns.jp crmd[2083]: notice: State transition S_IDLE -> S... ]
6月 29 18:22:49 server01.bigbang.mydns.jp pengine[2082]: notice: On loss of CCM Quorum: Ignore
6月 29 18:22:49 server01.bigbang.mydns.jp pengine[2082]: notice: Calculated Transition 16: ...2
6月 29 18:22:49 server01.bigbang.mydns.jp crmd[2083]: notice: Transition 16 (Complete=0, P...te
6月 29 18:22:49 server01.bigbang.mydns.jp crmd[2083]: notice: State transition S_TRANSITIO... ]
6月 29 18:37:49 server01.bigbang.mydns.jp crmd[2083]: notice: State transition S_IDLE -> S... ]
6月 29 18:37:49 server01.bigbang.mydns.jp pengine[2082]: notice: On loss of CCM Quorum: Ignore
6月 29 18:37:49 server01.bigbang.mydns.jp pengine[2082]: notice: Calculated Transition 17: ...2
6月 29 18:37:49 server01.bigbang.mydns.jp crmd[2083]: notice: Transition 17 (Complete=0, P...te
6月 29 18:37:49 server01.bigbang.mydns.jp crmd[2083]: notice: State transition S_TRANSITIO... ]
Hint: Some lines were ellipsized, use -l to show in full.
# systemctl status corosync
● corosync.service - Corosync Cluster Engine
Loaded: loaded (/usr/lib/systemd/system/corosync.service; enabled; vendor preset: disabled)
Active: active (running) since 水 2016-06-29 16:16:06 JST; 2h 33min ago
Main PID: 2069 (corosync)
CGroup: /system.slice/corosync.service
└─2069 corosync
6月 29 16:16:06 server01.bigbang.mydns.jp corosync[2069]: [QUORUM] Members[1]: 1
6月 29 16:16:06 server01.bigbang.mydns.jp corosync[2069]: [MAIN ] Completed service synchro....
6月 29 16:16:06 server01.bigbang.mydns.jp systemd[1]: Started Corosync Cluster Engine.
6月 29 16:16:06 server01.bigbang.mydns.jp corosync[2057]: Starting Corosync Cluster Engine (c...]
6月 29 17:08:15 server01.bigbang.mydns.jp systemd[1]: Started Corosync Cluster Engine.
6月 29 17:08:16 server01.bigbang.mydns.jp corosync[2069]: [TOTEM ] A new membership (192.168...2
6月 29 17:08:16 server01.bigbang.mydns.jp corosync[2069]: [VOTEQ ] Waiting for all cluster m...2
6月 29 17:08:16 server01.bigbang.mydns.jp corosync[2069]: [QUORUM] This node is within the p....
6月 29 17:08:16 server01.bigbang.mydns.jp corosync[2069]: [QUORUM] Members[2]: 1 2
6月 29 17:08:16 server01.bigbang.mydns.jp corosync[2069]: [MAIN ] Completed service synchro....
Hint: Some lines were ellipsized, use -l to show in full.
クラスタの状態を確認します。「server01」で実行します。
# pcs status cluster.
Cluster Status:
Last updated: Wed Jun 29 17:12:14 2016 Last change: Wed Jun 29 16:16:28 2016 by hacluster via crmd on server01
Stack: corosync
Current DC: server01 (version 1.1.13-3.fc22-44eb2dd) - partition with quorum
2 nodes and 0 resources configured
Online: [ server01 server02 ]
PCSD Status:
server01: Online
server02: Online
クラスタメンバ(ノード)の状態を確認します。「server01」で実行します。# pcs status nodes Pacemaker Nodes: Online: server01 server02 Standby: Maintenance: Offline: Pacemaker Remote Nodes: Online: Standby: Maintenance: Offline: # corosync-cmapctl | grep members runtime.totem.pg.mrp.srp.members.1.config_version (u64) = 0 runtime.totem.pg.mrp.srp.members.1.ip (str) = r(0) ip(192.168.20.1) runtime.totem.pg.mrp.srp.members.1.join_count (u32) = 1 runtime.totem.pg.mrp.srp.members.1.status (str) = joined runtime.totem.pg.mrp.srp.members.2.config_version (u64) = 0 runtime.totem.pg.mrp.srp.members.2.ip (str) = r(0) ip(192.168.20.2) runtime.totem.pg.mrp.srp.members.2.join_count (u32) = 1 runtime.totem.pg.mrp.srp.members.2.status (str) = joined # pcs status corosync Membership information ---------------------- Nodeid Votes Name 1 1 server01 (local) 2 1 server02クラスタ、ノード、リソース、デーモンの状態を確認します。「サーバ1」で実行します。
# pcs status
Cluster name: mycluster
Last updated: Wed Jun 29 19:06:50 2016 Last change: Wed Jun 29 17:22:49 2016 by root via crm_attribute on server01
Stack: corosync
Current DC: server01 (version 1.1.13-3.fc22-44eb2dd) - partition with quorum
2 nodes and 1 resource configured
Online: [ server01 ]
Offline: [ server02 ]
Full list of resources:
PCSD Status:
server01: Online
server02: Online
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
クラスタを問題なく構成していたつもりなのに、まれに下記のように「UNCLEAN (Offline)」と表示されクラスタが正常に動作していない場合があります。
# pcs status
Cluster name: bibangcluster
WARNING: no stonith devices and stonith-enabled is not false
Last updated: Fri Oct 14 20:28:30 2016 Last change: Fri Oct 14 17:20:40 2016 by hacluster via crmd on server01
Stack: corosync
Current DC: server01 (version 1.1.13-10.el7_2.4-44eb2dd) - partition WITHOUT quorum
2 nodes and 0 resources configured
Node server02: UNCLEAN (Offline)
Online: [ server01 ]
この場合、一度クラスタ構成をすべてのサーバで停止してください。クラスタを構成しようとしているサーバ(すべてのサーバでpcsdが動作していることが大前提です。)で下記コマンドを実行してください。# pcs cluster stop --all server01: Stopping Cluster (pacemaker)... server02: Stopping Cluster (pacemaker)... server01: Stopping Cluster (corosync)... : (暫く時間がかかった) : server02: Stopping Cluster (corosync)...各サーバのpacemakerとcorosyncは上記コマンドで停止しますが、各サーバのpcsdは動作し続けています。では、再度クラスタを組み込みます。# pcs cluster start --all server01: Starting Cluster... server02: Starting Cluster... # pcs status nodes (問題ないことを確認) # pcs status (問題ないことを確認)これでようやく全てのサーバでクラスタが動作するようになりました。では、正常時の作業に戻ります。
クラスタ設定をチェックします。「server01」で実行します。
# crm_verify -L -V
error: unpack_resources: Resource start-up disabled since no STONITH resources have been defined
error: unpack_resources: Either configure some or disable STONITH with the stonith-enabled option
error: unpack_resources: NOTE: Clusters with shared data need STONITH to ensure data integrity
Errors found during check: config not valid
STONITHの設定をしていないのでエラーになっています。STONITHは、Pacemakerがスプリットブレインを検知したときに強制的にH/Wを電源OFF/ONする機能だそうです。STONISHについては、以下のページが詳しいです。
HAクラスタを フェイルオーバ失敗から 救おう!(PDF)
STONISH はデフォルトで有効になっていますが、検証用の仮想化環境では使用しないので無効にします。# pcs property set stonith-enabled=falseエラーにはなっていませんが、クォーラムの設定も変更します。クォーラムについては、以下が詳しいです。
Pacemakerを使いこなそう
今回は2台構成なので、スプリットブレインが発生しても quorum が特別な動作を行わないように無効にします。# pcs property set no-quorum-policy=ignoreパラメータを確認します。Cluster Properties: cluster-infrastructure: corosync cluster-name: mycluster dc-version: 1.1.13-3.fc22-44eb2dd have-watchdog: false no-quorum-policy: ignore stonith-enabled: false「server02」 をスタンバイにして、状態を確認してみます。# pcs cluster standby server02 # pcs status nodes Pacemaker Nodes: Online: server01 Standby: server02 Maintenance: Offline: Pacemaker Remote Nodes: Online: Standby: Maintenance: Offline:「server02」 をオンラインに戻します。# pcs cluster unstandby server02 # pcs status nodes Pacemaker Nodes: Online: server01 server02 Standby: Maintenance: Offline: Pacemaker Remote Nodes: Online: Standby: Maintenance: Offline:仮想IPを割り当てます。
# pcs resource create dbvip ocf:heartbeat:IPaddr2 ip=192.168.20.100 cidr_netmask=24 op monitor interval=30s
仮想IPが割り当てられていることを確認します。
# ip add show
:
(途中省略)
:
3: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 00:1e:**:**:**:** brd ff:ff:ff:ff:ff:ff
inet 192.168.20.1/24 brd 192.168.20.255 scope global eth1
valid_lft forever preferred_lft forever
inet 192.168.20.100/24 brd 192.168.20.255 scope global secondary eth1
valid_lft forever preferred_lft forever
inet6 fe80::****:****:****:****/64 scope link
valid_lft forever preferred_lft forever
:
(途中省略)
:
これでようやく復活しました。
●pcsコマンドで仮想IPの設定
pcsコマンドを使用して仮想IPを設定します。同時にSTONITHの無効化とスプリットブレインが発生してもquorumが特別な動作を行わないように無効化します。STONITHを無効 # pcs property set stonith-enabled=false スプリットブレインが発生してもクォーラムが特別な動作を行わないように設定 # pcs property set no-quorum-policy=ignore 仮想IP # pcs resource create dbvip ocf:heartbeat:IPaddr2 ip=192.168.20.10000 cidr_netmask=24 nic="eth1" op monitor interval=30socfとは/usr/lib/ocf/resource.d/heartbeat/以下にあるスクリプトです。また、各サーバのインターフェースが「eth1」ではなく共通ではない場合(例:eth1、em1、enp7s4等)は下記のように設定します。仮想IP # pcs resource create dbvip ocf:heartbeat:IPaddr2 ip=192.168.20.10000 cidr_netmask=24 op monitor interval=30scrm_monコマンドで状態を確認します。# crm_mon -A Last updated: Tue Jun 30 13:38:44 2015 Last change: Tue Jun 30 13:28:38 2015 Stack: corosync Current DC: server01.bigbang.mydns.jp (2) - partition with quorum Version: 1.1.12-a14efad 2 Nodes configured 1 Resources configured Online: [ server02.bigbang.mydns.jp server01.bigbang.mydns.jp ] VIP (ocf::heartbeat:IPaddr2): Started server01.bigbang.mydns.jp Node Attributes: * Node server02.bigbang.mydns.jp: * Node server01.bigbang.mydns.jp:仮想アドレスがserver01に割り当てられていることがわかります。
OS再起動やPacemakerが停止しても仮想IPがpacemakerによって自動で付与されることを確認します。
リソースの削除する場合は下記コマンドを実行してください。# pcs resource delete IPaddr2
●フェールオーバーの実施
仮想IPが割り当てられているノードを停止させ、他のノードに移行するかどうか確認します。# pcs cluster stop server02 server02: Stopping Cluster (pacemaker)... server02: Stopping Cluster (corosync)... # pcs status Error: cluster is not currently running on this nodeSSHで仮想IPに対してログインしたところserver01にログインするようになりました。server02のクラスタを起動し、状況を確認します。
# pcs cluster start server02
server02: Starting Cluster...
# pcs status
Cluster name: mycluster
Last updated: Thu Jun 30 10:37:13 2016 Last change: Thu Jun 30 10:32:20 2016 by root via crm_attribute on server02
Stack: corosync
Current DC: server01 (version 1.1.13-3.fc22-44eb2dd) - partition with quorum
2 nodes and 1 resource configured
Online: [ server01 server02 ]
Full list of resources:
dbvip (ocf::heartbeat:IPaddr2): Started server01
PCSD Status:
server01: Online
server02: Online
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
●pcsコマンドでコンフィグ確認
# pcs config Cluster Name: Corosync Nodes: 192.168.20.1 192.168.20.2 192.168.20.3 Pacemaker Nodes: server02.bigbang.mydns.jp server01.bigbang.mydns.jp Resources: Resource: VIP (class=ocf provider=heartbeat type=IPaddr2) Attributes: ip=192.168.20.100 cidr_netmask=24 Operations: start interval=0s timeout=20s (VIP-start-timeout-20s) stop interval=0s timeout=20s (VIP-stop-timeout-20s) monitor interval=10s (VIP-monitor-interval-10s) Stonith Devices: Fencing Levels: Location Constraints: Ordering Constraints: Colocation Constraints: Cluster Properties: cluster-infrastructure: corosync dc-version: 1.1.12-a14efad have-watchdog: false no-quorum-policy: ignore stonith-enabled: false
●設定ファイルを書き出し、読み込み
設定の書き出しは、下記のように実行します。# pcs cluster cib output.cib変更は、下記のように実行します。# pcs -f output.cib >command<設定の読み込みは、下記のように実行します。# pcs cluster cib-push output.cib
●PaceMaker構築前によく使うコマンド
・RA規格(例えばocf)をリストアップする。# pcs resource standards
・プロバイダをリストアップする# pcs resource providers
・プリソースエージェントをリストアップする# pcs resource agents ocf:heartbeat
・プリソースエージェントの説明を表示する# pcs resource describe ocf:heartbeat:IPaddr2
または# crm ra info ocf:heartbeat:IPaddr2
●PaceMaker構築時によく使うコマンド
・Pacemakerリソース設定の初期化方法
すべてのサーバのリソースを停止します。このための簡単な方法は、サーバの状態をスタンバイにすることです。# pcs cluster standby server-name01(サーバ名) # pcs cluster standby server-name02(サーバ名)
次にリソース設定を削除(crm configure erase コマンド)# crm configure erase
サーバをオンライン状態に戻します。# pcs cluster unstandby server-name01(サーバ名) # pcs cluster unstandby server-name02(サーバ名)
・登録済みPacemakerリソースの確認# pcs resource status # pcs resource show
・登録済みPaceMakerリソースの起動順序確認# pcs constraint order Ordering Constraints: promote ms-mysql then start grp-network start res-ping-clone then promote ms-mysql start res-chk-vip1 then start res-vip1
・cluster.confの定義整合性チェック# ccs_config_validate Relax-NG validity error : Extra element cman in interleave tempfile:23: element cman: Relax-NG validity error : Element cluster failed to validate content Configuration fails to validate ※上記はエラーが発生している。エラーがでなければOK
・Pacemaker設定チェック# crm_verify -LV
●PaceMaker環境の運用時によく使うコマンド
・インターコネクトLANの状況確認# crm_mon -fA
・特定時間のログ取得# pcs cluster report --from="2016-01-07 10:30:00" --to="2016-01-07 11:30:00"
・ノード起動状態を確認(Corosync)# corosync-cfgtool -s
・VIP確認# ip addr show
・PaceMakerリソースの復旧
失敗カウントの確認とクリア# pcs resource failcount show <リソースID> # pcs resource failcount reset <リソースID>
リソース状態の確認とクリア# pcs status # pcs resource cleanup <リソースID>主系にて障害が発生し、リソースが自動でフェールオーバーした場合、主系を復旧しリソースをフェールバックしたい場合は、事前にフェールオーバー履歴の削除が必要となります(過去に障害が検出されたノードにはリソースを移動できないため)。
・Location制約の解除# pcs constraint location rm cli-standby-<RSC_NAME> [NODE]元いたノードに対して「もうこっちでは活性化させない」というlocation制約が立ってしまうので、解除
・ノードのスタンバイ&オンライン
ノードのスタンバイ# pcs cluster standby server1(ホスト名)
・ノードのスタンバイ&オンライン
ノードのオンライン# pcs cluster unstandby server1(ホスト名)
・特定リソースの手動によるフェールオーバー# pcs resource move <resource id> [destination node name] ※2台でのクラスタ構成の場合、[destination node name]は不要 # pcs resource clear <resource id>
・リソース監視の失敗回数の確認# pcs resource failcount show res-mysql No failcounts for res-mysql
・PaceMakerリソースの監視状態クリア# pcs resource failcount reset res-mysql # pcs resource cleanup res-mysql
・リソースの個別開始# pcs resource start mysql-clone
・スイッチオーバー# pcs resource move ms-mysql # pcs resource clear ms-mysql # pcs resource move ms-mysql --master
・現行設定のcib.xmlを出力する# pcs cluster cib /tmp/cib.txt
●クラスタ設定の削除
クラスタの設定ファイルをすべて削除し、全クラスタサービスを停止、クラスタ構成を破棄するには下記コマンドを実施します。# pcs cluster stop --all # pcs cluster destroy以上です。
●Active側サーバをstandbyに移行した時のログ確認
動作確認時、Active:centos8-str3、Standby:centos8-str4の状態です。
では早速、centos8-str3をstandbyに切り替えます。
その時のログは下記のとおりです。
約20秒後にcentos8-str4がActiveになりました。
[root@centos8-str3 ~]# pcs node standby centos8-str3;date
2021年 7月 26日 月曜日 13:46:58 JST
※centos8-str4のログ
Jul 26 13:46:58 centos8-str4 pacemaker-controld[4934]: notice: State transition S_IDLE -> S_POLICY_ENGINE
Jul 26 13:46:58 centos8-str4 pacemaker-schedulerd[4933]: notice: On loss of quorum: Ignore
Jul 26 13:46:58 centos8-str4 pacemaker-schedulerd[4933]: notice: * Promote DRBD_r0:0 ( Slave -> Master centos8-str4 )
Jul 26 13:46:58 centos8-str4 pacemaker-schedulerd[4933]: notice: * Stop DRBD_r0:1 ( Master centos8-str3 ) due to node availability
Jul 26 13:46:58 centos8-str4 pacemaker-schedulerd[4933]: notice: * Move FS_DRBD0 ( centos8-str3 -> centos8-str4 )
Jul 26 13:46:58 centos8-str4 pacemaker-schedulerd[4933]: notice: * Move MariaDB ( centos8-str3 -> centos8-str4 )
Jul 26 13:46:58 centos8-str4 pacemaker-schedulerd[4933]: notice: * Move VirtualIP ( centos8-str3 -> centos8-str4 )
Jul 26 13:46:58 centos8-str4 pacemaker-schedulerd[4933]: notice: * Move VirtualIP2 ( centos8-str3 -> centos8-str4 )
Jul 26 13:46:58 centos8-str4 pacemaker-schedulerd[4933]: notice: * Move httpd ( centos8-str3 -> centos8-str4 )
Jul 26 13:46:58 centos8-str4 pacemaker-schedulerd[4933]: notice: * Move php-fpm ( centos8-str3 -> centos8-str4 )
Jul 26 13:46:58 centos8-str4 pacemaker-schedulerd[4933]: notice: * Move zabbix-server ( centos8-str3 -> centos8-str4 )
Jul 26 13:46:58 centos8-str4 pacemaker-schedulerd[4933]: notice: Calculated transition 109, saving inputs in /var/lib/pacemaker/pengine/pe-input-3103.bz2
Jul 26 13:46:58 centos8-str4 pacemaker-controld[4934]: notice: Initiating cancel operation DRBD_r0_monitor_20000 locally on centos8-str4
Jul 26 13:46:58 centos8-str4 pacemaker-controld[4934]: notice: Initiating stop operation FS_DRBD0_stop_0 on centos8-str3
Jul 26 13:46:58 centos8-str4 pacemaker-controld[4934]: notice: Initiating stop operation zabbix-server_stop_0 on centos8-str3
Jul 26 13:46:58 centos8-str4 pacemaker-controld[4934]: notice: Initiating notify operation DRBD_r0_pre_notify_demote_0 locally on centos8-str4
Jul 26 13:46:58 centos8-str4 pacemaker-controld[4934]: notice: Requesting local execution of notify operation for DRBD_r0 on centos8-str4
Jul 26 13:46:58 centos8-str4 pacemaker-controld[4934]: notice: Initiating notify operation DRBD_r0_pre_notify_demote_0 on centos8-str3
Jul 26 13:46:58 centos8-str4 pacemaker-controld[4934]: notice: Result of notify operation for DRBD_r0 on centos8-str4: ok
Jul 26 13:47:00 centos8-str4 pacemaker-controld[4934]: notice: Initiating stop operation php-fpm_stop_0 on centos8-str3
Jul 26 13:47:01 centos8-str4 pacemaker-controld[4934]: notice: Initiating start operation FS_DRBD0_start_0 locally on centos8-str4
Jul 26 13:47:01 centos8-str4 pacemaker-controld[4934]: notice: Requesting local execution of start operation for FS_DRBD0 on centos8-str4
Jul 26 13:47:01 centos8-str4 pacemaker-controld[4934]: notice: Result of start operation for FS_DRBD0 on centos8-str4: ok
Jul 26 13:47:01 centos8-str4 pacemaker-controld[4934]: notice: Initiating monitor operation FS_DRBD0_monitor_20000 locally on centos8-str4
Jul 26 13:47:01 centos8-str4 pacemaker-controld[4934]: notice: Requesting local execution of monitor operation for FS_DRBD0 on centos8-str4
Jul 26 13:47:01 centos8-str4 pacemaker-controld[4934]: notice: Result of monitor operation for FS_DRBD0 on centos8-str4: ok
Jul 26 13:47:06 centos8-str4 pacemaker-controld[4934]: notice: Transition 109 aborted by operation DRBD_r0_monitor_10000 'create' on centos8-str3: Change in recurring result
Jul 26 13:47:06 centos8-str4 pacemaker-controld[4934]: notice: Transition 97 action 5 (DRBD_r0_monitor_10000 on centos8-str3): expected 'master' but got 'ok'
Jul 26 13:47:06 centos8-str4 pacemaker-attrd[4932]: notice: Setting fail-count-DRBD_r0#monitor_10000[centos8-str3]: (unset) -> 1
Jul 26 13:47:06 centos8-str4 pacemaker-attrd[4932]: notice: Setting last-failure-DRBD_r0#monitor_10000[centos8-str3]: (unset) -> 1627274826
Jul 26 13:47:15 centos8-str4 pacemaker-controld[4934]: notice: Transition 109 (Complete=11, Pending=0, Fired=0, Skipped=1, Incomplete=46, Source=/var/lib/pacemaker/pengine/pe-input-3103.bz2): Stopped
Jul 26 13:47:15 centos8-str4 pacemaker-schedulerd[4933]: notice: On loss of quorum: Ignore
Jul 26 13:47:15 centos8-str4 pacemaker-schedulerd[4933]: warning: Unexpected result (ok) was recorded for monitor of DRBD_r0:1 on centos8-str3 at Jul 26 13:47:06 2021
Jul 26 13:47:15 centos8-str4 pacemaker-schedulerd[4933]: warning: Forcing DRBD_r0-clone away from centos8-str3 after 1 failures (max=1)
Jul 26 13:47:15 centos8-str4 pacemaker-schedulerd[4933]: warning: Forcing DRBD_r0-clone away from centos8-str3 after 1 failures (max=1)
Jul 26 13:47:15 centos8-str4 pacemaker-schedulerd[4933]: notice: * Promote DRBD_r0:0 ( Slave -> Master centos8-str4 )
Jul 26 13:47:15 centos8-str4 pacemaker-schedulerd[4933]: notice: * Stop DRBD_r0:1 ( Master centos8-str3 ) due to node availability
Jul 26 13:47:15 centos8-str4 pacemaker-schedulerd[4933]: notice: * Move MariaDB ( centos8-str3 -> centos8-str4 )
Jul 26 13:47:15 centos8-str4 pacemaker-schedulerd[4933]: notice: * Move VirtualIP ( centos8-str3 -> centos8-str4 )
Jul 26 13:47:15 centos8-str4 pacemaker-schedulerd[4933]: notice: * Move VirtualIP2 ( centos8-str3 -> centos8-str4 )
Jul 26 13:47:15 centos8-str4 pacemaker-schedulerd[4933]: notice: * Move httpd ( centos8-str3 -> centos8-str4 )
Jul 26 13:47:15 centos8-str4 pacemaker-schedulerd[4933]: notice: * Start php-fpm ( centos8-str4 )
Jul 26 13:47:15 centos8-str4 pacemaker-schedulerd[4933]: notice: * Start zabbix-server ( centos8-str4 )
Jul 26 13:47:15 centos8-str4 pacemaker-schedulerd[4933]: notice: Calculated transition 110, saving inputs in /var/lib/pacemaker/pengine/pe-input-3104.bz2
Jul 26 13:47:15 centos8-str4 pacemaker-controld[4934]: notice: Initiating stop operation httpd_stop_0 on centos8-str3
Jul 26 13:47:15 centos8-str4 pacemaker-controld[4934]: notice: Initiating notify operation DRBD_r0_pre_notify_demote_0 locally on centos8-str4
Jul 26 13:47:15 centos8-str4 pacemaker-controld[4934]: notice: Requesting local execution of notify operation for DRBD_r0 on centos8-str4
Jul 26 13:47:15 centos8-str4 pacemaker-controld[4934]: notice: Initiating notify operation DRBD_r0_pre_notify_demote_0 on centos8-str3
Jul 26 13:47:15 centos8-str4 pacemaker-controld[4934]: notice: Result of notify operation for DRBD_r0 on centos8-str4: ok
Jul 26 13:47:15 centos8-str4 pacemaker-controld[4934]: notice: Transition 110 aborted by operation MariaDB_monitor_60000 'create' on centos8-str3: Change in recurring result
Jul 26 13:47:15 centos8-str4 pacemaker-controld[4934]: notice: Transition 97 action 33 (MariaDB_monitor_60000 on centos8-str3): expected 'ok' but got 'not running'
Jul 26 13:47:15 centos8-str4 pacemaker-attrd[4932]: notice: Setting fail-count-MariaDB#monitor_60000[centos8-str3]: (unset) -> 1
Jul 26 13:47:15 centos8-str4 pacemaker-attrd[4932]: notice: Setting last-failure-MariaDB#monitor_60000[centos8-str3]: (unset) -> 1627274835
Jul 26 13:47:17 centos8-str4 pacemaker-controld[4934]: notice: Transition 110 (Complete=6, Pending=0, Fired=0, Skipped=1, Incomplete=45, Source=/var/lib/pacemaker/pengine/pe-input-3104.bz2): Stopped
Jul 26 13:47:17 centos8-str4 pacemaker-schedulerd[4933]: notice: On loss of quorum: Ignore
Jul 26 13:47:17 centos8-str4 pacemaker-schedulerd[4933]: warning: Unexpected result (not running) was recorded for monitor of MariaDB on centos8-str3 at Jul 26 13:47:15 2021
Jul 26 13:47:17 centos8-str4 pacemaker-schedulerd[4933]: warning: Unexpected result (ok) was recorded for monitor of DRBD_r0:1 on centos8-str3 at Jul 26 13:47:06 2021
Jul 26 13:47:17 centos8-str4 pacemaker-schedulerd[4933]: warning: Forcing DRBD_r0-clone away from centos8-str3 after 1 failures (max=1)
Jul 26 13:47:17 centos8-str4 pacemaker-schedulerd[4933]: warning: Forcing DRBD_r0-clone away from centos8-str3 after 1 failures (max=1)
Jul 26 13:47:17 centos8-str4 pacemaker-schedulerd[4933]: warning: Forcing MariaDB away from centos8-str3 after 1 failures (max=1)
Jul 26 13:47:17 centos8-str4 pacemaker-schedulerd[4933]: notice: * Promote DRBD_r0:0 ( Slave -> Master centos8-str4 )
Jul 26 13:47:17 centos8-str4 pacemaker-schedulerd[4933]: notice: * Stop DRBD_r0:1 ( Master centos8-str3 ) due to node availability
Jul 26 13:47:17 centos8-str4 pacemaker-schedulerd[4933]: notice: * Recover MariaDB ( centos8-str3 -> centos8-str4 )
Jul 26 13:47:17 centos8-str4 pacemaker-schedulerd[4933]: notice: * Move VirtualIP ( centos8-str3 -> centos8-str4 )
Jul 26 13:47:17 centos8-str4 pacemaker-schedulerd[4933]: notice: * Move VirtualIP2 ( centos8-str3 -> centos8-str4 )
Jul 26 13:47:17 centos8-str4 pacemaker-schedulerd[4933]: notice: * Start httpd ( centos8-str4 )
Jul 26 13:47:17 centos8-str4 pacemaker-schedulerd[4933]: notice: * Start php-fpm ( centos8-str4 )
Jul 26 13:47:17 centos8-str4 pacemaker-schedulerd[4933]: notice: * Start zabbix-server ( centos8-str4 )
Jul 26 13:47:17 centos8-str4 pacemaker-schedulerd[4933]: notice: Calculated transition 111, saving inputs in /var/lib/pacemaker/pengine/pe-input-3105.bz2
Jul 26 13:47:17 centos8-str4 pacemaker-controld[4934]: notice: Initiating stop operation VirtualIP2_stop_0 on centos8-str3
Jul 26 13:47:17 centos8-str4 pacemaker-controld[4934]: notice: Initiating notify operation DRBD_r0_pre_notify_demote_0 locally on centos8-str4
Jul 26 13:47:17 centos8-str4 pacemaker-controld[4934]: notice: Requesting local execution of notify operation for DRBD_r0 on centos8-str4
Jul 26 13:47:17 centos8-str4 pacemaker-controld[4934]: notice: Initiating notify operation DRBD_r0_pre_notify_demote_0 on centos8-str3
Jul 26 13:47:17 centos8-str4 pacemaker-controld[4934]: notice: Result of notify operation for DRBD_r0 on centos8-str4: ok
Jul 26 13:47:17 centos8-str4 pacemaker-controld[4934]: notice: Initiating stop operation VirtualIP_stop_0 on centos8-str3
Jul 26 13:47:17 centos8-str4 pacemaker-controld[4934]: notice: Initiating stop operation MariaDB_stop_0 on centos8-str3
Jul 26 13:47:19 centos8-str4 pacemaker-controld[4934]: notice: Initiating demote operation DRBD_r0_demote_0 on centos8-str3
Jul 26 13:47:19 centos8-str4 pacemaker-controld[4934]: notice: Initiating notify operation DRBD_r0_post_notify_demote_0 locally on centos8-str4
Jul 26 13:47:19 centos8-str4 pacemaker-controld[4934]: notice: Requesting local execution of notify operation for DRBD_r0 on centos8-str4
Jul 26 13:47:19 centos8-str4 pacemaker-controld[4934]: notice: Initiating notify operation DRBD_r0_post_notify_demote_0 on centos8-str3
Jul 26 13:47:19 centos8-str4 pacemaker-controld[4934]: notice: Result of notify operation for DRBD_r0 on centos8-str4: ok
Jul 26 13:47:19 centos8-str4 pacemaker-controld[4934]: notice: Initiating notify operation DRBD_r0_pre_notify_stop_0 locally on centos8-str4
Jul 26 13:47:19 centos8-str4 pacemaker-controld[4934]: notice: Requesting local execution of notify operation for DRBD_r0 on centos8-str4
Jul 26 13:47:19 centos8-str4 pacemaker-controld[4934]: notice: Initiating notify operation DRBD_r0_pre_notify_stop_0 on centos8-str3
Jul 26 13:47:19 centos8-str4 pacemaker-controld[4934]: notice: Result of notify operation for DRBD_r0 on centos8-str4: ok
Jul 26 13:47:19 centos8-str4 pacemaker-controld[4934]: notice: Initiating stop operation DRBD_r0_stop_0 on centos8-str3
Jul 26 13:47:19 centos8-str4 pacemaker-attrd[4932]: notice: Setting master-DRBD_r0[centos8-str3]: 10000 -> (unset)
Jul 26 13:47:19 centos8-str4 pacemaker-controld[4934]: notice: Transition 111 aborted by deletion of nvpair[@id='status-1-master-DRBD_r0']: Transient attribute change
Jul 26 13:47:19 centos8-str4 pacemaker-controld[4934]: notice: Initiating notify operation DRBD_r0_post_notify_stop_0 locally on centos8-str4
Jul 26 13:47:19 centos8-str4 pacemaker-controld[4934]: notice: Requesting local execution of notify operation for DRBD_r0 on centos8-str4
Jul 26 13:47:19 centos8-str4 pacemaker-controld[4934]: notice: Result of notify operation for DRBD_r0 on centos8-str4: ok
Jul 26 13:47:19 centos8-str4 pacemaker-controld[4934]: notice: Transition 111 (Complete=27, Pending=0, Fired=0, Skipped=1, Incomplete=23, Source=/var/lib/pacemaker/pengine/pe-input-3105.bz2): Stopped
Jul 26 13:47:19 centos8-str4 pacemaker-schedulerd[4933]: notice: On loss of quorum: Ignore
Jul 26 13:47:19 centos8-str4 pacemaker-schedulerd[4933]: warning: Unexpected result (not running) was recorded for monitor of MariaDB on centos8-str3 at Jul 26 13:47:15 2021
Jul 26 13:47:19 centos8-str4 pacemaker-schedulerd[4933]: warning: Unexpected result (ok) was recorded for monitor of DRBD_r0:1 on centos8-str3 at Jul 26 13:47:06 2021
Jul 26 13:47:19 centos8-str4 pacemaker-schedulerd[4933]: warning: Forcing DRBD_r0-clone away from centos8-str3 after 1 failures (max=1)
Jul 26 13:47:19 centos8-str4 pacemaker-schedulerd[4933]: warning: Forcing DRBD_r0-clone away from centos8-str3 after 1 failures (max=1)
Jul 26 13:47:19 centos8-str4 pacemaker-schedulerd[4933]: warning: Forcing MariaDB away from centos8-str3 after 1 failures (max=1)
Jul 26 13:47:19 centos8-str4 pacemaker-schedulerd[4933]: notice: * Promote DRBD_r0:0 ( Slave -> Master centos8-str4 )
Jul 26 13:47:19 centos8-str4 pacemaker-schedulerd[4933]: notice: * Start MariaDB ( centos8-str4 )
Jul 26 13:47:19 centos8-str4 pacemaker-schedulerd[4933]: notice: * Start VirtualIP ( centos8-str4 )
Jul 26 13:47:19 centos8-str4 pacemaker-schedulerd[4933]: notice: * Start VirtualIP2 ( centos8-str4 )
Jul 26 13:47:19 centos8-str4 pacemaker-schedulerd[4933]: notice: * Start httpd ( centos8-str4 )
Jul 26 13:47:19 centos8-str4 pacemaker-schedulerd[4933]: notice: * Start php-fpm ( centos8-str4 )
Jul 26 13:47:19 centos8-str4 pacemaker-schedulerd[4933]: notice: * Start zabbix-server ( centos8-str4 )
Jul 26 13:47:19 centos8-str4 pacemaker-schedulerd[4933]: notice: Calculated transition 112, saving inputs in /var/lib/pacemaker/pengine/pe-input-3106.bz2
Jul 26 13:47:19 centos8-str4 pacemaker-controld[4934]: notice: Initiating notify operation DRBD_r0_pre_notify_promote_0 locally on centos8-str4
Jul 26 13:47:19 centos8-str4 pacemaker-controld[4934]: notice: Requesting local execution of notify operation for DRBD_r0 on centos8-str4
Jul 26 13:47:19 centos8-str4 pacemaker-controld[4934]: notice: Result of notify operation for DRBD_r0 on centos8-str4: ok
Jul 26 13:47:19 centos8-str4 pacemaker-controld[4934]: notice: Initiating promote operation DRBD_r0_promote_0 locally on centos8-str4
Jul 26 13:47:19 centos8-str4 pacemaker-controld[4934]: notice: Requesting local execution of promote operation for DRBD_r0 on centos8-str4
Jul 26 13:47:19 centos8-str4 pacemaker-controld[4934]: notice: Result of promote operation for DRBD_r0 on centos8-str4: ok
Jul 26 13:47:19 centos8-str4 pacemaker-controld[4934]: notice: Initiating notify operation DRBD_r0_post_notify_promote_0 locally on centos8-str4
Jul 26 13:47:19 centos8-str4 pacemaker-controld[4934]: notice: Requesting local execution of notify operation for DRBD_r0 on centos8-str4
Jul 26 13:47:19 centos8-str4 pacemaker-controld[4934]: notice: Result of notify operation for DRBD_r0 on centos8-str4: ok
Jul 26 13:47:19 centos8-str4 pacemaker-controld[4934]: notice: Initiating start operation MariaDB_start_0 locally on centos8-str4
Jul 26 13:47:19 centos8-str4 pacemaker-controld[4934]: notice: Requesting local execution of start operation for MariaDB on centos8-str4
Jul 26 13:47:19 centos8-str4 pacemaker-controld[4934]: notice: Initiating monitor operation DRBD_r0_monitor_10000 locally on centos8-str4
Jul 26 13:47:19 centos8-str4 pacemaker-controld[4934]: notice: Requesting local execution of monitor operation for DRBD_r0 on centos8-str4
Jul 26 13:47:19 centos8-str4 pacemaker-controld[4934]: notice: Result of monitor operation for DRBD_r0 on centos8-str4: master
Jul 26 13:47:21 centos8-str4 pacemaker-controld[4934]: notice: Result of start operation for MariaDB on centos8-str4: ok
Jul 26 13:47:21 centos8-str4 pacemaker-controld[4934]: notice: Initiating monitor operation MariaDB_monitor_60000 locally on centos8-str4
Jul 26 13:47:21 centos8-str4 pacemaker-controld[4934]: notice: Requesting local execution of monitor operation for MariaDB on centos8-str4
Jul 26 13:47:21 centos8-str4 pacemaker-controld[4934]: notice: Initiating start operation VirtualIP_start_0 locally on centos8-str4
Jul 26 13:47:21 centos8-str4 pacemaker-controld[4934]: notice: Requesting local execution of start operation for VirtualIP on centos8-str4
Jul 26 13:47:21 centos8-str4 pacemaker-controld[4934]: notice: Result of monitor operation for MariaDB on centos8-str4: ok
Jul 26 13:47:22 centos8-str4 pacemaker-controld[4934]: notice: Result of start operation for VirtualIP on centos8-str4: ok
Jul 26 13:47:22 centos8-str4 pacemaker-controld[4934]: notice: Initiating monitor operation VirtualIP_monitor_30000 locally on centos8-str4
Jul 26 13:47:22 centos8-str4 pacemaker-controld[4934]: notice: Requesting local execution of monitor operation for VirtualIP on centos8-str4
Jul 26 13:47:22 centos8-str4 pacemaker-controld[4934]: notice: Initiating start operation VirtualIP2_start_0 locally on centos8-str4
Jul 26 13:47:22 centos8-str4 pacemaker-controld[4934]: notice: Requesting local execution of start operation for VirtualIP2 on centos8-str4
Jul 26 13:47:22 centos8-str4 pacemaker-controld[4934]: notice: Result of monitor operation for VirtualIP on centos8-str4: ok
Jul 26 13:47:22 centos8-str4 pacemaker-controld[4934]: notice: Result of start operation for VirtualIP2 on centos8-str4: ok
Jul 26 13:47:22 centos8-str4 pacemaker-controld[4934]: notice: Initiating monitor operation VirtualIP2_monitor_10000 locally on centos8-str4
Jul 26 13:47:22 centos8-str4 pacemaker-controld[4934]: notice: Requesting local execution of monitor operation for VirtualIP2 on centos8-str4
Jul 26 13:47:22 centos8-str4 pacemaker-controld[4934]: notice: Initiating start operation httpd_start_0 locally on centos8-str4
Jul 26 13:47:22 centos8-str4 pacemaker-controld[4934]: notice: Requesting local execution of start operation for httpd on centos8-str4
Jul 26 13:47:22 centos8-str4 pacemaker-controld[4934]: notice: Result of monitor operation for VirtualIP2 on centos8-str4: ok
Jul 26 13:47:24 centos8-str4 pacemaker-controld[4934]: notice: Result of start operation for httpd on centos8-str4: ok
Jul 26 13:47:24 centos8-str4 pacemaker-controld[4934]: notice: Initiating monitor operation httpd_monitor_60000 locally on centos8-str4
Jul 26 13:47:24 centos8-str4 pacemaker-controld[4934]: notice: Requesting local execution of monitor operation for httpd on centos8-str4
Jul 26 13:47:24 centos8-str4 pacemaker-controld[4934]: notice: Initiating start operation php-fpm_start_0 locally on centos8-str4
Jul 26 13:47:24 centos8-str4 pacemaker-controld[4934]: notice: Requesting local execution of start operation for php-fpm on centos8-str4
Jul 26 13:47:24 centos8-str4 pacemaker-controld[4934]: notice: Result of monitor operation for httpd on centos8-str4: ok
Jul 26 13:47:26 centos8-str4 pacemaker-controld[4934]: notice: Result of start operation for php-fpm on centos8-str4: ok
Jul 26 13:47:26 centos8-str4 pacemaker-controld[4934]: notice: Initiating monitor operation php-fpm_monitor_60000 locally on centos8-str4
Jul 26 13:47:26 centos8-str4 pacemaker-controld[4934]: notice: Requesting local execution of monitor operation for php-fpm on centos8-str4
Jul 26 13:47:26 centos8-str4 pacemaker-controld[4934]: notice: Initiating start operation zabbix-server_start_0 locally on centos8-str4
Jul 26 13:47:26 centos8-str4 pacemaker-controld[4934]: notice: Requesting local execution of start operation for zabbix-server on centos8-str4
Jul 26 13:47:26 centos8-str4 pacemaker-controld[4934]: notice: Result of monitor operation for php-fpm on centos8-str4: ok
Jul 26 13:47:28 centos8-str4 pacemaker-controld[4934]: notice: Result of start operation for zabbix-server on centos8-str4: ok
Jul 26 13:47:28 centos8-str4 pacemaker-controld[4934]: notice: Initiating monitor operation zabbix-server_monitor_60000 locally on centos8-str4
Jul 26 13:47:28 centos8-str4 pacemaker-controld[4934]: notice: Requesting local execution of monitor operation for zabbix-server on centos8-str4
Jul 26 13:47:28 centos8-str4 pacemaker-controld[4934]: notice: Result of monitor operation for zabbix-server on centos8-str4: ok
Jul 26 13:47:28 centos8-str4 pacemaker-controld[4934]: notice: Transition 112 (Complete=24, Pending=0, Fired=0, Skipped=0, Incomplete=0, Source=/var/lib/pacemaker/pengine/pe-input-3106.bz2): Complete
Jul 26 13:47:28 centos8-str4 pacemaker-controld[4934]: notice: State transition S_TRANSITION_ENGINE -> S_IDLE
※centos8-str3のログ
Jul 26 13:46:58 centos8-str3 pacemaker-controld[5135]: notice: Requesting local execution of stop operation for FS_DRBD0 on centos8-str3
Jul 26 13:46:58 centos8-str3 pacemaker-controld[5135]: notice: Requesting local execution of stop operation for zabbix-server on centos8-str3
Jul 26 13:46:58 centos8-str3 pacemaker-controld[5135]: notice: Requesting local execution of notify operation for DRBD_r0 on centos8-str3
Jul 26 13:46:58 centos8-str3 pacemaker-controld[5135]: notice: Result of notify operation for DRBD_r0 on centos8-str3: ok
Jul 26 13:47:00 centos8-str3 pacemaker-controld[5135]: notice: Result of stop operation for zabbix-server on centos8-str3: ok
Jul 26 13:47:00 centos8-str3 pacemaker-controld[5135]: notice: Requesting local execution of stop operation for php-fpm on centos8-str3
Jul 26 13:47:01 centos8-str3 pacemaker-execd[5132]: notice: FS_DRBD0_stop_0[365641] error output [ umount: /mnt: target is busy. ]
Jul 26 13:47:01 centos8-str3 pacemaker-execd[5132]: notice: FS_DRBD0_stop_0[365641] error output [ ocf-exit-reason:Couldn't unmount /mnt; trying cleanup with TERM ]
Jul 26 13:47:01 centos8-str3 pacemaker-execd[5132]: notice: FS_DRBD0_stop_0[365641] error output [ umount: /mnt: target is busy. ]
Jul 26 13:47:01 centos8-str3 pacemaker-execd[5132]: notice: FS_DRBD0_stop_0[365641] error output [ ocf-exit-reason:Couldn't unmount /mnt; trying cleanup with TERM ]
Jul 26 13:47:01 centos8-str3 pacemaker-controld[5135]: notice: Result of stop operation for FS_DRBD0 on centos8-str3: ok
Jul 26 13:47:06 centos8-str3 pacemaker-controld[5135]: notice: Result of monitor operation for DRBD_r0 on centos8-str3: ok
Jul 26 13:47:06 centos8-str3 pacemaker-attrd[5133]: notice: Setting fail-count-DRBD_r0#monitor_10000[centos8-str3]: (unset) -> 1
Jul 26 13:47:06 centos8-str3 pacemaker-attrd[5133]: notice: Setting last-failure-DRBD_r0#monitor_10000[centos8-str3]: (unset) -> 1627274826
Jul 26 13:47:15 centos8-str3 pacemaker-controld[5135]: notice: Result of stop operation for php-fpm on centos8-str3: ok
Jul 26 13:47:15 centos8-str3 pacemaker-controld[5135]: notice: Requesting local execution of stop operation for httpd on centos8-str3
Jul 26 13:47:15 centos8-str3 pacemaker-controld[5135]: notice: Requesting local execution of notify operation for DRBD_r0 on centos8-str3
Jul 26 13:47:15 centos8-str3 pacemaker-controld[5135]: notice: Result of notify operation for DRBD_r0 on centos8-str3: ok
Jul 26 13:47:15 centos8-str3 pacemaker-controld[5135]: notice: Result of monitor operation for MariaDB on centos8-str3: not running
Jul 26 13:47:15 centos8-str3 pacemaker-attrd[5133]: notice: Setting fail-count-MariaDB#monitor_60000[centos8-str3]: (unset) -> 1
Jul 26 13:47:15 centos8-str3 pacemaker-attrd[5133]: notice: Setting last-failure-MariaDB#monitor_60000[centos8-str3]: (unset) -> 1627274835
Jul 26 13:47:17 centos8-str3 pacemaker-controld[5135]: notice: Result of stop operation for httpd on centos8-str3: ok
Jul 26 13:47:17 centos8-str3 pacemaker-controld[5135]: notice: Requesting local execution of stop operation for VirtualIP2 on centos8-str3
Jul 26 13:47:17 centos8-str3 pacemaker-controld[5135]: notice: Requesting local execution of notify operation for DRBD_r0 on centos8-str3
Jul 26 13:47:17 centos8-str3 pacemaker-controld[5135]: notice: Result of notify operation for DRBD_r0 on centos8-str3: ok
Jul 26 13:47:17 centos8-str3 pacemaker-controld[5135]: notice: Result of stop operation for VirtualIP2 on centos8-str3: ok
Jul 26 13:47:17 centos8-str3 pacemaker-controld[5135]: notice: Requesting local execution of stop operation for VirtualIP on centos8-str3
Jul 26 13:47:17 centos8-str3 pacemaker-controld[5135]: notice: Result of stop operation for VirtualIP on centos8-str3: ok
Jul 26 13:47:17 centos8-str3 pacemaker-controld[5135]: notice: Requesting local execution of stop operation for MariaDB on centos8-str3
Jul 26 13:47:19 centos8-str3 pacemaker-controld[5135]: notice: Result of stop operation for MariaDB on centos8-str3: ok
Jul 26 13:47:19 centos8-str3 pacemaker-controld[5135]: notice: Requesting local execution of demote operation for DRBD_r0 on centos8-str3
Jul 26 13:47:19 centos8-str3 pacemaker-controld[5135]: notice: Result of demote operation for DRBD_r0 on centos8-str3: ok
Jul 26 13:47:19 centos8-str3 pacemaker-controld[5135]: notice: Requesting local execution of notify operation for DRBD_r0 on centos8-str3
Jul 26 13:47:19 centos8-str3 pacemaker-controld[5135]: notice: Result of notify operation for DRBD_r0 on centos8-str3: ok
Jul 26 13:47:19 centos8-str3 pacemaker-controld[5135]: notice: Requesting local execution of notify operation for DRBD_r0 on centos8-str3
Jul 26 13:47:19 centos8-str3 pacemaker-controld[5135]: notice: Result of notify operation for DRBD_r0 on centos8-str3: ok
Jul 26 13:47:19 centos8-str3 pacemaker-controld[5135]: notice: Requesting local execution of stop operation for DRBD_r0 on centos8-str3
Jul 26 13:47:19 centos8-str3 pacemaker-attrd[5133]: notice: Setting master-DRBD_r0[centos8-str3]: 10000 -> (unset)
Jul 26 13:47:19 centos8-str3 pacemaker-controld[5135]: notice: Result of stop operation for DRBD_r0 on centos8-str3: ok
クリーンアップ時のログを確認します。
[root@centos8-str3 ~]# pcs resource cleanup
Cleaned up all resources on all nodes
Waiting for 2 replies from the controller
... got reply
... got reply (done)
※centos8-str4のログ
Jul 26 13:49:01 centos8-str4 pacemaker-attrd[4932]: notice: Setting last-failure-MariaDB#monitor_60000[centos8-str3]: 1627274835 -> (unset)
Jul 26 13:49:01 centos8-str4 pacemaker-attrd[4932]: notice: Setting fail-count-DRBD_r0#monitor_10000[centos8-str3]: 1 -> (unset)
Jul 26 13:49:01 centos8-str4 pacemaker-attrd[4932]: notice: Setting fail-count-MariaDB#monitor_60000[centos8-str3]: 1 -> (unset)
Jul 26 13:49:01 centos8-str4 pacemaker-attrd[4932]: notice: Setting last-failure-DRBD_r0#monitor_10000[centos8-str3]: 1627274826 -> (unset)
Jul 26 13:49:01 centos8-str4 pacemaker-controld[4934]: notice: State transition S_IDLE -> S_POLICY_ENGINE
Jul 26 13:49:01 centos8-str4 pacemaker-schedulerd[4933]: notice: On loss of quorum: Ignore
Jul 26 13:49:01 centos8-str4 pacemaker-schedulerd[4933]: warning: Forcing DRBD_r0-clone away from centos8-str3 after 1 failures (max=1)
Jul 26 13:49:01 centos8-str4 pacemaker-schedulerd[4933]: warning: Forcing DRBD_r0-clone away from centos8-str3 after 1 failures (max=1)
Jul 26 13:49:01 centos8-str4 pacemaker-schedulerd[4933]: warning: Forcing MariaDB away from centos8-str3 after 1 failures (max=1)
Jul 26 13:49:01 centos8-str4 pacemaker-schedulerd[4933]: notice: Calculated transition 113, saving inputs in /var/lib/pacemaker/pengine/pe-input-3107.bz2
Jul 26 13:49:01 centos8-str4 pacemaker-schedulerd[4933]: notice: On loss of quorum: Ignore
Jul 26 13:49:01 centos8-str4 pacemaker-schedulerd[4933]: notice: Calculated transition 114, saving inputs in /var/lib/pacemaker/pengine/pe-input-3108.bz2
Jul 26 13:49:01 centos8-str4 pacemaker-controld[4934]: notice: Initiating monitor operation DRBD_r0_monitor_0 on centos8-str3
Jul 26 13:49:01 centos8-str4 pacemaker-controld[4934]: notice: Initiating monitor operation MariaDB_monitor_0 on centos8-str3
Jul 26 13:49:01 centos8-str4 pacemaker-controld[4934]: notice: Transition 114 (Complete=2, Pending=0, Fired=0, Skipped=0, Incomplete=0, Source=/var/lib/pacemaker/pengine/pe-input-3108.bz2): Complete
Jul 26 13:49:01 centos8-str4 pacemaker-controld[4934]: notice: State transition S_TRANSITION_ENGINE -> S_IDLE
※centos8-str3のログ
Jul 26 13:49:01 centos8-str3 pacemaker-attrd[5133]: notice: Setting last-failure-MariaDB#monitor_60000[centos8-str3]: 1627274835 -> (unset)
Jul 26 13:49:01 centos8-str3 pacemaker-attrd[5133]: notice: Setting fail-count-DRBD_r0#monitor_10000[centos8-str3]: 1 -> (unset)
Jul 26 13:49:01 centos8-str3 pacemaker-attrd[5133]: notice: Setting fail-count-MariaDB#monitor_60000[centos8-str3]: 1 -> (unset)
Jul 26 13:49:01 centos8-str3 pacemaker-attrd[5133]: notice: Setting last-failure-DRBD_r0#monitor_10000[centos8-str3]: 1627274826 -> (unset)
Jul 26 13:49:01 centos8-str3 pacemaker-controld[5135]: notice: Requesting local execution of probe operation for DRBD_r0 on centos8-str3
Jul 26 13:49:01 centos8-str3 pacemaker-controld[5135]: notice: Requesting local execution of probe operation for MariaDB on centos8-str3
Jul 26 13:49:01 centos8-str3 pacemaker-controld[5135]: notice: Result of probe operation for MariaDB on centos8-str3: not running
Jul 26 13:49:01 centos8-str3 pacemaker-controld[5135]: notice: Result of probe operation for DRBD_r0 on centos8-str3: not running
centos8-str3をunstandbyに戻したと時のログを確認します。
[root@centos8-str3 ~]# pcs node unstandby centos8-str3;date
2021年 7月 26日 月曜日 13:51:17 JST
※centos8-str4のログ
Jul 26 13:51:17 centos8-str4 pacemaker-controld[4934]: notice: State transition S_IDLE -> S_POLICY_ENGINE
Jul 26 13:51:17 centos8-str4 pacemaker-schedulerd[4933]: notice: On loss of quorum: Ignore
Jul 26 13:51:17 centos8-str4 pacemaker-schedulerd[4933]: error: DRBD_r0:1 must be colocated with FS_DRBD0 but is not (centos8-str3 vs. centos8-str4)
Jul 26 13:51:17 centos8-str4 pacemaker-schedulerd[4933]: notice: * Start DRBD_r0:1 ( centos8-str3 )
Jul 26 13:51:17 centos8-str4 pacemaker-schedulerd[4933]: notice: Calculated transition 115, saving inputs in /var/lib/pacemaker/pengine/pe-input-3109.bz2
Jul 26 13:51:17 centos8-str4 pacemaker-controld[4934]: notice: Initiating notify operation DRBD_r0_pre_notify_start_0 locally on centos8-str4
Jul 26 13:51:17 centos8-str4 pacemaker-controld[4934]: notice: Requesting local execution of notify operation for DRBD_r0 on centos8-str4
Jul 26 13:51:17 centos8-str4 pacemaker-controld[4934]: notice: Result of notify operation for DRBD_r0 on centos8-str4: ok
Jul 26 13:51:17 centos8-str4 pacemaker-controld[4934]: notice: Initiating start operation DRBD_r0_start_0 on centos8-str3
Jul 26 13:51:18 centos8-str4 pacemaker-attrd[4932]: notice: Setting master-DRBD_r0[centos8-str3]: (unset) -> 10
Jul 26 13:51:18 centos8-str4 pacemaker-controld[4934]: notice: Transition 115 aborted by status-1-master-DRBD_r0 doing create master-DRBD_r0=10: Transient attribute change
Jul 26 13:51:18 centos8-str4 pacemaker-controld[4934]: notice: Initiating notify operation DRBD_r0_post_notify_start_0 locally on centos8-str4
Jul 26 13:51:18 centos8-str4 pacemaker-controld[4934]: notice: Requesting local execution of notify operation for DRBD_r0 on centos8-str4
Jul 26 13:51:18 centos8-str4 pacemaker-controld[4934]: notice: Initiating notify operation DRBD_r0_post_notify_start_0 on centos8-str3
Jul 26 13:51:18 centos8-str4 pacemaker-controld[4934]: notice: Result of notify operation for DRBD_r0 on centos8-str4: ok
Jul 26 13:51:18 centos8-str4 pacemaker-controld[4934]: notice: Transition 115 (Complete=10, Pending=0, Fired=0, Skipped=1, Incomplete=1, Source=/var/lib/pacemaker/pengine/pe-input-3109.bz2): Stopped
Jul 26 13:51:18 centos8-str4 pacemaker-schedulerd[4933]: notice: On loss of quorum: Ignore
Jul 26 13:51:18 centos8-str4 pacemaker-schedulerd[4933]: error: DRBD_r0:1 must be colocated with FS_DRBD0 but is not (centos8-str3 vs. centos8-str4)
Jul 26 13:51:18 centos8-str4 pacemaker-schedulerd[4933]: notice: Calculated transition 116, saving inputs in /var/lib/pacemaker/pengine/pe-input-3110.bz2
Jul 26 13:51:18 centos8-str4 pacemaker-controld[4934]: notice: Initiating monitor operation DRBD_r0_monitor_20000 on centos8-str3
Jul 26 13:51:18 centos8-str4 pacemaker-controld[4934]: notice: Transition 116 (Complete=1, Pending=0, Fired=0, Skipped=0, Incomplete=0, Source=/var/lib/pacemaker/pengine/pe-input-3110.bz2): Complete
Jul 26 13:51:18 centos8-str4 pacemaker-controld[4934]: notice: State transition S_TRANSITION_ENGINE -> S_IDLE
Jul 26 13:51:38 centos8-str4 pacemaker-attrd[4932]: notice: Setting master-DRBD_r0[centos8-str3]: 10 -> 10000
Jul 26 13:51:38 centos8-str4 pacemaker-controld[4934]: notice: State transition S_IDLE -> S_POLICY_ENGINE
Jul 26 13:51:38 centos8-str4 pacemaker-schedulerd[4933]: notice: On loss of quorum: Ignore
Jul 26 13:51:38 centos8-str4 pacemaker-schedulerd[4933]: error: DRBD_r0:1 must be colocated with FS_DRBD0 but is not (centos8-str3 vs. centos8-str4)
Jul 26 13:51:38 centos8-str4 pacemaker-schedulerd[4933]: notice: Calculated transition 117, saving inputs in /var/lib/pacemaker/pengine/pe-input-3111.bz2
Jul 26 13:51:38 centos8-str4 pacemaker-controld[4934]: notice: Transition 117 (Complete=0, Pending=0, Fired=0, Skipped=0, Incomplete=0, Source=/var/lib/pacemaker/pengine/pe-input-3111.bz2): Complete
Jul 26 13:51:38 centos8-str4 pacemaker-controld[4934]: notice: State transition S_TRANSITION_ENGINE -> S_IDLE
※centos8-str3のログ
Jul 26 13:51:17 centos8-str3 pacemaker-controld[5135]: notice: Requesting local execution of start operation for DRBD_r0 on centos8-str3
Jul 26 13:51:18 centos8-str3 pacemaker-attrd[5133]: notice: Setting master-DRBD_r0[centos8-str3]: (unset) -> 10
Jul 26 13:51:18 centos8-str3 pacemaker-controld[5135]: notice: Result of start operation for DRBD_r0 on centos8-str3: ok
Jul 26 13:51:18 centos8-str3 pacemaker-controld[5135]: notice: Requesting local execution of notify operation for DRBD_r0 on centos8-str3
Jul 26 13:51:18 centos8-str3 pacemaker-controld[5135]: notice: Result of notify operation for DRBD_r0 on centos8-str3: ok
Jul 26 13:51:18 centos8-str3 pacemaker-controld[5135]: notice: Requesting local execution of monitor operation for DRBD_r0 on centos8-str3
Jul 26 13:51:18 centos8-str3 pacemaker-controld[5135]: notice: Result of monitor operation for DRBD_r0 on centos8-str3: ok
Jul 26 13:51:38 centos8-str3 pacemaker-attrd[5133]: notice: Setting master-DRBD_r0[centos8-str3]: 10 -> 10000
●Unable to connect to ホスト名
仮想サーバの再起動後、pacemakerを手動スタートしたところ下記のようなエラーが表示されました。# pcs cluster start ホスト名 inu: Unable to connect to ホスト名, try setting higher timeout in \ --request-timeout option (Failed connect to ホスト名:2224; Connection refused) inu: Not starting cluster - node is unreachable Error: unable to start all nodesFirewallの設定に問題が無いか確認しましたが、問題ありませんでした。# firewall-cmd --list-port仮想サーバを再度、再起動することにより問題が解決されました。
●Error: cluster is configured for RRP, you have to specify ring 1 address for the node
新しいnodeの追加時に下記のようなエラーが表示されました。[root@centos7-1 ~]# pcs cluster node add centos7-3 Error: cluster is configured for RRP, you have to specify ring 1 address for the node [root@centos7-1 ~]# pcs cluster start centos7-3 centos7-3: Error connecting to centos7-3 - (HTTP error: 400) Error: unable to start all nodes centos7-3: Error connecting to centos7-3 - (HTTP error: 400)この後、下記コマンドを実行しましたが期待通りに動作しません。[root@centos7-1 ~]# pcs cluster setup --start --name bigbang-cluster1 centos7-1,centos7-1c centos7-2,centos7-2c centos7-3,centos7-3c Error: centos7-1: node is already in a cluster Error: centos7-2: node is already in a cluster Error: nodes availability check failed, use --force to override. WARNING: This will destroy existing cluster on the nodes. \ You should remove the nodes from their clusters instead to keep the clusters working properly.更に下記コマンドを実行しました。[root@centos7-1 ~]# pcs cluster setup --start --name bigbang-cluster1 centos7-1,centos7-1c \ centos7-2,centos7-2c centos7-3,centos7-3c --force Destroying cluster on nodes: centos7-1, centos7-2, centos7-3... centos7-3: Stopping Cluster (pacemaker)... centos7-2: Stopping Cluster (pacemaker)... centos7-1: Stopping Cluster (pacemaker)... centos7-1: Successfully destroyed cluster centos7-2: Successfully destroyed cluster centos7-3: Successfully destroyed cluster Sending 'pacemaker_remote authkey' to 'centos7-1', 'centos7-2', 'centos7-3' centos7-1: successful distribution of the file 'pacemaker_remote authkey' centos7-3: successful distribution of the file 'pacemaker_remote authkey' centos7-2: successful distribution of the file 'pacemaker_remote authkey' Sending cluster config files to the nodes... centos7-1: Succeeded centos7-2: Succeeded centos7-3: Succeeded Starting cluster on nodes: centos7-1, centos7-2, centos7-3... centos7-1: Starting Cluster (corosync)... centos7-2: Starting Cluster (corosync)... centos7-3: Starting Cluster (corosync)... centos7-1: Starting Cluster (pacemaker)... centos7-2: Starting Cluster (pacemaker)... centos7-3: Starting Cluster (pacemaker)... Synchronizing pcsd certificates on nodes centos7-1, centos7-2, centos7-3... centos7-1: Success centos7-3: Success centos7-2: Success Restarting pcsd on the nodes in order to reload the certificates... centos7-1: Success centos7-3: Success centos7-2: Success [root@centos7-1 ~]# corosync-cfgtool -s Printing ring status. Local node ID 1 RING ID 0 id = 10.0.0.25 status = ring 0 active with no faults RING ID 1 id = 192.168.0.11 status = ring 1 active with no faults [root@centos7-1 ~]# pcs property Cluster Properties: cluster-infrastructure: corosync cluster-name: bigbang-cluster1 dc-version: 1.1.19-8.el7_6.4-c3c624ea3d have-watchdog: false--forceオプションを使用することにより3台をclusterとして構成することができました。
しかし、「--force」を付加してクラスタを設定したためこれまでの設定内容が消えてしまいます。
再度リソースを一から設定し直し、3台で正常にclusterとして動作するようになりました。
●a score of -INFINITY for resource
とある作業をするためにリソース(仮想IP)を手動で移動させたところ、下記のようなエラーが出力されました。[root@サーバB ~]# pcs resource move rg01 ・・・① Warning: Creating location constraint cli-ban-rg01-on-<サーバB> with a score of \ -INFINITY for resource rg01 on node <サーバB>. This will prevent rg01 from running on サーバB until the constraint is removed. \ This will be the case even if <サーバB> is the last node in the cluster. ※結論を先に述べると、①の直後に # pcs resource clear rg01 を実行するべきでした。状況を確認します。[root@サーバB ~]# pcs resource show Resource Group: rg01 VirtualIP (ocf::heartbeat:IPaddr2): Started サーバAこの時点では他方のサーバでリソースは正常に動作していました。
作業が終わったのでリソースを戻そうとすると、再度同じエラーメッセージが表示されました。[root@サーバB ~]# pcs resource move rg01 ・・・② Warning: Creating location constraint cli-ban-rg01-on-<サーバB> with a score of \ -INFINITY for resource rg01 on node <サーバB>. This will prevent rg01 from running on サーバB until the constraint is removed. \ This will be the case even if <サーバB> is the last node in the cluster. ※結論を先に述べると、②の実施前(①の実施直後)に # pcs resource clear rg01 を実行するべきでした。すると、リソースが止まってしまっていました(仮想IPが無くなっていた)。[root@サーバB ~]# pcs resource show Resource Group: rg01 VirtualIP (ocf::heartbeat:IPaddr2): Stopped設定状態を確認します。[root@サーバA ~]# pcs config Cluster Name: bigbang Corosync Nodes: サーバA サーバB Pacemaker Nodes: サーバA サーバB Resources: Group: rg01 Resource: VirtualIP (class=ocf provider=heartbeat type=IPaddr2) Attributes: cidr_netmask=24 ip=192.168.0.10 nic=eth1 Operations: monitor interval=30s (VirtualIP-monitor-interval-30s) start interval=0s timeout=20s (VirtualIP-start-interval-0s) stop interval=0s timeout=20s (VirtualIP-stop-interval-0s) Stonith Devices: Fencing Levels: Location Constraints: Resource: VirtualIP Enabled on: サーバB (score:INFINITY) (role: Started) (id:cli-prefer-VirtualIP) Resource: rg01 Enabled on: サーバB (score:INFINITY) (role: Started) (id:cli-prefer-rg01) Disabled on: サーバB (score:-INFINITY) (role: Started) (id:cli-ban-rg01-on-サーバB) Disabled on: サーバA (score:-INFINITY) (role: Started) (id:cli-ban-rg01-on-サーバA) Ordering Constraints: Colocation Constraints: Ticket Constraints: Alerts: No alerts defined Resources Defaults: No defaults set Operations Defaults: No defaults set Cluster Properties: cluster-infrastructure: corosync cluster-name: bigbang dc-version: 1.1.19-8.el7_6.4-c3c624ea3d have-watchdog: false no-quorum-policy: ignore stonith-enabled: false Quorum: Options:下記コマンドを実行し解除しました。[root@サーバA ~]# pcs resource clear rg01 [root@サーバA ~]# pcs resource show Resource Group: rg01 VirtualIP (ocf::heartbeat:IPaddr2): Started サーバBこれで正常な状態に戻りました。
●Failed Resource Actions
下記のように「Failed Resource Actions:」に表示されているとします。[root@centos8-str1 ~]# pcs status Cluster name: bigbang Cluster Summary: * Stack: corosync * Current DC: centos8-str1 (version 2.0.5-8.el8-ba59be7122) - partition with quorum * Last updated: Mon Mar 8 17:10:39 2021 * Last change: Mon Mar 8 17:10:08 2021 by root via crm_resource on centos8-str1 * 2 nodes configured * 6 resource instances configured Node List: * Online: [ centos8-str1 centos8-str2 ] Full List of Resources: * Resource Group: rg01: * VirtualIP (ocf::heartbeat:IPaddr2): Started centos8-str1 * ShareDir (ocf::heartbeat:Filesystem): Started centos8-str1 * MariaDB (systemd:mariadb): Started centos8-str1 * FS_DRBD0 (ocf::heartbeat:Filesystem): Started centos8-str1 * Clone Set: DRBD-clone [DRBD] (promotable): * Masters: [ centos8-str1 ] * Slaves: [ centos8-str2 ] Failed Resource Actions: * FS_DRBD0_start_0 on centos8-str2 'error' (1): call=108, status='complete', \ exitreason='Couldn't mount device [/dev/drbd0] as /mnt2/drdb0', \ last-rc-change='2021-03-08 17:07:34 +09:00', queued=0ms, exec=2632ms Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled下記のように実行すると消すことができます。[root@centos8-str1 ~]# pcs resource cleanup Cleaned up all resources on all nodes Waiting for 1 reply from the controller ... got reply (done) [root@centos8-str1 ~]# pcs status Cluster name: bigbang Cluster Summary: * Stack: corosync * Current DC: centos8-str1 (version 2.0.5-8.el8-ba59be7122) - partition with quorum * Last updated: Mon Mar 8 17:11:58 2021 * Last change: Mon Mar 8 17:11:51 2021 by hacluster via crmd on centos8-str2 * 2 nodes configured * 6 resource instances configured Node List: * Online: [ centos8-str1 centos8-str2 ] Full List of Resources: * Resource Group: rg01: * VirtualIP (ocf::heartbeat:IPaddr2): Started centos8-str1 * ShareDir (ocf::heartbeat:Filesystem): Started centos8-str1 * MariaDB (systemd:mariadb): Started centos8-str1 * FS_DRBD0 (ocf::heartbeat:Filesystem): Started centos8-str1 * Clone Set: DRBD-clone [DRBD] (promotable): * Masters: [ centos8-str1 ] * Slaves: [ centos8-str2 ] Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled
●migration-threshold
参考URL:動かして理解するPacemaker ~CRM設定編~ その1
migration-thresholdはリソースをフェールオーバーするまでの障害の発生回数(failcount)を指定します。デフォルトは無効(INFINITY)となっています。
現在設定されている値は[root@centos8-str1 ~]# pcs config show (省略) Resources Defaults: Meta Attrs: rsc_defaults-meta_attributes migration-threshold=1 (省略)「1回」となっています。つまり、いずれかのリソースで1回でも障害があればフェールオーバーします。
今回は試験として、migration-thresholdの値を「1」から「3」に変更して動作確認してみます。[root@centos8-str1 ~]# pcs resource defaults update migration-threshold=3 Warning: Defaults do not apply to resources which override them with their own defined values [root@centos8-str1 ~]# pcs config show (省略) Resources Defaults: Meta Attrs: rsc_defaults-meta_attributes migration-threshold=3 (省略)「3」に変更されています。クラスタの現在の状態は下記のとおりです。[root@centos8-str1 ~]# pcs status Cluster name: bigbang Cluster Summary: * Stack: corosync * Current DC: centos8-str1 (version 2.0.5-8.el8-ba59be7122) - partition with quorum * Last updated: Fri Aug 27 11:37:56 2021 * Last change: Fri Aug 27 11:28:03 2021 by root via cibadmin on centos8-str1 * 2 nodes configured * 8 resource instances configured Node List: * Online: [ centos8-str1 centos8-str2 ] Full List of Resources: * Clone Set: DRBD_r0-clone [DRBD_r0] (promotable): * Masters: [ centos8-str1 ] * Slaves: [ centos8-str2 ] * Resource Group: zabbix-group: * FS_DRBD0 (ocf::heartbeat:Filesystem): Started centos8-str1 * MariaDB (systemd:mariadb): Started centos8-str1 * httpd (systemd:httpd): Started centos8-str1 * zabbix-server (systemd:zabbix-server): Started centos8-str1 * ShareDir (ocf::heartbeat:Filesystem): Started centos8-str1 * VirtualIP (ocf::heartbeat:IPaddr2): Started centos8-str1 Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled
migration-threshold(フェールオーバー)
それでは、1回目の障害を発生させてみます。[root@centos8-str1 ~]# kill -kill `pgrep -f httpd` [root@centos8-str1 ~]# pcs status [root@centos8-str1 ~]# pcs status --full Cluster name: bigbang Cluster Summary: * Stack: corosync * Current DC: centos8-str1 (1) (version 2.0.5-8.el8-ba59be7122) - partition with quorum * Last updated: Fri Aug 27 14:04:12 2021 * Last change: Fri Aug 27 13:50:20 2021 by root via cibadmin on centos8-str1 * 2 nodes configured * 8 resource instances configured Node List: * Online: [ centos8-str1 (1) centos8-str2 (2) ] Full List of Resources: * Clone Set: DRBD_r0-clone [DRBD_r0] (promotable): * DRBD_r0 (ocf::linbit:drbd): Master centos8-str1 * DRBD_r0 (ocf::linbit:drbd): Slave centos8-str2 * Resource Group: zabbix-group: * FS_DRBD0 (ocf::heartbeat:Filesystem): Started centos8-str1 * MariaDB (systemd:mariadb): Started centos8-str1 * httpd (systemd:httpd): Started centos8-str1 * zabbix-server (systemd:zabbix-server): Started centos8-str1 * ShareDir (ocf::heartbeat:Filesystem): Started centos8-str1 * VirtualIP (ocf::heartbeat:IPaddr2): Started centos8-str1 Node Attributes: * Node: centos8-str1 (1): * master-DRBD_r0 : 10000 * Node: centos8-str2 (2): * master-DRBD_r0 : 10000 Migration Summary: * Node: centos8-str1 (1): * httpd: migration-threshold=3 fail-count=1. last-failure='Fri Aug 27 14:03:58 2021' Failed Resource Actions: * httpd_monitor_60000 on centos8-str1 'not running' (7): call=184, status='complete', exitreason='', \ last-rc-change='2021-08-27 14:03:58 +09:00', queued=0ms, exec=0ms Tickets: PCSD Status: centos8-str1: Online centos8-str2: Online Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabledFailed Resource Actionsに障害が記録されています。
2回目の障害を発生させます。[root@centos8-str1 ~]# kill -kill `pgrep -f httpd` [root@centos8-str1 ~]# pcs status --full Cluster name: bigbang Cluster Summary: * Stack: corosync * Current DC: centos8-str1 (1) (version 2.0.5-8.el8-ba59be7122) - partition with quorum * Last updated: Fri Aug 27 14:06:20 2021 * Last change: Fri Aug 27 13:50:20 2021 by root via cibadmin on centos8-str1 * 2 nodes configured * 8 resource instances configured Node List: * Online: [ centos8-str1 (1) centos8-str2 (2) ] Full List of Resources: * Clone Set: DRBD_r0-clone [DRBD_r0] (promotable): * DRBD_r0 (ocf::linbit:drbd): Master centos8-str1 * DRBD_r0 (ocf::linbit:drbd): Slave centos8-str2 * Resource Group: zabbix-group: * FS_DRBD0 (ocf::heartbeat:Filesystem): Started centos8-str1 * MariaDB (systemd:mariadb): Started centos8-str1 * httpd (systemd:httpd): Started centos8-str1 * zabbix-server (systemd:zabbix-server): Started centos8-str1 * ShareDir (ocf::heartbeat:Filesystem): Started centos8-str1 * VirtualIP (ocf::heartbeat:IPaddr2): Started centos8-str1 Node Attributes: * Node: centos8-str1 (1): * master-DRBD_r0 : 10000 * Node: centos8-str2 (2): * master-DRBD_r0 : 10000 Migration Summary: * Node: centos8-str1 (1): * httpd: migration-threshold=3 fail-count=2 last-failure='Fri Aug 27 14:06:05 2021' Failed Resource Actions: * httpd_monitor_60000 on centos8-str1 'not running' (7): call=202, status='complete', exitreason='', \ last-rc-change='2021-08-27 14:06:05 +09:00', queued=0ms, exec=0ms Tickets: PCSD Status: centos8-str1: Online centos8-str2: Online Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabledfail-count及び障害発生を検知した時刻が更新されています。
3回目の障害を発生させてみます。[root@centos8-str1 ~]# kill -kill `pgrep -f httpd` [root@centos8-str1 ~]# pcs status --full Cluster name: bigbang Cluster Summary: * Stack: corosync * Current DC: centos8-str1 (1) (version 2.0.5-8.el8-ba59be7122) - partition with quorum * Last updated: Fri Aug 27 14:08:31 2021 * Last change: Fri Aug 27 13:50:20 2021 by root via cibadmin on centos8-str1 * 2 nodes configured * 8 resource instances configured Node List: * Online: [ centos8-str1 (1) centos8-str2 (2) ] Full List of Resources: * Clone Set: DRBD_r0-clone [DRBD_r0] (promotable): * DRBD_r0 (ocf::linbit:drbd): Slave centos8-str1 * DRBD_r0 (ocf::linbit:drbd): Master centos8-str2 * Resource Group: zabbix-group: * FS_DRBD0 (ocf::heartbeat:Filesystem): Started centos8-str2 * MariaDB (systemd:mariadb): Started centos8-str2 * httpd (systemd:httpd): Started centos8-str2 * zabbix-server (systemd:zabbix-server): Started centos8-str2 * ShareDir (ocf::heartbeat:Filesystem): Started centos8-str2 * VirtualIP (ocf::heartbeat:IPaddr2): Started centos8-str2 Node Attributes: * Node: centos8-str1 (1): * master-DRBD_r0 : 10000 * Node: centos8-str2 (2): * master-DRBD_r0 : 10000 Migration Summary: * Node: centos8-str1 (1): * httpd: migration-threshold=3 fail-count=3 last-failure='Fri Aug 27 14:08:12 2021' Failed Resource Actions: * httpd_monitor_60000 on centos8-str1 'not running' (7): call=218, status='complete', exitreason='', \ last-rc-change='2021-08-27 14:08:12 +09:00', queued=0ms, exec=0ms Tickets: PCSD Status: centos8-str1: Online centos8-str2: Online Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled障害発生を検知した時刻が更新され、フェールオーバーしていることが分かります。
migration-threshold(フェールバック)
上記のようにリソースのエラーが残っている状態ではフェールバックすることができません。
フェールバックさせるため障害ノードを復旧させ、フェールバックの試験を実施します。[root@centos8-str1 ~]# pcs resource cleanup Cleaned up all resources on all nodes Waiting for 2 replies from the controller ... got reply ... got reply (done) ※1回目の障害(Apache 1回目の障害) [root@centos8-str2 ~]# kill -kill `pgrep -f httpd` [root@centos8-str2 ~]# pcs status --full Cluster name: bigbang Cluster Summary: * Stack: corosync * Current DC: centos8-str1 (1) (version 2.0.5-8.el8-ba59be7122) - partition with quorum * Last updated: Fri Aug 27 14:14:45 2021 * Last change: Fri Aug 27 14:12:41 2021 by hacluster via crmd on centos8-str1 * 2 nodes configured * 8 resource instances configured Node List: * Online: [ centos8-str1 (1) centos8-str2 (2) ] Full List of Resources: * Clone Set: DRBD_r0-clone [DRBD_r0] (promotable): * DRBD_r0 (ocf::linbit:drbd): Slave centos8-str1 * DRBD_r0 (ocf::linbit:drbd): Master centos8-str2 * Resource Group: zabbix-group: * FS_DRBD0 (ocf::heartbeat:Filesystem): Started centos8-str2 * MariaDB (systemd:mariadb): Started centos8-str2 * httpd (systemd:httpd): Started centos8-str2 * zabbix-server (systemd:zabbix-server): Started centos8-str2 * ShareDir (ocf::heartbeat:Filesystem): Started centos8-str2 * VirtualIP (ocf::heartbeat:IPaddr2): Started centos8-str2 Node Attributes: * Node: centos8-str1 (1): * master-DRBD_r0 : 10000 * Node: centos8-str2 (2): * master-DRBD_r0 : 10000 Migration Summary: * Node: centos8-str2 (2): * httpd: migration-threshold=3 fail-count=1 last-failure='Fri Aug 27 14:14:27 2021' Failed Resource Actions: * httpd_monitor_60000 on centos8-str2 'not running' (7): call=197, status='complete', exitreason='', \ last-rc-change='2021-08-27 14:14:27 +09:00', queued=0ms, exec=0ms Tickets: PCSD Status: centos8-str1: Online centos8-str2: Online Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled ※2回目の障害(Zabbix Server 1回目の障害) [root@centos8-str2 ~]# kill -kill `pgrep -f zabbix_server` [root@centos8-str2 ~]# pcs status --full Cluster name: bigbang Cluster Summary: * Stack: corosync * Current DC: centos8-str1 (1) (version 2.0.5-8.el8-ba59be7122) - partition with quorum * Last updated: Fri Aug 27 14:16:45 2021 * Last change: Fri Aug 27 14:12:41 2021 by hacluster via crmd on centos8-str1 * 2 nodes configured * 8 resource instances configured Node List: * Online: [ centos8-str1 (1) centos8-str2 (2) ] Full List of Resources: * Clone Set: DRBD_r0-clone [DRBD_r0] (promotable): * DRBD_r0 (ocf::linbit:drbd): Slave centos8-str1 * DRBD_r0 (ocf::linbit:drbd): Master centos8-str2 * Resource Group: zabbix-group: * FS_DRBD0 (ocf::heartbeat:Filesystem): Started centos8-str2 * MariaDB (systemd:mariadb): Started centos8-str2 * httpd (systemd:httpd): Started centos8-str2 * zabbix-server (systemd:zabbix-server): Started centos8-str2 * ShareDir (ocf::heartbeat:Filesystem): Started centos8-str2 * VirtualIP (ocf::heartbeat:IPaddr2): Started centos8-str2 Node Attributes: * Node: centos8-str1 (1): * master-DRBD_r0 : 10000 * Node: centos8-str2 (2): * master-DRBD_r0 : 10000 Migration Summary: * Node: centos8-str2 (2): * httpd: migration-threshold=3 fail-count=1 last-failure='Fri Aug 27 14:14:27 2021' * zabbix-server: migration-threshold=3 fail-count=1 last-failure='Fri Aug 27 14:16:35 2021' Failed Resource Actions: * httpd_monitor_60000 on centos8-str2 'not running' (7): call=197, status='complete', exitreason='', \ last-rc-change='2021-08-27 14:14:27 +09:00', queued=0ms, exec=0ms * zabbix-server_monitor_60000 on centos8-str2 'not running' (7): call=215, status='complete', exitreason='', \ last-rc-change='2021-08-27 14:16:35 +09:00', queued=0ms, exec=0ms Tickets: PCSD Status: centos8-str1: Online centos8-str2: Online Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled ※3回目の障害(Apache 2回目の障害) [root@centos8-str2 ~]# kill -kill `pgrep -f httpd` [root@centos8-str2 ~]# pcs status --full Cluster name: bigbang Cluster Summary: * Stack: corosync * Current DC: centos8-str1 (1) (version 2.0.5-8.el8-ba59be7122) - partition with quorum * Last updated: Fri Aug 27 14:18:43 2021 * Last change: Fri Aug 27 14:12:41 2021 by hacluster via crmd on centos8-str1 * 2 nodes configured * 8 resource instances configured Node List: * Online: [ centos8-str1 (1) centos8-str2 (2) ] Full List of Resources: * Clone Set: DRBD_r0-clone [DRBD_r0] (promotable): * DRBD_r0 (ocf::linbit:drbd): Slave centos8-str1 * DRBD_r0 (ocf::linbit:drbd): Master centos8-str2 * Resource Group: zabbix-group: * FS_DRBD0 (ocf::heartbeat:Filesystem): Started centos8-str2 * MariaDB (systemd:mariadb): Started centos8-str2 * httpd (systemd:httpd): Started centos8-str2 * zabbix-server (systemd:zabbix-server): Started centos8-str2 * ShareDir (ocf::heartbeat:Filesystem): Started centos8-str2 * VirtualIP (ocf::heartbeat:IPaddr2): Started centos8-str2 Node Attributes: * Node: centos8-str1 (1): * master-DRBD_r0 : 10000 * Node: centos8-str2 (2): * master-DRBD_r0 : 10000 Migration Summary: * Node: centos8-str2 (2): * httpd: migration-threshold=3 fail-count=2 last-failure='Fri Aug 27 14:18:33 2021' * zabbix-server: migration-threshold=3 fail-count=1 last-failure='Fri Aug 27 14:16:35 2021' Failed Resource Actions: * httpd_monitor_60000 on centos8-str2 'not running' (7): call=213, status='complete', exitreason='', \ last-rc-change='2021-08-27 14:18:33 +09:00', queued=0ms, exec=0ms * zabbix-server_monitor_60000 on centos8-str2 'not running' (7): call=215, status='complete', exitreason='', \ last-rc-change='2021-08-27 14:16:35 +09:00', queued=0ms, exec=0ms Tickets: PCSD Status: centos8-str1: Online centos8-str2: Online Daemon Status: corosync: active/disabled pacemaker: active/disabled2回目のApacheの障害のため、障害を検知した時刻が更新されていることが分かります。
4回目の障害(Apache 3回目の障害)を発生させます。[root@centos8-str2 ~]# kill -kill `pgrep -f httpd` [[root@centos8-str2 ~]# pcs status --full Cluster name: bigbang Cluster Summary: * Stack: corosync * Current DC: centos8-str1 (1) (version 2.0.5-8.el8-ba59be7122) - partition with quorum * Last updated: Fri Aug 27 14:20:15 2021 * Last change: Fri Aug 27 14:12:41 2021 by hacluster via crmd on centos8-str1 * 2 nodes configured * 8 resource instances configured Node List: * Online: [ centos8-str1 (1) centos8-str2 (2) ] Full List of Resources: * Clone Set: DRBD_r0-clone [DRBD_r0] (promotable): * DRBD_r0 (ocf::linbit:drbd): Master centos8-str1 * DRBD_r0 (ocf::linbit:drbd): Slave centos8-str2 * Resource Group: zabbix-group: * FS_DRBD0 (ocf::heartbeat:Filesystem): Started centos8-str1 * MariaDB (systemd:mariadb): Started centos8-str1 * httpd (systemd:httpd): Started centos8-str1 * zabbix-server (systemd:zabbix-server): Started centos8-str1 * ShareDir (ocf::heartbeat:Filesystem): Started centos8-str1 * VirtualIP (ocf::heartbeat:IPaddr2): Started centos8-str1 Node Attributes: * Node: centos8-str1 (1): * master-DRBD_r0 : 10000 * Node: centos8-str2 (2): * master-DRBD_r0 : 10000 Migration Summary: * Node: centos8-str2 (2): * httpd: migration-threshold=3 fail-count=3 last-failure='Fri Aug 27 14:19:40 2021' * zabbix-server: migration-threshold=3 fail-count=1 last-failure='Fri Aug 27 14:16:35 2021' Failed Resource Actions: * httpd_monitor_60000 on centos8-str2 'not running' (7): call=241, status='complete', exitreason='', \ last-rc-change='2021-08-27 14:19:40 +09:00', queued=0ms, exec=0ms * zabbix-server_monitor_60000 on centos8-str2 'not running' (7): call=215, status='complete', exitreason='', \ last-rc-change='2021-08-27 14:16:35 +09:00', queued=0ms, exec=0ms Tickets: PCSD Status: centos8-str1: Online centos8-str2: Online Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled同じリソース(Apache)で3回目の障害を検知した時点( migration-threshold=fail-count=3)でフェールバックしていることが分かります。
最後に障害を復旧させておきます。[root@centos8-str2 ~]# pcs resource cleanup Cleaned up all resources on all nodes Waiting for 2 replies from the controller ... got reply ... got reply (done)以上でフェールバックの動作確認は終了です。
●failure-timeout
参考URL:Pacemaker/Corosync の設定値について
failure-timeoutはデフォルトで無効となっています。設定しているリソースで障害を検知するとfailcountがカウントされます。カウントされた障害がその後一定期間障害が発生しなかった場合、failcountを自動的にクリアします。
実際にどのような動きとなるか確認してみます。
ただし、migration-threshold=3は設定済みとします。
failure-timeoutを60秒に設定します。[root@centos8-str1 ~]# pcs resource defaults update failure-timeout=60s Warning: Defaults do not apply to resources which override them with their own defined values [root@centos8-str1 ~]# pcs config show (省略) Resources Defaults: Meta Attrs: rsc_defaults-meta_attributes failure-timeout=60s migration-threshold=3 (省略)failure-timeoutの設定が完了しましたので、Apacheを障害にさせて動作を確認します。[root@centos8-str1 ~]# kill -kill `pgrep -f httpd` ※障害を検知し、fail-countが「1」になっているかの確認 [root@centos8-str1 ~]# pcs status --full Cluster name: bigbang Cluster Summary: * Stack: corosync * Current DC: centos8-str2 (2) (version 2.0.5-8.el8-ba59be7122) - partition with quorum * Last updated: Sat Aug 28 00:14:43 2021 * Last change: Sat Aug 28 00:13:12 2021 by root via cibadmin on centos8-str1 * 2 nodes configured * 8 resource instances configured Node List: * Online: [ centos8-str1 (1) centos8-str2 (2) ] Full List of Resources: * Clone Set: DRBD_r0-clone [DRBD_r0] (promotable): * DRBD_r0 (ocf::linbit:drbd): Slave centos8-str2 * DRBD_r0 (ocf::linbit:drbd): Master centos8-str1 * Resource Group: zabbix-group: * FS_DRBD0 (ocf::heartbeat:Filesystem): Started centos8-str1 * MariaDB (systemd:mariadb): Started centos8-str1 * httpd (systemd:httpd): Started centos8-str1 * zabbix-server (systemd:zabbix-server): Started centos8-str1 * ShareDir (ocf::heartbeat:Filesystem): Started centos8-str1 * VirtualIP (ocf::heartbeat:IPaddr2): Started centos8-str1 Node Attributes: * Node: centos8-str1 (1): * master-DRBD_r0 : 10000 * Node: centos8-str2 (2): * master-DRBD_r0 : 10000 Migration Summary: * Node: centos8-str1 (1): * httpd: migration-threshold=3 fail-count=1 last-failure='Sat Aug 28 00:14:29 2021' Failed Resource Actions: * httpd_monitor_60000 on centos8-str1 'not running' (7): call=40, status='complete', exitreason='', \ last-rc-change='2021-08-28 00:14:29 +09:00', queued=0ms, exec=0ms Tickets: PCSD Status: centos8-str1: Online centos8-str2: Online Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled ※60秒経過後にfail-countがクリアしているかの確認 [root@centos8-str1 ~]# pcs status --full Cluster name: bigbang Cluster Summary: * Stack: corosync * Current DC: centos8-str2 (2) (version 2.0.5-8.el8-ba59be7122) - partition with quorum * Last updated: Sat Aug 28 00:15:32 2021 * Last change: Sat Aug 28 00:13:12 2021 by root via cibadmin on centos8-str1 * 2 nodes configured * 8 resource instances configured Node List: * Online: [ centos8-str1 (1) centos8-str2 (2) ] Full List of Resources: * Clone Set: DRBD_r0-clone [DRBD_r0] (promotable): * DRBD_r0 (ocf::linbit:drbd): Slave centos8-str2 * DRBD_r0 (ocf::linbit:drbd): Master centos8-str1 * Resource Group: zabbix-group: * FS_DRBD0 (ocf::heartbeat:Filesystem): Started centos8-str1 * MariaDB (systemd:mariadb): Started centos8-str1 * httpd (systemd:httpd): Started centos8-str1 * zabbix-server (systemd:zabbix-server): Started centos8-str1 * ShareDir (ocf::heartbeat:Filesystem): Started centos8-str1 * VirtualIP (ocf::heartbeat:IPaddr2): Started centos8-str1 Node Attributes: * Node: centos8-str1 (1): * master-DRBD_r0 : 10000 * Node: centos8-str2 (2): * master-DRBD_r0 : 10000 Migration Summary: Tickets: PCSD Status: centos8-str1: Online centos8-str2: Online Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled想定とおりの動作を確認できました。
●failure-timeout=300s、migration-threshold=3、resource-stickiness=INFINITY設定時の動作確認
AlmaLinux 8.4でfailure-timeout=300s、migration-threshold=3、自動フェールバック無効を設定し、Apacheを3回連続でkillした時の動作です。
プライマリ側でApacheを強制的に停止させます。[root@alma8-1 ~]# kill -kill `pgrep -f httpd`;date 2021年 9月 3日 金曜日 16:55:58 JSTこの時のログ等は下記のとおりです。
Sep 03 16:55:27 alma8-1.bigbang.mydns.jp pacemaker-controld [76332] (process_lrm_event) notice: Result of monitor operation for httpd on alma8-1: not running | rc=7 call=74 key=httpd_monitor_60000 confirmed=false cib-update=76
Sep 03 16:55:27 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_process_request) info: Forwarding cib_modify operation for section status to all (origin=local/crmd/76)
Sep 03 16:55:27 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: --- 0.35.18 2
Sep 03 16:55:27 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: +++ 0.35.19 (null)
Sep 03 16:55:27 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: + /cib: @num_updates=19
Sep 03 16:55:27 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: ++ /cib/status/node_state[@id='1']/lrm[@id='1']/lrm_resources/lrm_resource[@id='httpd']: <lrm_rsc_op id="httpd_last_failure_0" operation_key="httpd_monitor_60000" operation="monitor" crm-debug-origin="do_update_resource" crm_feature_set="3.7.1" transition-key="4:222:0:27160038-9b12-4849-b83b-dc4084c6ceb3" transition-magic="0:7;4:222:0:27160038-9b12-4849-b83b-dc4084c6ceb3" exit-reason="" on_node="alma8-1" call-id
Sep 03 16:55:27 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_process_request) info: Completed cib_modify operation for section status: OK (rc=0, origin=alma8-1/crmd/76, version=0.35.19)
Sep 03 16:55:27 alma8-1.bigbang.mydns.jp pacemaker-attrd [76330] (attrd_peer_update) notice: Setting fail-count-httpd#monitor_60000[alma8-1]: (unset) -> 1 | from alma8-2
Sep 03 16:55:27 alma8-1.bigbang.mydns.jp pacemaker-attrd [76330] (attrd_peer_update) notice: Setting last-failure-httpd#monitor_60000[alma8-1]: (unset) -> 1630655726 | from alma8-2
Sep 03 16:55:27 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: --- 0.35.19 2
Sep 03 16:55:27 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: +++ 0.35.20 (null)
Sep 03 16:55:27 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: + /cib: @num_updates=20
Sep 03 16:55:27 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: ++ /cib/status/node_state[@id='1']/transient_attributes[@id='1']/instance_attributes[@id='status-1']: <nvpair id="status-1-fail-count-httpd.monitor_60000" name="fail-count-httpd#monitor_60000" value="1"/>
Sep 03 16:55:27 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_process_request) info: Completed cib_modify operation for section status: OK (rc=0, origin=alma8-2/attrd/27, version=0.35.20)
Sep 03 16:55:27 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: --- 0.35.20 2
Sep 03 16:55:27 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: +++ 0.35.21 (null)
Sep 03 16:55:27 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: + /cib: @num_updates=21
Sep 03 16:55:27 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: ++ /cib/status/node_state[@id='1']/transient_attributes[@id='1']/instance_attributes[@id='status-1']: <nvpair id="status-1-last-failure-httpd.monitor_60000" name="last-failure-httpd#monitor_60000" value="1630655726"/>
Sep 03 16:55:27 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_process_request) info: Completed cib_modify operation for section status: OK (rc=0, origin=alma8-2/attrd/28, version=0.35.21)
Sep 03 16:55:27 alma8-1.bigbang.mydns.jp pacemaker-execd [76329] (cancel_recurring_action) info: Cancelling systemd operation httpd_status_60000
Sep 03 16:55:27 alma8-1.bigbang.mydns.jp pacemaker-controld [76332] (do_lrm_rsc_op) notice: Requesting local execution of stop operation for httpd on alma8-1 | transition_key=5:227:0:27160038-9b12-4849-b83b-dc4084c6ceb3 op_key=httpd_stop_0
Sep 03 16:55:27 alma8-1.bigbang.mydns.jp pacemaker-execd [76329] (log_execute) info: executing - rsc:httpd action:stop call_id:76
Sep 03 16:55:27 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_process_request) info: Forwarding cib_modify operation for section status to all (origin=local/crmd/77)
Sep 03 16:55:27 alma8-1.bigbang.mydns.jp pacemaker-controld [76332] (process_lrm_event) info: Result of monitor operation for httpd on alma8-1: Cancelled | call=74 key=httpd_monitor_60000 confirmed=true
Sep 03 16:55:27 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: --- 0.35.21 2
Sep 03 16:55:27 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: +++ 0.35.22 (null)
Sep 03 16:55:27 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: + /cib: @num_updates=22
Sep 03 16:55:27 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: + /cib/status/node_state[@id='1']/lrm[@id='1']/lrm_resources/lrm_resource[@id='httpd']/lrm_rsc_op[@id='httpd_last_0']: @operation_key=httpd_stop_0, @operation=stop, @transition-key=5:227:0:27160038-9b12-4849-b83b-dc4084c6ceb3, @transition-magic=-1:193;5:227:0:27160038-9b12-4849-b83b-dc4084c6ceb3, @call-id=-1, @rc-code=193, @op-status=-1, @last-rc-change=1630655727, @last-run=1630655727, @exec-time=0
Sep 03 16:55:27 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_process_request) info: Completed cib_modify operation for section status: OK (rc=0, origin=alma8-1/crmd/77, version=0.35.22)
Sep 03 16:55:27 alma8-1.bigbang.mydns.jp pacemaker-execd [76329] (systemd_exec_result) info: Call to stop passed: /org/freedesktop/systemd1/job/8278
Sep 03 16:55:29 alma8-1.bigbang.mydns.jp pacemaker-controld [76332] (process_lrm_event) notice: Result of stop operation for httpd on alma8-1: ok | rc=0 call=76 key=httpd_stop_0 confirmed=true cib-update=78
Sep 03 16:55:29 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_process_request) info: Forwarding cib_modify operation for section status to all (origin=local/crmd/78)
Sep 03 16:55:29 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: --- 0.35.22 2
Sep 03 16:55:29 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: +++ 0.35.23 (null)
Sep 03 16:55:29 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: + /cib: @num_updates=23
Sep 03 16:55:29 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: + /cib/status/node_state[@id='1']/lrm[@id='1']/lrm_resources/lrm_resource[@id='httpd']/lrm_rsc_op[@id='httpd_last_0']: @transition-magic=0:0;5:227:0:27160038-9b12-4849-b83b-dc4084c6ceb3, @call-id=76, @rc-code=0, @op-status=0, @last-rc-change=1630655729, @last-run=1630655729, @exec-time=2144
Sep 03 16:55:29 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_process_request) info: Completed cib_modify operation for section status: OK (rc=0, origin=alma8-1/crmd/78, version=0.35.23)
Sep 03 16:55:29 alma8-1.bigbang.mydns.jp pacemaker-controld [76332] (do_lrm_rsc_op) notice: Requesting local execution of start operation for httpd on alma8-1 | transition_key=41:227:0:27160038-9b12-4849-b83b-dc4084c6ceb3 op_key=httpd_start_0
Sep 03 16:55:29 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_process_request) info: Forwarding cib_modify operation for section status to all (origin=local/crmd/79)
Sep 03 16:55:29 alma8-1.bigbang.mydns.jp pacemaker-execd [76329] (log_execute) info: executing - rsc:httpd action:start call_id:77
Sep 03 16:55:29 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: --- 0.35.23 2
Sep 03 16:55:29 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: +++ 0.35.24 (null)
Sep 03 16:55:29 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: + /cib: @num_updates=24
Sep 03 16:55:29 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: + /cib/status/node_state[@id='1']/lrm[@id='1']/lrm_resources/lrm_resource[@id='httpd']/lrm_rsc_op[@id='httpd_last_0']: @operation_key=httpd_start_0, @operation=start, @transition-key=41:227:0:27160038-9b12-4849-b83b-dc4084c6ceb3, @transition-magic=-1:193;41:227:0:27160038-9b12-4849-b83b-dc4084c6ceb3, @call-id=-1, @rc-code=193, @op-status=-1, @exec-time=0
Sep 03 16:55:29 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_process_request) info: Completed cib_modify operation for section status: OK (rc=0, origin=alma8-1/crmd/79, version=0.35.24)
Sep 03 16:55:29 alma8-1.bigbang.mydns.jp pacemaker-execd [76329] (systemd_exec_result) info: Call to start passed: /org/freedesktop/systemd1/job/8369
Sep 03 16:55:31 alma8-1.bigbang.mydns.jp pacemaker-controld [76332] (process_lrm_event) notice: Result of start operation for httpd on alma8-1: ok | rc=0 call=77 key=httpd_start_0 confirmed=true cib-update=80
Sep 03 16:55:31 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_process_request) info: Forwarding cib_modify operation for section status to all (origin=local/crmd/80)
Sep 03 16:55:31 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: --- 0.35.24 2
Sep 03 16:55:31 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: +++ 0.35.25 (null)
Sep 03 16:55:31 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: + /cib: @num_updates=25
Sep 03 16:55:31 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: + /cib/status/node_state[@id='1']/lrm[@id='1']/lrm_resources/lrm_resource[@id='httpd']/lrm_rsc_op[@id='httpd_last_0']: @transition-magic=0:0;41:227:0:27160038-9b12-4849-b83b-dc4084c6ceb3, @call-id=77, @rc-code=0, @op-status=0, @last-rc-change=1630655731, @last-run=1630655731, @exec-time=2139
Sep 03 16:55:31 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_process_request) info: Completed cib_modify operation for section status: OK (rc=0, origin=alma8-1/crmd/80, version=0.35.25)
Sep 03 16:55:31 alma8-1.bigbang.mydns.jp pacemaker-controld [76332] (do_lrm_rsc_op) notice: Requesting local execution of monitor operation for httpd on alma8-1 | transition_key=4:227:0:27160038-9b12-4849-b83b-dc4084c6ceb3 op_key=httpd_monitor_60000
Sep 03 16:55:31 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_process_request) info: Forwarding cib_modify operation for section status to all (origin=local/crmd/81)
Sep 03 16:55:31 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: --- 0.35.25 2
Sep 03 16:55:31 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: +++ 0.35.26 (null)
Sep 03 16:55:31 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: + /cib: @num_updates=26
Sep 03 16:55:31 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: + /cib/status/node_state[@id='1']/lrm[@id='1']/lrm_resources/lrm_resource[@id='httpd']/lrm_rsc_op[@id='httpd_monitor_60000']: @transition-key=4:227:0:27160038-9b12-4849-b83b-dc4084c6ceb3, @transition-magic=-1:193;4:227:0:27160038-9b12-4849-b83b-dc4084c6ceb3, @call-id=-1, @rc-code=193, @op-status=-1, @last-rc-change=1630655731
Sep 03 16:55:31 alma8-1.bigbang.mydns.jp pacemaker-controld [76332] (process_lrm_event) notice: Result of monitor operation for httpd on alma8-1: ok | rc=0 call=78 key=httpd_monitor_60000 confirmed=false cib-update=82
Sep 03 16:55:31 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_process_request) info: Completed cib_modify operation for section status: OK (rc=0, origin=alma8-1/crmd/81, version=0.35.26)
Sep 03 16:55:31 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_process_request) info: Forwarding cib_modify operation for section status to all (origin=local/crmd/82)
Sep 03 16:55:31 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: --- 0.35.26 2
Sep 03 16:55:31 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: +++ 0.35.27 (null)
Sep 03 16:55:31 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: + /cib: @num_updates=27
Sep 03 16:55:31 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: + /cib/status/node_state[@id='1']/lrm[@id='1']/lrm_resources/lrm_resource[@id='httpd']/lrm_rsc_op[@id='httpd_monitor_60000']: @transition-magic=0:0;4:227:0:27160038-9b12-4849-b83b-dc4084c6ceb3, @call-id=78, @rc-code=0, @op-status=0
Sep 03 16:55:31 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_process_request) info: Completed cib_modify operation for section status: OK (rc=0, origin=alma8-1/crmd/82, version=0.35.27)
Set r/w permissions for uid=189, gid=189 on /var/log/pacemaker/pacemaker.log
Sep 03 16:55:36 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_process_ping) info: Reporting our current digest to alma8-2: 247e05ed6a0320f0ce8278951e99e981 for 0.35.27 (0x555eb101ba90 0)
[root@alma8-1 ~]# pcs status --full Cluster name: bigbang Cluster Summary: * Stack: corosync * Current DC: alma8-2 (2) (version 2.0.5-9.el8_4.1-ba59be7122) - partition with quorum * Last updated: Fri Sep 3 16:55:53 2021 * Last change: Wed Sep 1 15:22:27 2021 by root via cibadmin on alma8-2 * 2 nodes configured * 5 resource instances configured Node List: * Online: [ alma8-1 (1) alma8-2 (2) ] Full List of Resources: * Clone Set: DRBD_r0-clone [DRBD_r0] (promotable): * DRBD_r0 (ocf::linbit:drbd): Master alma8-1 * DRBD_r0 (ocf::linbit:drbd): Slave alma8-2 * Resource Group: cluster-group: * FS_DRBD0 (ocf::heartbeat:Filesystem): Started alma8-1 * VirtualIP (ocf::heartbeat:IPaddr2): Started alma8-1 * httpd (systemd:httpd): Started alma8-1 Node Attributes: * Node: alma8-1 (1): * master-DRBD_r0 : 10000 * Node: alma8-2 (2): * master-DRBD_r0 : 10000 Migration Summary: * Node: alma8-1 (1): * httpd: migration-threshold=3 fail-count=1 last-failure='Fri Sep 3 16:55:26 2021' Failed Resource Actions: * httpd_monitor_60000 on alma8-1 'not running' (7): call=74, status='complete', exitreason='', \ last-rc-change='2021-09-03 16:55:27 +09:00', queued=0ms, exec=0ms Tickets: PCSD Status: alma8-1: Online alma8-2: Online Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled
プライマリ側でApacheを強制的に停止(2回目)させます。[root@alma8-1 ~]# kill -kill `pgrep -f httpd`;date 2021年 9月 3日 金曜日 16:55:02 JSTこの時のログ等は下記のとおりです。
Sep 03 16:56:31 alma8-1.bigbang.mydns.jp pacemaker-controld [76332] (process_lrm_event) notice: Result of monitor operation for httpd on alma8-1: not running | rc=7 call=78 key=httpd_monitor_60000 confirmed=false cib-update=83
Sep 03 16:56:31 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_process_request) info: Forwarding cib_modify operation for section status to all (origin=local/crmd/83)
Sep 03 16:56:31 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: --- 0.35.27 2
Sep 03 16:56:31 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: +++ 0.35.28 (null)
Sep 03 16:56:31 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: + /cib: @num_updates=28
Sep 03 16:56:31 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: + /cib/status/node_state[@id='1']/lrm[@id='1']/lrm_resources/lrm_resource[@id='httpd']/lrm_rsc_op[@id='httpd_last_failure_0']: @transition-key=4:227:0:27160038-9b12-4849-b83b-dc4084c6ceb3, @transition-magic=0:7;4:227:0:27160038-9b12-4849-b83b-dc4084c6ceb3, @call-id=78, @last-rc-change=1630655791
Sep 03 16:56:31 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_process_request) info: Completed cib_modify operation for section status: OK (rc=0, origin=alma8-1/crmd/83, version=0.35.28)
Sep 03 16:56:31 alma8-1.bigbang.mydns.jp pacemaker-attrd [76330] (attrd_peer_update) notice: Setting fail-count-httpd#monitor_60000[alma8-1]: 1 -> 2 | from alma8-2
Sep 03 16:56:31 alma8-1.bigbang.mydns.jp pacemaker-attrd [76330] (attrd_peer_update) notice: Setting last-failure-httpd#monitor_60000[alma8-1]: 1630655726 -> 1630655791 | from alma8-2
Sep 03 16:56:31 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: --- 0.35.28 2
Sep 03 16:56:31 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: +++ 0.35.29 (null)
Sep 03 16:56:31 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: + /cib: @num_updates=29
Sep 03 16:56:31 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: + /cib/status/node_state[@id='1']/transient_attributes[@id='1']/instance_attributes[@id='status-1']/nvpair[@id='status-1-fail-count-httpd.monitor_60000']: @value=2
Sep 03 16:56:31 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_process_request) info: Completed cib_modify operation for section status: OK (rc=0, origin=alma8-2/attrd/29, version=0.35.29)
Sep 03 16:56:31 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: --- 0.35.29 2
Sep 03 16:56:31 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: +++ 0.35.30 (null)
Sep 03 16:56:31 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: + /cib: @num_updates=30
Sep 03 16:56:31 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: + /cib/status/node_state[@id='1']/transient_attributes[@id='1']/instance_attributes[@id='status-1']/nvpair[@id='status-1-last-failure-httpd.monitor_60000']: @value=1630655791
Sep 03 16:56:31 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_process_request) info: Completed cib_modify operation for section status: OK (rc=0, origin=alma8-2/attrd/30, version=0.35.30)
Sep 03 16:56:31 alma8-1.bigbang.mydns.jp pacemaker-execd [76329] (cancel_recurring_action) info: Cancelling systemd operation httpd_status_60000
Sep 03 16:56:31 alma8-1.bigbang.mydns.jp pacemaker-controld [76332] (do_lrm_rsc_op) notice: Requesting local execution of stop operation for httpd on alma8-1 | transition_key=5:229:0:27160038-9b12-4849-b83b-dc4084c6ceb3 op_key=httpd_stop_0
Sep 03 16:56:31 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_process_request) info: Forwarding cib_modify operation for section status to all (origin=local/crmd/84)
Sep 03 16:56:31 alma8-1.bigbang.mydns.jp pacemaker-execd [76329] (log_execute) info: executing - rsc:httpd action:stop call_id:80
Sep 03 16:56:31 alma8-1.bigbang.mydns.jp pacemaker-controld [76332] (process_lrm_event) info: Result of monitor operation for httpd on alma8-1: Cancelled | call=78 key=httpd_monitor_60000 confirmed=true
Sep 03 16:56:31 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: --- 0.35.30 2
Sep 03 16:56:31 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: +++ 0.35.31 (null)
Sep 03 16:56:31 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: + /cib: @num_updates=31
Sep 03 16:56:31 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: + /cib/status/node_state[@id='1']/lrm[@id='1']/lrm_resources/lrm_resource[@id='httpd']/lrm_rsc_op[@id='httpd_last_0']: @operation_key=httpd_stop_0, @operation=stop, @transition-key=5:229:0:27160038-9b12-4849-b83b-dc4084c6ceb3, @transition-magic=-1:193;5:229:0:27160038-9b12-4849-b83b-dc4084c6ceb3, @call-id=-1, @rc-code=193, @op-status=-1, @last-rc-change=1630655791, @last-run=1630655791, @exec-time=0
Sep 03 16:56:31 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_process_request) info: Completed cib_modify operation for section status: OK (rc=0, origin=alma8-1/crmd/84, version=0.35.31)
Sep 03 16:56:31 alma8-1.bigbang.mydns.jp pacemaker-execd [76329] (systemd_exec_result) info: Call to stop passed: /org/freedesktop/systemd1/job/8550
Sep 03 16:56:33 alma8-1.bigbang.mydns.jp pacemaker-controld [76332] (process_lrm_event) notice: Result of stop operation for httpd on alma8-1: ok | rc=0 call=80 key=httpd_stop_0 confirmed=true cib-update=85
Sep 03 16:56:33 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_process_request) info: Forwarding cib_modify operation for section status to all (origin=local/crmd/85)
Sep 03 16:56:33 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: --- 0.35.31 2
Sep 03 16:56:33 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: +++ 0.35.32 (null)
Sep 03 16:56:33 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: + /cib: @num_updates=32
Sep 03 16:56:33 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: + /cib/status/node_state[@id='1']/lrm[@id='1']/lrm_resources/lrm_resource[@id='httpd']/lrm_rsc_op[@id='httpd_last_0']: @transition-magic=0:0;5:229:0:27160038-9b12-4849-b83b-dc4084c6ceb3, @call-id=80, @rc-code=0, @op-status=0, @last-rc-change=1630655793, @last-run=1630655793, @exec-time=2155
Sep 03 16:56:33 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_process_request) info: Completed cib_modify operation for section status: OK (rc=0, origin=alma8-1/crmd/85, version=0.35.32)
Sep 03 16:56:33 alma8-1.bigbang.mydns.jp pacemaker-controld [76332] (do_lrm_rsc_op) notice: Requesting local execution of start operation for httpd on alma8-1 | transition_key=41:229:0:27160038-9b12-4849-b83b-dc4084c6ceb3 op_key=httpd_start_0
Sep 03 16:56:33 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_process_request) info: Forwarding cib_modify operation for section status to all (origin=local/crmd/86)
Sep 03 16:56:33 alma8-1.bigbang.mydns.jp pacemaker-execd [76329] (log_execute) info: executing - rsc:httpd action:start call_id:81
Sep 03 16:56:33 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: --- 0.35.32 2
Sep 03 16:56:33 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: +++ 0.35.33 (null)
Sep 03 16:56:33 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: + /cib: @num_updates=33
Sep 03 16:56:33 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: + /cib/status/node_state[@id='1']/lrm[@id='1']/lrm_resources/lrm_resource[@id='httpd']/lrm_rsc_op[@id='httpd_last_0']: @operation_key=httpd_start_0, @operation=start, @transition-key=41:229:0:27160038-9b12-4849-b83b-dc4084c6ceb3, @transition-magic=-1:193;41:229:0:27160038-9b12-4849-b83b-dc4084c6ceb3, @call-id=-1, @rc-code=193, @op-status=-1, @exec-time=0
Sep 03 16:56:33 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_process_request) info: Completed cib_modify operation for section status: OK (rc=0, origin=alma8-1/crmd/86, version=0.35.33)
Sep 03 16:56:33 alma8-1.bigbang.mydns.jp pacemaker-execd [76329] (systemd_exec_result) info: Call to start passed: /org/freedesktop/systemd1/job/8641
Set r/w permissions for uid=189, gid=189 on /var/log/pacemaker/pacemaker.log
Sep 03 16:56:35 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_process_request) info: Forwarding cib_modify operation for section status to all (origin=local/crmd/87)
Sep 03 16:56:35 alma8-1.bigbang.mydns.jp pacemaker-controld [76332] (process_lrm_event) notice: Result of start operation for httpd on alma8-1: ok | rc=0 call=81 key=httpd_start_0 confirmed=true cib-update=87
Sep 03 16:56:35 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: --- 0.35.33 2
Sep 03 16:56:35 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: +++ 0.35.34 (null)
Sep 03 16:56:35 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: + /cib: @num_updates=34
Sep 03 16:56:35 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: + /cib/status/node_state[@id='1']/lrm[@id='1']/lrm_resources/lrm_resource[@id='httpd']/lrm_rsc_op[@id='httpd_last_0']: @transition-magic=0:0;41:229:0:27160038-9b12-4849-b83b-dc4084c6ceb3, @call-id=81, @rc-code=0, @op-status=0, @last-rc-change=1630655795, @last-run=1630655795, @exec-time=2151
Sep 03 16:56:35 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_process_request) info: Completed cib_modify operation for section status: OK (rc=0, origin=alma8-1/crmd/87, version=0.35.34)
Sep 03 16:56:35 alma8-1.bigbang.mydns.jp pacemaker-controld [76332] (do_lrm_rsc_op) notice: Requesting local execution of monitor operation for httpd on alma8-1 | transition_key=4:229:0:27160038-9b12-4849-b83b-dc4084c6ceb3 op_key=httpd_monitor_60000
Sep 03 16:56:35 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_process_request) info: Forwarding cib_modify operation for section status to all (origin=local/crmd/88)
Sep 03 16:56:35 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: --- 0.35.34 2
Sep 03 16:56:35 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: +++ 0.35.35 (null)
Sep 03 16:56:35 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: + /cib: @num_updates=35
Sep 03 16:56:35 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: + /cib/status/node_state[@id='1']/lrm[@id='1']/lrm_resources/lrm_resource[@id='httpd']/lrm_rsc_op[@id='httpd_monitor_60000']: @transition-key=4:229:0:27160038-9b12-4849-b83b-dc4084c6ceb3, @transition-magic=-1:193;4:229:0:27160038-9b12-4849-b83b-dc4084c6ceb3, @call-id=-1, @rc-code=193, @op-status=-1, @last-rc-change=1630655795
Sep 03 16:56:35 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_process_request) info: Completed cib_modify operation for section status: OK (rc=0, origin=alma8-1/crmd/88, version=0.35.35)
Sep 03 16:56:35 alma8-1.bigbang.mydns.jp pacemaker-controld [76332] (process_lrm_event) notice: Result of monitor operation for httpd on alma8-1: ok | rc=0 call=82 key=httpd_monitor_60000 confirmed=false cib-update=89
Sep 03 16:56:35 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_process_request) info: Forwarding cib_modify operation for section status to all (origin=local/crmd/89)
Sep 03 16:56:35 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: --- 0.35.35 2
Sep 03 16:56:35 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: +++ 0.35.36 (null)
Sep 03 16:56:35 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: + /cib: @num_updates=36
Sep 03 16:56:35 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: + /cib/status/node_state[@id='1']/lrm[@id='1']/lrm_resources/lrm_resource[@id='httpd']/lrm_rsc_op[@id='httpd_monitor_60000']: @transition-magic=0:0;4:229:0:27160038-9b12-4849-b83b-dc4084c6ceb3, @call-id=82, @rc-code=0, @op-status=0
Sep 03 16:56:35 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_process_request) info: Completed cib_modify operation for section status: OK (rc=0, origin=alma8-1/crmd/89, version=0.35.36)
Sep 03 16:56:40 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_process_ping) info: Reporting our current digest to alma8-2: 00d0950e2ca869cd1f09fd3948f64b87 for 0.35.36 (0x555eb101ba90 0)
[root@alma8-1 ~]# pcs status --full Cluster name: bigbang Cluster Summary: * Stack: corosync * Current DC: alma8-2 (2) (version 2.0.5-9.el8_4.1-ba59be7122) - partition with quorum * Last updated: Fri Sep 3 16:56:40 2021 * Last change: Wed Sep 1 15:22:27 2021 by root via cibadmin on alma8-2 * 2 nodes configured * 5 resource instances configured Node List: * Online: [ alma8-1 (1) alma8-2 (2) ] Full List of Resources: * Clone Set: DRBD_r0-clone [DRBD_r0] (promotable): * DRBD_r0 (ocf::linbit:drbd): Master alma8-1 * DRBD_r0 (ocf::linbit:drbd): Slave alma8-2 * Resource Group: cluster-group: * FS_DRBD0 (ocf::heartbeat:Filesystem): Started alma8-1 * VirtualIP (ocf::heartbeat:IPaddr2): Started alma8-1 * httpd (systemd:httpd): Started alma8-1 Node Attributes: * Node: alma8-1 (1): * master-DRBD_r0 : 10000 * Node: alma8-2 (2): * master-DRBD_r0 : 10000 Migration Summary: * Node: alma8-1 (1): * httpd: migration-threshold=3 fail-count=2 last-failure='Fri Sep 3 16:56:31 2021' Failed Resource Actions: * httpd_monitor_60000 on alma8-1 'not running' (7): call=78, status='complete', exitreason='', \ last-rc-change='2021-09-03 16:56:31 +09:00', queued=0ms, exec=0ms Tickets: PCSD Status: alma8-1: Online alma8-2: Online Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled
プライマリ側でApacheを強制的に停止(3回目)させます。[root@alma8-1 ~]# kill -kill `pgrep -f httpd`;date 2021年 9月 3日 金曜日 16:56:54 JSTこの時のログ等は下記のとおりです。
Sep 03 16:57:35 alma8-1.bigbang.mydns.jp pacemaker-controld [76332] (process_lrm_event) notice: Result of monitor operation for httpd on alma8-1: not running | rc=7 call=82 key=httpd_monitor_60000 confirmed=false cib-update=90
Sep 03 16:57:35 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_process_request) info: Forwarding cib_modify operation for section status to all (origin=local/crmd/90)
Sep 03 16:57:35 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: --- 0.35.36 2
Sep 03 16:57:35 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: +++ 0.35.37 (null)
Sep 03 16:57:35 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: + /cib: @num_updates=37
Sep 03 16:57:35 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: + /cib/status/node_state[@id='1']/lrm[@id='1']/lrm_resources/lrm_resource[@id='httpd']/lrm_rsc_op[@id='httpd_last_failure_0']: @transition-key=4:229:0:27160038-9b12-4849-b83b-dc4084c6ceb3, @transition-magic=0:7;4:229:0:27160038-9b12-4849-b83b-dc4084c6ceb3, @call-id=82, @last-rc-change=1630655855
Sep 03 16:57:35 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_process_request) info: Completed cib_modify operation for section status: OK (rc=0, origin=alma8-1/crmd/90, version=0.35.37)
Sep 03 16:57:35 alma8-1.bigbang.mydns.jp pacemaker-attrd [76330] (attrd_peer_update) notice: Setting fail-count-httpd#monitor_60000[alma8-1]: 2 -> 3 | from alma8-2
Sep 03 16:57:35 alma8-1.bigbang.mydns.jp pacemaker-attrd [76330] (attrd_peer_update) notice: Setting last-failure-httpd#monitor_60000[alma8-1]: 1630655791 -> 1630655855 | from alma8-2
Sep 03 16:57:35 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: --- 0.35.37 2
Sep 03 16:57:35 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: +++ 0.35.38 (null)
Sep 03 16:57:35 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: + /cib: @num_updates=38
Sep 03 16:57:35 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: + /cib/status/node_state[@id='1']/transient_attributes[@id='1']/instance_attributes[@id='status-1']/nvpair[@id='status-1-fail-count-httpd.monitor_60000']: @value=3
Sep 03 16:57:35 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_process_request) info: Completed cib_modify operation for section status: OK (rc=0, origin=alma8-2/attrd/31, version=0.35.38)
Sep 03 16:57:35 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: --- 0.35.38 2\
Sep 03 16:57:35 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: +++ 0.35.39 (null)
Sep 03 16:57:35 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: + /cib: @num_updates=39
Sep 03 16:57:35 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: + /cib/status/node_state[@id='1']/transient_attributes[@id='1']/instance_attributes[@id='status-1']/nvpair[@id='status-1-last-failure-httpd.monitor_60000']: @value=1630655855
Sep 03 16:57:35 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_process_request) info: Completed cib_modify operation for section status: OK (rc=0, origin=alma8-2/attrd/32, version=0.35.39)
Sep 03 16:57:35 alma8-1.bigbang.mydns.jp pacemaker-execd [76329] (cancel_recurring_action) info: Cancelling ocf operation DRBD_r0_monitor_10000
Sep 03 16:57:35 alma8-1.bigbang.mydns.jp pacemaker-controld [76332] (process_lrm_event) info: Result of monitor operation for DRBD_r0 on alma8-1: Cancelled | call=62 key=DRBD_r0_monitor_10000 confirmed=true
Sep 03 16:57:35 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: --- 0.35.39 2
Sep 03 16:57:35 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: +++ 0.35.40 (null)
Sep 03 16:57:35 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: -- /cib/status/node_state[@id='2']/lrm[@id='2']/lrm_resources/lrm_resource[@id='DRBD_r0']/lrm_rsc_op[@id='DRBD_r0_monitor_20000']
Sep 03 16:57:35 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: + /cib: @num_updates=40
Sep 03 16:57:35 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_process_request) info: Completed cib_delete operation for section status: OK (rc=0, origin=alma8-2/crmd/392, version=0.35.40)
Sep 03 16:57:35 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_process_request) info: Forwarding cib_delete operation for section status to all (origin=local/crmd/91)
Sep 03 16:57:35 alma8-1.bigbang.mydns.jp pacemaker-execd [76329] (cancel_recurring_action) info: Cancelling systemd operation httpd_status_60000
Sep 03 16:57:35 alma8-1.bigbang.mydns.jp pacemaker-controld [76332] (do_lrm_rsc_op) notice: Requesting local execution of stop operation for httpd on alma8-1 | transition_key=5:231:0:27160038-9b12-4849-b83b-dc4084c6ceb3 op_key=httpd_stop_0
Sep 03 16:57:35 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: --- 0.35.40 2
Sep 03 16:57:35 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: +++ 0.35.41 (null)
Sep 03 16:57:35 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: -- /cib/status/node_state[@id='1']/lrm[@id='1']/lrm_resources/lrm_resource[@id='DRBD_r0']/lrm_rsc_op[@id='DRBD_r0_monitor_10000']
Sep 03 16:57:35 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: + /cib: @num_updates=41
Sep 03 16:57:35 alma8-1.bigbang.mydns.jp pacemaker-execd [76329] (log_execute) info: executing - rsc:httpd action:stop call_id:85
Sep 03 16:57:35 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_process_request) info: Completed cib_delete operation for section status: OK (rc=0, origin=alma8-1/crmd/91, version=0.35.41)
Sep 03 16:57:35 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_process_request) info: Forwarding cib_modify operation for section status to all (origin=local/crmd/92)
Sep 03 16:57:35 alma8-1.bigbang.mydns.jp pacemaker-controld [76332] (process_lrm_event) info: Result of monitor operation for httpd on alma8-1: Cancelled | call=82 key=httpd_monitor_60000 confirmed=true
Sep 03 16:57:35 alma8-1.bigbang.mydns.jp pacemaker-controld [76332] (do_lrm_rsc_op) notice: Requesting local execution of notify operation for DRBD_r0 on alma8-1 | transition_key=60:231:0:27160038-9b12-4849-b83b-dc4084c6ceb3 op_key=DRBD_r0_notify_0
Sep 03 16:57:35 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: --- 0.35.41 2
Sep 03 16:57:35 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: +++ 0.35.42 (null)
Sep 03 16:57:35 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: + /cib: @num_updates=42
Sep 03 16:57:35 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: + /cib/status/node_state[@id='1']/lrm[@id='1']/lrm_resources/lrm_resource[@id='httpd']/lrm_rsc_op[@id='httpd_last_0']: @operation_key=httpd_stop_0, @operation=stop, @transition-key=5:231:0:27160038-9b12-4849-b83b-dc4084c6ceb3, @transition-magic=-1:193;5:231:0:27160038-9b12-4849-b83b-dc4084c6ceb3, @call-id=-1, @rc-code=193, @op-status=-1, @last-rc-change=1630655855, @last-run=1630655855, @exec-time=0
Sep 03 16:57:35 alma8-1.bigbang.mydns.jp pacemaker-execd [76329] (log_execute) info: executing - rsc:DRBD_r0 action:notify call_id:86
Sep 03 16:57:35 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_process_request) info: Completed cib_modify operation for section status: OK (rc=0, origin=alma8-1/crmd/92, version=0.35.42)
Sep 03 16:57:35 alma8-1.bigbang.mydns.jp pacemaker-execd [76329] (log_finished) info: DRBD_r0 notify (call 86, PID 1296997) exited with status 0 (execution time 36ms, queue time 0ms)
Sep 03 16:57:35 alma8-1.bigbang.mydns.jp pacemaker-controld [76332] (process_lrm_event) notice: Result of notify operation for DRBD_r0 on alma8-1: ok | rc=0 call=86 key=DRBD_r0_notify_0 confirmed=true cib-update=0
Sep 03 16:57:36 alma8-1.bigbang.mydns.jp pacemaker-execd [76329] (systemd_exec_result) info: Call to stop passed: /org/freedesktop/systemd1/job/8822
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-controld [76332] (process_lrm_event) notice: Result of stop operation for httpd on alma8-1: ok | rc=0 call=85 key=httpd_stop_0 confirmed=true cib-update=93
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_process_request) info: Forwarding cib_modify operation for section status to all (origin=local/crmd/93)
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: --- 0.35.42 2
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: +++ 0.35.43 (null)
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: + /cib: @num_updates=43
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: + /cib/status/node_state[@id='1']/lrm[@id='1']/lrm_resources/lrm_resource[@id='httpd']/lrm_rsc_op[@id='httpd_last_0']: @transition-magic=0:0;5:231:0:27160038-9b12-4849-b83b-dc4084c6ceb3, @call-id=85, @rc-code=0, @op-status=0, @last-rc-change=1630655858, @last-run=1630655858, @exec-time=2150
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_process_request) info: Completed cib_modify operation for section status: OK (rc=0, origin=alma8-1/crmd/93, version=0.35.43)
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-execd [76329] (cancel_recurring_action) info: Cancelling ocf operation VirtualIP_monitor_30000
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-controld [76332] (do_lrm_rsc_op) notice: Requesting local execution of stop operation for VirtualIP on alma8-1 | transition_key=42:231:0:27160038-9b12-4849-b83b-dc4084c6ceb3 op_key=VirtualIP_stop_0
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-execd [76329] (log_execute) info: executing - rsc:VirtualIP action:stop call_id:88
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_process_request) info: Forwarding cib_modify operation for section status to all (origin=local/crmd/94)
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-controld [76332] (process_lrm_event) info: Result of monitor operation for VirtualIP on alma8-1: Cancelled | call=66 key=VirtualIP_monitor_30000 confirmed=true
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: --- 0.35.43 2
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: +++ 0.35.44 (null)
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: + /cib: @num_updates=44
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: + /cib/status/node_state[@id='1']/lrm[@id='1']/lrm_resources/lrm_resource[@id='VirtualIP']/lrm_rsc_op[@id='VirtualIP_last_0']: @operation_key=VirtualIP_stop_0, @operation=stop, @transition-key=42:231:0:27160038-9b12-4849-b83b-dc4084c6ceb3, @transition-magic=-1:193;42:231:0:27160038-9b12-4849-b83b-dc4084c6ceb3, @call-id=-1, @rc-code=193, @op-status=-1, @last-rc-change=1630655858, @last-run=1630655858, @exec-time
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_process_request) info: Completed cib_modify operation for section status: OK (rc=0, origin=alma8-1/crmd/94, version=0.35.44)
Sep 03 16:57:38 IPaddr2(VirtualIP)[1297039]: INFO: IP status = ok, IP_CIP=
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-execd [76329] (log_finished) info: VirtualIP stop (call 88, PID 1297039) exited with status 0 (execution time 53ms, queue time 0ms)
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_process_request) info: Forwarding cib_modify operation for section status to all (origin=local/crmd/95)
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-controld [76332] (process_lrm_event) notice: Result of stop operation for VirtualIP on alma8-1: ok | rc=0 call=88 key=VirtualIP_stop_0 confirmed=true cib-update=95
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: --- 0.35.44 2
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: +++ 0.35.45 (null)
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: + /cib: @num_updates=45
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: + /cib/status/node_state[@id='1']/lrm[@id='1']/lrm_resources/lrm_resource[@id='VirtualIP']/lrm_rsc_op[@id='VirtualIP_last_0']: @transition-magic=0:0;42:231:0:27160038-9b12-4849-b83b-dc4084c6ceb3, @call-id=88, @rc-code=0, @op-status=0, @exec-time=53
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_process_request) info: Completed cib_modify operation for section status: OK (rc=0, origin=alma8-1/crmd/95, version=0.35.45)
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-execd [76329] (cancel_recurring_action) info: Cancelling ocf operation FS_DRBD0_monitor_20000
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-controld [76332] (do_lrm_rsc_op) notice: Requesting local execution of stop operation for FS_DRBD0 on alma8-1 | transition_key=39:231:0:27160038-9b12-4849-b83b-dc4084c6ceb3 op_key=FS_DRBD0_stop_0
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_process_request) info: Forwarding cib_modify operation for section status to all (origin=local/crmd/96)
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-execd [76329] (log_execute) info: executing - rsc:FS_DRBD0 action:stop call_id:90
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-controld [76332] (process_lrm_event) info: Result of monitor operation for FS_DRBD0 on alma8-1: Cancelled | call=64 key=FS_DRBD0_monitor_20000 confirmed=true
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: --- 0.35.45 2
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: +++ 0.35.46 (null)
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: + /cib: @num_updates=46
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: + /cib/status/node_state[@id='1']/lrm[@id='1']/lrm_resources/lrm_resource[@id='FS_DRBD0']/lrm_rsc_op[@id='FS_DRBD0_last_0']: @operation_key=FS_DRBD0_stop_0, @operation=stop, @transition-key=39:231:0:27160038-9b12-4849-b83b-dc4084c6ceb3, @transition-magic=-1:193;39:231:0:27160038-9b12-4849-b83b-dc4084c6ceb3, @call-id=-1, @rc-code=193, @op-status=-1, @last-rc-change=1630655858, @last-run=1630655858, @exec-time=0
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_process_request) info: Completed cib_modify operation for section status: OK (rc=0, origin=alma8-1/crmd/96, version=0.35.46)
Sep 03 16:57:38 Filesystem(FS_DRBD0)[1297094]: INFO: Running stop for /dev/drbd0 on /mnt
Sep 03 16:57:38 Filesystem(FS_DRBD0)[1297094]: INFO: Trying to unmount /mnt
Sep 03 16:57:38 Filesystem(FS_DRBD0)[1297094]: INFO: unmounted /mnt successfully
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-execd [76329] (log_finished) info: FS_DRBD0 stop (call 90, PID 1297094) exited with status 0 (execution time 83ms, queue time 0ms)
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-controld [76332] (process_lrm_event) notice: Result of stop operation for FS_DRBD0 on alma8-1: ok | rc=0 call=90 key=FS_DRBD0_stop_0 confirmed=true cib-update=97
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_process_request) info: Forwarding cib_modify operation for section status to all (origin=local/crmd/97)
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: --- 0.35.46 2
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: +++ 0.35.47 (null)
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: + /cib: @num_updates=47
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: + /cib/status/node_state[@id='1']/lrm[@id='1']/lrm_resources/lrm_resource[@id='FS_DRBD0']/lrm_rsc_op[@id='FS_DRBD0_last_0']: @transition-magic=0:0;39:231:0:27160038-9b12-4849-b83b-dc4084c6ceb3, @call-id=90, @rc-code=0, @op-status=0, @exec-time=83
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_process_request) info: Completed cib_modify operation for section status: OK (rc=0, origin=alma8-1/crmd/97, version=0.35.47)
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-controld [76332] (do_lrm_rsc_op) notice: Requesting local execution of demote operation for DRBD_r0 on alma8-1 | transition_key=8:231:0:27160038-9b12-4849-b83b-dc4084c6ceb3 op_key=DRBD_r0_demote_0
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_process_request) info: Forwarding cib_modify operation for section status to all (origin=local/crmd/98)
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: --- 0.35.47 2
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: +++ 0.35.48 (null)
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: + /cib: @num_updates=48
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: + /cib/status/node_state[@id='1']/lrm[@id='1']/lrm_resources/lrm_resource[@id='DRBD_r0']/lrm_rsc_op[@id='DRBD_r0_last_0']: @operation_key=DRBD_r0_demote_0, @operation=demote, @transition-key=8:231:0:27160038-9b12-4849-b83b-dc4084c6ceb3, @transition-magic=-1:193;8:231:0:27160038-9b12-4849-b83b-dc4084c6ceb3, @call-id=-1, @rc-code=193, @op-status=-1, @last-rc-change=1630655858, @last-run=1630655858, @exec-time=0
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_process_request) info: Completed cib_modify operation for section status: OK (rc=0, origin=alma8-1/crmd/98, version=0.35.48)
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-execd [76329] (log_execute) info: executing - rsc:DRBD_r0 action:demote call_id:91
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-execd [76329] (log_finished) info: DRBD_r0 demote (call 91, PID 1297189) exited with status 0 (execution time 39ms, queue time 0ms)
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-controld [76332] (process_lrm_event) notice: Result of demote operation for DRBD_r0 on alma8-1: ok | rc=0 call=91 key=DRBD_r0_demote_0 confirmed=true cib-update=99
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_process_request) info: Forwarding cib_modify operation for section status to all (origin=local/crmd/99)
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: --- 0.35.48 2
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: +++ 0.35.49 (null)
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: + /cib: @num_updates=49
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: + /cib/status/node_state[@id='1']/lrm[@id='1']/lrm_resources/lrm_resource[@id='DRBD_r0']/lrm_rsc_op[@id='DRBD_r0_last_0']: @transition-magic=0:0;8:231:0:27160038-9b12-4849-b83b-dc4084c6ceb3, @call-id=91, @rc-code=0, @op-status=0, @exec-time=39
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_process_request) info: Completed cib_modify operation for section status: OK (rc=0, origin=alma8-1/crmd/99, version=0.35.49)
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-controld [76332] (do_lrm_rsc_op) notice: Requesting local execution of notify operation for DRBD_r0 on alma8-1 | transition_key=61:231:0:27160038-9b12-4849-b83b-dc4084c6ceb3 op_key=DRBD_r0_notify_0
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-execd [76329] (log_execute) info: executing - rsc:DRBD_r0 action:notify call_id:92
Set r/w permissions for uid=189, gid=189 on /var/log/pacemaker/pacemaker.log
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-execd [76329] (log_finished) info: DRBD_r0 notify (call 92, PID 1297218) exited with status 0 (execution time 54ms, queue time 0ms)
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-controld [76332] (process_lrm_event) notice: Result of notify operation for DRBD_r0 on alma8-1: ok | rc=0 call=92 key=DRBD_r0_notify_0 confirmed=true cib-update=0
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-controld [76332] (do_lrm_rsc_op) notice: Requesting local execution of notify operation for DRBD_r0 on alma8-1 | transition_key=56:231:0:27160038-9b12-4849-b83b-dc4084c6ceb3 op_key=DRBD_r0_notify_0
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-execd [76329] (log_execute) info: executing - rsc:DRBD_r0 action:notify call_id:93
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-execd [76329] (log_finished) info: DRBD_r0 notify (call 93, PID 1297246) exited with status 0 (execution time 29ms, queue time 0ms)
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-controld [76332] (process_lrm_event) notice: Result of notify operation for DRBD_r0 on alma8-1: ok | rc=0 call=93 key=DRBD_r0_notify_0 confirmed=true cib-update=0
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: --- 0.35.49 2
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: +++ 0.35.50 (null)
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: + /cib: @num_updates=50
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: + /cib/status/node_state[@id='2']/lrm[@id='2']/lrm_resources/lrm_resource[@id='DRBD_r0']/lrm_rsc_op[@id='DRBD_r0_last_0']: @operation_key=DRBD_r0_promote_0, @operation=promote, @transition-key=13:231:0:27160038-9b12-4849-b83b-dc4084c6ceb3, @transition-magic=-1:193;13:231:0:27160038-9b12-4849-b83b-dc4084c6ceb3, @call-id=-1, @rc-code=193, @op-status=-1, @last-rc-change=1630655858, @last-run=1630655858, @exec-time
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_process_request) info: Completed cib_modify operation for section status: OK (rc=0, origin=alma8-2/crmd/393, version=0.35.50)
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: --- 0.35.50 2
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: +++ 0.35.51 (null)
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: + /cib: @num_updates=51
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: + /cib/status/node_state[@id='2']/lrm[@id='2']/lrm_resources/lrm_resource[@id='DRBD_r0']/lrm_rsc_op[@id='DRBD_r0_last_0']: @transition-magic=0:0;13:231:0:27160038-9b12-4849-b83b-dc4084c6ceb3, @call-id=122, @rc-code=0, @op-status=0, @exec-time=36
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_process_request) info: Completed cib_modify operation for section status: OK (rc=0, origin=alma8-2/crmd/394, version=0.35.51)
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-controld [76332] (do_lrm_rsc_op) notice: Requesting local execution of notify operation for DRBD_r0 on alma8-1 | transition_key=57:231:0:27160038-9b12-4849-b83b-dc4084c6ceb3 op_key=DRBD_r0_notify_0
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-execd [76329] (log_execute) info: executing - rsc:DRBD_r0 action:notify call_id:94
Set r/w permissions for uid=189, gid=189 on /var/log/pacemaker/pacemaker.log
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-execd [76329] (log_finished) info: DRBD_r0 notify (call 94, PID 1297266) exited with status 0 (execution time 50ms, queue time 0ms)
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-controld [76332] (process_lrm_event) notice: Result of notify operation for DRBD_r0 on alma8-1: ok | rc=0 call=94 key=DRBD_r0_notify_0 confirmed=true cib-update=0
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-controld [76332] (do_lrm_rsc_op) notice: Requesting local execution of monitor operation for DRBD_r0 on alma8-1 | transition_key=10:231:0:27160038-9b12-4849-b83b-dc4084c6ceb3 op_key=DRBD_r0_monitor_20000
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: --- 0.35.51 2
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: +++ 0.35.52 (null)
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: + /cib: @num_updates=52
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: + /cib/status/node_state[@id='2']/lrm[@id='2']/lrm_resources/lrm_resource[@id='FS_DRBD0']/lrm_rsc_op[@id='FS_DRBD0_last_0']: @operation_key=FS_DRBD0_start_0, @operation=start, @transition-key=40:231:0:27160038-9b12-4849-b83b-dc4084c6ceb3, @transition-magic=-1:193;40:231:0:27160038-9b12-4849-b83b-dc4084c6ceb3, @call-id=-1, @rc-code=193, @op-status=-1, @last-rc-change=1630655858, @last-run=1630655858, @exec-time=
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_process_request) info: Completed cib_modify operation for section status: OK (rc=0, origin=alma8-2/crmd/395, version=0.35.52)
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: --- 0.35.52 2
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: +++ 0.35.53 (null)
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: + /cib: @num_updates=53
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: + /cib/status/node_state[@id='2']/lrm[@id='2']/lrm_resources/lrm_resource[@id='DRBD_r0']/lrm_rsc_op[@id='DRBD_r0_monitor_10000']: @transition-key=14:231:8:27160038-9b12-4849-b83b-dc4084c6ceb3, @transition-magic=-1:193;14:231:8:27160038-9b12-4849-b83b-dc4084c6ceb3, @call-id=-1, @rc-code=193, @op-status=-1, @last-rc-change=1630655858, @exec-time=0
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_process_request) info: Completed cib_modify operation for section status: OK (rc=0, origin=alma8-2/crmd/396, version=0.35.53)
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_process_request) info: Forwarding cib_modify operation for section status to all (origin=local/crmd/100)
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: --- 0.35.53 2
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: +++ 0.35.54 (null)
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: + /cib: @num_updates=54
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: ++ /cib/status/node_state[@id='1']/lrm[@id='1']/lrm_resources/lrm_resource[@id='DRBD_r0']: <lrm_rsc_op id="DRBD_r0_monitor_20000" operation_key="DRBD_r0_monitor_20000" operation="monitor" crm-debug-origin="do_update_resource" crm_feature_set="3.7.1" transition-key="10:231:0:27160038-9b12-4849-b83b-dc4084c6ceb3" transition-magic="-1:193;10:231:0:27160038-9b12-4849-b83b-dc4084c6ceb3" exit-reason="" on_node="alma8-
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_process_request) info: Completed cib_modify operation for section status: OK (rc=0, origin=alma8-1/crmd/100, version=0.35.54)
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-controld [76332] (process_lrm_event) notice: Result of monitor operation for DRBD_r0 on alma8-1: ok | rc=0 call=95 key=DRBD_r0_monitor_20000 confirmed=false cib-update=101
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_process_request) info: Forwarding cib_modify operation for section status to all (origin=local/crmd/101)
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: --- 0.35.54 2
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: +++ 0.35.55 (null)
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: + /cib: @num_updates=55
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: + /cib/status/node_state[@id='1']/lrm[@id='1']/lrm_resources/lrm_resource[@id='DRBD_r0']/lrm_rsc_op[@id='DRBD_r0_monitor_20000']: @transition-magic=0:0;10:231:0:27160038-9b12-4849-b83b-dc4084c6ceb3, @call-id=95, @rc-code=0, @op-status=0, @exec-time=55
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_process_request) info: Completed cib_modify operation for section status: OK (rc=0, origin=alma8-1/crmd/101, version=0.35.55)
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: --- 0.35.55 2
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: +++ 0.35.56 (null)
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: + /cib: @num_updates=56
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: + /cib/status/node_state[@id='2']/lrm[@id='2']/lrm_resources/lrm_resource[@id='DRBD_r0']/lrm_rsc_op[@id='DRBD_r0_monitor_10000']: @transition-magic=0:8;14:231:8:27160038-9b12-4849-b83b-dc4084c6ceb3, @call-id=125, @rc-code=8, @op-status=0, @exec-time=60
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_process_request) info: Completed cib_modify operation for section status: OK (rc=0, origin=alma8-2/crmd/397, version=0.35.56)
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: --- 0.35.56 2
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: +++ 0.35.57 (null)
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: + /cib: @num_updates=57
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: + /cib/status/node_state[@id='2']/lrm[@id='2']/lrm_resources/lrm_resource[@id='FS_DRBD0']/lrm_rsc_op[@id='FS_DRBD0_last_0']: @transition-magic=0:0;40:231:0:27160038-9b12-4849-b83b-dc4084c6ceb3, @call-id=124, @rc-code=0, @op-status=0, @exec-time=330
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_process_request) info: Completed cib_modify operation for section status: OK (rc=0, origin=alma8-2/crmd/398, version=0.35.57)
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: --- 0.35.57 2
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: +++ 0.35.58 (null)
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: + /cib: @num_updates=58
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: + /cib/status/node_state[@id='2']/lrm[@id='2']/lrm_resources/lrm_resource[@id='FS_DRBD0']/lrm_rsc_op[@id='FS_DRBD0_monitor_20000']: @transition-key=41:231:0:27160038-9b12-4849-b83b-dc4084c6ceb3, @transition-magic=-1:193;41:231:0:27160038-9b12-4849-b83b-dc4084c6ceb3, @call-id=-1, @rc-code=193, @op-status=-1, @last-rc-change=1630655858, @exec-time=0
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_process_request) info: Completed cib_modify operation for section status: OK (rc=0, origin=alma8-2/crmd/399, version=0.35.58)
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: --- 0.35.58 2
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: +++ 0.35.59 (null)
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: + /cib: @num_updates=59
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: + /cib/status/node_state[@id='2']/lrm[@id='2']/lrm_resources/lrm_resource[@id='VirtualIP']/lrm_rsc_op[@id='VirtualIP_last_0']: @operation_key=VirtualIP_start_0, @operation=start, @transition-key=43:231:0:27160038-9b12-4849-b83b-dc4084c6ceb3, @transition-magic=-1:193;43:231:0:27160038-9b12-4849-b83b-dc4084c6ceb3, @call-id=-1, @rc-code=193, @op-status=-1, @last-rc-change=1630655858, @last-run=1630655858, @exec-ti
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_process_request) info: Completed cib_modify operation for section status: OK (rc=0, origin=alma8-2/crmd/400, version=0.35.59)
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: --- 0.35.59 2
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: +++ 0.35.60 (null)
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: + /cib: @num_updates=60
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: + /cib/status/node_state[@id='2']/lrm[@id='2']/lrm_resources/lrm_resource[@id='FS_DRBD0']/lrm_rsc_op[@id='FS_DRBD0_monitor_20000']: @transition-magic=0:0;41:231:0:27160038-9b12-4849-b83b-dc4084c6ceb3, @call-id=126, @rc-code=0, @op-status=0, @exec-time=34
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_process_request) info: Completed cib_modify operation for section status: OK (rc=0, origin=alma8-2/crmd/401, version=0.35.60)
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: --- 0.35.60 2
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: +++ 0.35.61 (null)
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: + /cib: @num_updates=61
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: + /cib/status/node_state[@id='2']/lrm[@id='2']/lrm_resources/lrm_resource[@id='VirtualIP']/lrm_rsc_op[@id='VirtualIP_last_0']: @transition-magic=0:0;43:231:0:27160038-9b12-4849-b83b-dc4084c6ceb3, @call-id=127, @rc-code=0, @op-status=0, @exec-time=59
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_process_request) info: Completed cib_modify operation for section status: OK (rc=0, origin=alma8-2/crmd/402, version=0.35.61)
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: --- 0.35.61 2
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: +++ 0.35.62 (null)
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: + /cib: @num_updates=62
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: + /cib/status/node_state[@id='2']/lrm[@id='2']/lrm_resources/lrm_resource[@id='VirtualIP']/lrm_rsc_op[@id='VirtualIP_monitor_30000']: @transition-key=44:231:0:27160038-9b12-4849-b83b-dc4084c6ceb3, @transition-magic=-1:193;44:231:0:27160038-9b12-4849-b83b-dc4084c6ceb3, @call-id=-1, @rc-code=193, @op-status=-1, @last-rc-change=1630655858, @exec-time=0
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_process_request) info: Completed cib_modify operation for section status: OK (rc=0, origin=alma8-2/crmd/403, version=0.35.62)
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: --- 0.35.62 2
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: +++ 0.35.63 (null)
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: + /cib: @num_updates=63
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: + /cib/status/node_state[@id='2']/lrm[@id='2']/lrm_resources/lrm_resource[@id='httpd']/lrm_rsc_op[@id='httpd_last_0']: @operation_key=httpd_start_0, @operation=start, @transition-key=45:231:0:27160038-9b12-4849-b83b-dc4084c6ceb3, @transition-magic=-1:193;45:231:0:27160038-9b12-4849-b83b-dc4084c6ceb3, @call-id=-1, @rc-code=193, @op-status=-1, @last-rc-change=1630655858, @last-run=1630655858, @exec-time=0
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_process_request) info: Completed cib_modify operation for section status: OK (rc=0, origin=alma8-2/crmd/404, version=0.35.63)
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: --- 0.35.63 2
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: +++ 0.35.64 (null)
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: + /cib: @num_updates=64
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: + /cib/status/node_state[@id='2']/lrm[@id='2']/lrm_resources/lrm_resource[@id='VirtualIP']/lrm_rsc_op[@id='VirtualIP_monitor_30000']: @transition-magic=0:0;44:231:0:27160038-9b12-4849-b83b-dc4084c6ceb3, @call-id=128, @rc-code=0, @op-status=0, @exec-time=68
Sep 03 16:57:38 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_process_request) info: Completed cib_modify operation for section status: OK (rc=0, origin=alma8-2/crmd/405, version=0.35.64)
Sep 03 16:57:40 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: --- 0.35.64 2
Sep 03 16:57:40 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: +++ 0.35.65 (null)
Sep 03 16:57:40 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: + /cib: @num_updates=65
Sep 03 16:57:40 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: + /cib/status/node_state[@id='2']/lrm[@id='2']/lrm_resources/lrm_resource[@id='httpd']/lrm_rsc_op[@id='httpd_last_0']: @transition-magic=0:0;45:231:0:27160038-9b12-4849-b83b-dc4084c6ceb3, @call-id=129, @rc-code=0, @op-status=0, @last-rc-change=1630655860, @last-run=1630655860, @exec-time=2158
Sep 03 16:57:40 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_process_request) info: Completed cib_modify operation for section status: OK (rc=0, origin=alma8-2/crmd/406, version=0.35.65)
Sep 03 16:57:40 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: --- 0.35.65 2
Sep 03 16:57:40 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: +++ 0.35.66 (null)
Sep 03 16:57:40 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: + /cib: @num_updates=66
Sep 03 16:57:40 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: + /cib/status/node_state[@id='2']/lrm[@id='2']/lrm_resources/lrm_resource[@id='httpd']/lrm_rsc_op[@id='httpd_monitor_60000']: @transition-key=46:231:0:27160038-9b12-4849-b83b-dc4084c6ceb3, @transition-magic=-1:193;46:231:0:27160038-9b12-4849-b83b-dc4084c6ceb3, @call-id=-1, @rc-code=193, @op-status=-1, @last-rc-change=1630655860, @exec-time=0
Sep 03 16:57:40 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_process_request) info: Completed cib_modify operation for section status: OK (rc=0, origin=alma8-2/crmd/407, version=0.35.66)
Sep 03 16:57:40 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: --- 0.35.66 2
Sep 03 16:57:40 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: +++ 0.35.67 (null)
Sep 03 16:57:40 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: + /cib: @num_updates=67
Sep 03 16:57:40 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: + /cib/status/node_state[@id='2']/lrm[@id='2']/lrm_resources/lrm_resource[@id='httpd']/lrm_rsc_op[@id='httpd_monitor_60000']: @transition-magic=0:0;46:231:0:27160038-9b12-4849-b83b-dc4084c6ceb3, @call-id=130, @rc-code=0, @op-status=0
Sep 03 16:57:40 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_process_request) info: Completed cib_modify operation for section status: OK (rc=0, origin=alma8-2/crmd/408, version=0.35.67)
Sep 03 16:57:45 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_process_ping) info: Reporting our current digest to alma8-2: 1105e3fe2b6056587b2ab0aaa42d61de for 0.35.67 (0x555eb101ba90 0)
[root@alma8-1 ~]# pcs status --full Cluster name: bigbang Cluster Summary: * Stack: corosync * Current DC: alma8-2 (2) (version 2.0.5-9.el8_4.1-ba59be7122) - partition with quorum * Last updated: Fri Sep 3 16:57:47 2021 * Last change: Wed Sep 1 15:22:27 2021 by root via cibadmin on alma8-2 * 2 nodes configured * 5 resource instances configured Node List: * Online: [ alma8-1 (1) alma8-2 (2) ] Full List of Resources: * Clone Set: DRBD_r0-clone [DRBD_r0] (promotable): * DRBD_r0 (ocf::linbit:drbd): Slave alma8-1 * DRBD_r0 (ocf::linbit:drbd): Master alma8-2 * Resource Group: cluster-group: * FS_DRBD0 (ocf::heartbeat:Filesystem): Started alma8-2 * VirtualIP (ocf::heartbeat:IPaddr2): Started alma8-2 * httpd (systemd:httpd): Started alma8-2 Node Attributes: * Node: alma8-1 (1): * master-DRBD_r0 : 10000 * Node: alma8-2 (2): * master-DRBD_r0 : 10000 Migration Summary: * Node: alma8-1 (1): * httpd: migration-threshold=3 fail-count=3 last-failure='Fri Sep 3 16:57:35 2021' Failed Resource Actions: * httpd_monitor_60000 on alma8-1 'not running' (7): call=82, status='complete', exitreason='', \ last-rc-change='2021-09-03 16:57:35 +09:00', queued=0ms, exec=0ms Tickets: PCSD Status: alma8-1: Online alma8-2: Online Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled
フェールオーバーしていることが分かります。
3回目のApache停止を検知してから5分後のログ等は下記のとおりです。
Sep 03 17:02:36 alma8-1.bigbang.mydns.jp pacemaker-controld [76332] (update_attrd_clear_failures) info: Asking pacemaker-attrd to clear failure of all operations for httpd on cluster node alma8-1
Sep 03 17:02:36 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_process_request) info: Forwarding cib_delete operation for section /cib/status/node_state[@uname='alma8-1']/lrm/lrm_resources/lrm_resource[@id='httpd']/lrm_rsc_op[@id='httpd_last_failure_0'] to all (origin=local/crmd/102)
Sep 03 17:02:36 alma8-1.bigbang.mydns.jp pacemaker-attrd [76330] (attrd_peer_update) notice: Setting last-failure-httpd#monitor_60000[alma8-1]: 1630655855 -> (unset) | from alma8-1
Sep 03 17:02:36 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: --- 0.35.67 2
Sep 03 17:02:36 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: +++ 0.35.68 3c5e25909f4e2f5958b08492a959b4ba
Sep 03 17:02:36 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: -- /cib/status/node_state[@id='1']/lrm[@id='1']/lrm_resources/lrm_resource[@id='httpd']/lrm_rsc_op[@id='httpd_last_failure_0']
Sep 03 17:02:36 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: + /cib: @num_updates=68
Sep 03 17:02:36 alma8-1.bigbang.mydns.jp pacemaker-attrd [76330] (attrd_peer_update) notice: Setting fail-count-httpd#monitor_60000[alma8-1]: 3 -> (unset) | from alma8-1
Sep 03 17:02:36 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_process_request) info: Completed cib_delete operation for section /cib/status/node_state[@uname='alma8-1']/lrm/lrm_resources/lrm_resource[@id='httpd']/lrm_rsc_op[@id='httpd_last_failure_0']: OK (rc=0, origin=alma8-1/crmd/102, version=0.35.68)
Sep 03 17:02:36 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: --- 0.35.68 2
Sep 03 17:02:36 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: +++ 0.35.69 (null)
Sep 03 17:02:36 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: -- /cib/status/node_state[@id='1']/transient_attributes[@id='1']/instance_attributes[@id='status-1']/nvpair[@id='status-1-last-failure-httpd.monitor_60000']
Sep 03 17:02:36 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: + /cib: @num_updates=69
Sep 03 17:02:36 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_process_request) info: Completed cib_modify operation for section status: OK (rc=0, origin=alma8-2/attrd/33, version=0.35.69)
Sep 03 17:02:36 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: --- 0.35.69 2
Sep 03 17:02:36 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: Diff: +++ 0.35.70 (null)
Sep 03 17:02:36 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: -- /cib/status/node_state[@id='1']/transient_attributes[@id='1']/instance_attributes[@id='status-1']/nvpair[@id='status-1-fail-count-httpd.monitor_60000']
Sep 03 17:02:36 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_perform_op) info: + /cib: @num_updates=70
Sep 03 17:02:36 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_process_request) info: Completed cib_modify operation for section status: OK (rc=0, origin=alma8-2/attrd/34, version=0.35.70)
Set r/w permissions for uid=189, gid=189 on /var/log/pacemaker/pacemaker.log
Sep 03 17:02:41 alma8-1.bigbang.mydns.jp pacemaker-based [76327] (cib_process_ping) info: Reporting our current digest to alma8-2: d35ca42149a0332073beb28291b1c47f for 0.35.70 (0x555eb0b35a80 0)
[root@alma8-1 ~]# pcs status --full Cluster name: bigbang Cluster Summary: * Stack: corosync * Current DC: alma8-2 (2) (version 2.0.5-9.el8_4.1-ba59be7122) - partition with quorum * Last updated: Fri Sep 3 17:03:32 2021 * Last change: Wed Sep 1 15:22:27 2021 by root via cibadmin on alma8-2 * 2 nodes configured * 5 resource instances configured Node List: * Online: [ alma8-1 (1) alma8-2 (2) ] Full List of Resources: * Clone Set: DRBD_r0-clone [DRBD_r0] (promotable): * DRBD_r0 (ocf::linbit:drbd): Slave alma8-1 * DRBD_r0 (ocf::linbit:drbd): Master alma8-2 * Resource Group: cluster-group: * FS_DRBD0 (ocf::heartbeat:Filesystem): Started alma8-2 * VirtualIP (ocf::heartbeat:IPaddr2): Started alma8-2 * httpd (systemd:httpd): Started alma8-2 Node Attributes: * Node: alma8-1 (1): * master-DRBD_r0 : 10000 * Node: alma8-2 (2): * master-DRBD_r0 : 10000 Migration Summary: Tickets: PCSD Status: alma8-1: Online alma8-2: Online Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled
Migration Summary及びFailed Resource Actionsの障害記録が無くなり、回復していることが分かります。